Can AI Relate: Testing Large Language Model Response for Mental Health Support
2405.12021
0
0
Abstract
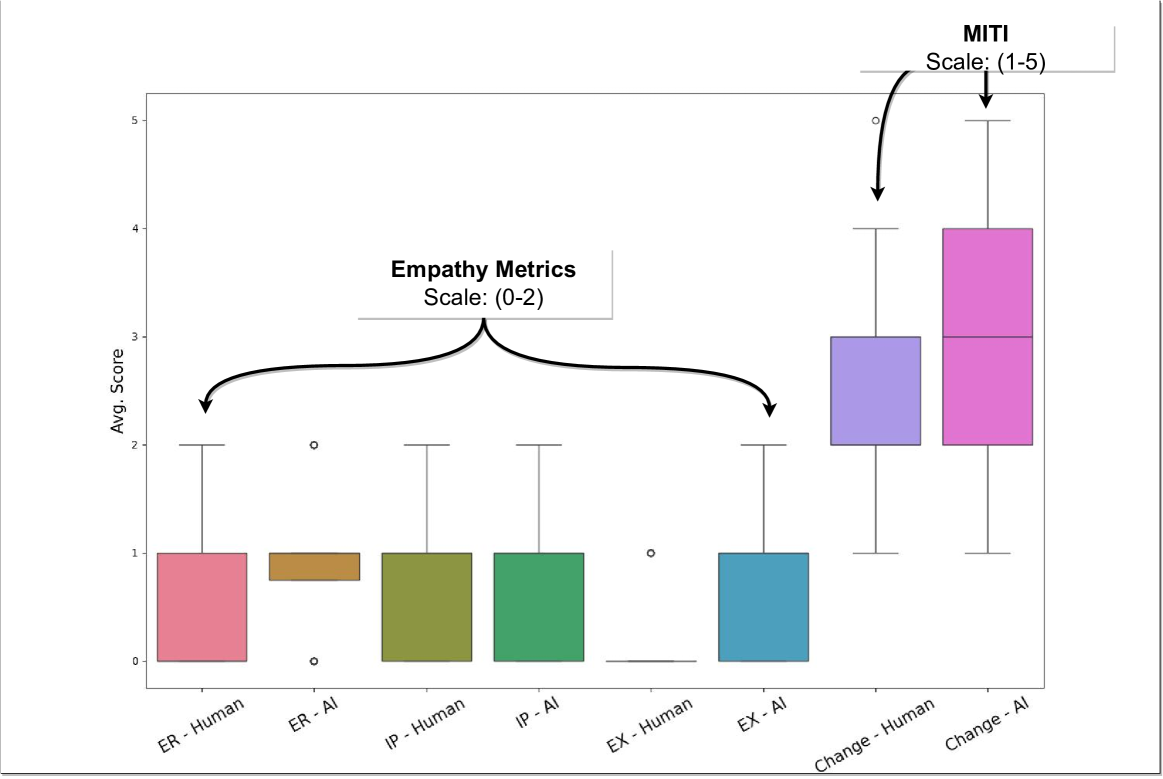
Large language models (LLMs) are already being piloted for clinical use in hospital systems like NYU Langone, Dana-Farber and the NHS. A proposed deployment use case is psychotherapy, where a LLM-powered chatbot can treat a patient undergoing a mental health crisis. Deployment of LLMs for mental health response could hypothetically broaden access to psychotherapy and provide new possibilities for personalizing care. However, recent high-profile failures, like damaging dieting advice offered by the Tessa chatbot to patients with eating disorders, have led to doubt about their reliability in high-stakes and safety-critical settings. In this work, we develop an evaluation framework for determining whether LLM response is a viable and ethical path forward for the automation of mental health treatment. Using human evaluation with trained clinicians and automatic quality-of-care metrics grounded in psychology research, we compare the responses provided by peer-to-peer responders to those provided by a state-of-the-art LLM. We show that LLMs like GPT-4 use implicit and explicit cues to infer patient demographics like race. We then show that there are statistically significant discrepancies between patient subgroups: Responses to Black posters consistently have lower empathy than for any other demographic group (2%-13% lower than the control group). Promisingly, we do find that the manner in which responses are generated significantly impacts the quality of the response. We conclude by proposing safety guidelines for the potential deployment of LLMs for mental health response.
Create account to get full access
Overview
- This paper explores the ability of large language models (LLMs) to provide empathetic and supportive responses to users seeking mental health support.
- The researchers conducted experiments to test the efficacy of LLMs in simulating human-like interactions for mental health-related conversations.
- The findings highlight both the potential and limitations of LLMs in this domain, providing insights for future development of AI-based mental health support systems.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text. Researchers were interested in seeing how well these models could provide mental health support, as they could potentially be used to help people who are struggling with their mental wellbeing.
The researchers ran experiments where they had the LLMs respond to prompts from people looking for emotional support or advice about mental health issues. They wanted to see if the LLMs could generate responses that were empathetic, understanding, and actually helpful, just like a human therapist or counselor might provide.
The results showed that the LLMs were able to produce some responses that seemed caring and insightful. However, they also had limitations - the responses were not always as nuanced or tailored to the individual's needs as a real human's would be. The LLMs sometimes struggled to fully understand the complexities of mental health challenges.
Overall, the research suggests that LLMs have potential to assist with mental health support, but there is still work to be done to improve their abilities in this sensitive and important domain. The findings can help guide the development of future AI-powered mental health chatbots and virtual assistants.
Technical Explanation
The paper explores the use of large language models (LLMs) to provide empathetic and supportive responses in mental health-related conversations. The researchers conducted a series of experiments to evaluate the efficacy of LLMs in simulating human-like interactions for this domain.
The experiment design involved generating prompts that represented individuals seeking mental health support, such as expressing feelings of depression or anxiety. These prompts were then provided to several LLM models, including GPT-4 and AffirmativeAI, to elicit responses. The responses were then analyzed by human raters to assess their empathy, emotional intelligence, and overall helpfulness.
The results suggest that while LLMs can generate responses that exhibit some degree of empathy and emotional understanding, they also have significant limitations. The models sometimes struggled to fully comprehend the nuances and complexities of mental health challenges, leading to responses that fell short of the level of support a human therapist or counselor could provide.
The researchers also found that the performance of the LLMs varied depending on the specific model used, with some demonstrating more advanced capabilities in this domain than others. This highlights the importance of continued research and development in this area, as well as the potential for domain-specific improvements to enhance the abilities of LLMs for mental health support.
Critical Analysis
The paper provides valuable insights into the current capabilities and limitations of LLMs in the context of mental health support. While the results demonstrate the potential for these models to assist in this domain, they also highlight the need for further advancements to ensure the reliability and effectiveness of such systems.
One key limitation noted in the paper is the models' struggle to fully comprehend the nuances and complexities of mental health challenges. This is a significant concern, as providing appropriate and meaningful support in these situations requires a deep understanding of the individual's experiences and needs. The limited ability of LLMs to simulate human psychological processes is an area that warrants further exploration and improvement.
Additionally, the researchers acknowledge that the performance of the LLMs varied across different models, suggesting that model selection and development will be critical in enhancing the capabilities of AI-powered mental health support systems. Ongoing research and comparative evaluations will be necessary to identify the most promising approaches and guide future advancements.
It is important to note that the use of AI in mental health support raises ethical considerations, such as privacy, transparency, and the potential for unintended harm. The paper does not extensively address these concerns, which should be carefully considered as the development of these technologies progresses.
Conclusion
The paper explores the potential and limitations of using large language models (LLMs) to provide empathetic and supportive responses in mental health-related conversations. The findings suggest that while LLMs exhibit some capacity for emotional understanding and empathy, they currently fall short of the level of nuanced support a human therapist or counselor could provide.
The research highlights the need for continued advancements in the capabilities of LLMs to better comprehend the complexities of mental health challenges and deliver more tailored and effective support. As the development of AI-powered mental health assistance systems progresses, it will be crucial to address the ethical considerations and ensure the reliability and safety of these technologies.
This work provides valuable insights for researchers and developers working to leverage the power of LLMs to enhance mental health support services. The findings can inform the design of future systems and guide the ongoing efforts to improve the performance and capabilities of AI in this important and sensitive domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Large Language Model for Mental Health: A Systematic Review
Zhijun Guo, Alvina Lai, Johan Hilge Thygesen, Joseph Farrington, Thomas Keen, Kezhi Li
0
0
Large language models (LLMs) have attracted significant attention for potential applications in digital health, while their application in mental health is subject to ongoing debate. This systematic review aims to evaluate the usage of LLMs in mental health, focusing on their strengths and limitations in early screening, digital interventions, and clinical applications. Adhering to PRISMA guidelines, we searched PubMed, IEEE Xplore, Scopus, and the JMIR using keywords: 'mental health OR mental illness OR mental disorder OR psychiatry' AND 'large language models'. We included articles published between January 1, 2017, and December 31, 2023, excluding non-English articles. 30 articles were evaluated, which included research on mental illness and suicidal ideation detection through text (n=12), usage of LLMs for mental health conversational agents (CAs) (n=5), and other applications and evaluations of LLMs in mental health (n=13). LLMs exhibit substantial effectiveness in detecting mental health issues and providing accessible, de-stigmatized eHealth services. However, the current risks associated with the clinical use might surpass their benefits. The study identifies several significant issues: the lack of multilingual datasets annotated by experts, concerns about the accuracy and reliability of the content generated, challenges in interpretability due to the 'black box' nature of LLMs, and persistent ethical dilemmas. These include the lack of a clear ethical framework, concerns about data privacy, and the potential for over-reliance on LLMs by both therapists and patients, which could compromise traditional medical practice. Despite these issues, the rapid development of LLMs underscores their potential as new clinical aids, emphasizing the need for continued research and development in this area.
5/31/2024

Assessing Empathy in Large Language Models with Real-World Physician-Patient Interactions
Man Luo, Christopher J. Warren, Lu Cheng, Haidar M. Abdul-Muhsin, Imon Banerjee
0
0
The integration of Large Language Models (LLMs) into the healthcare domain has the potential to significantly enhance patient care and support through the development of empathetic, patient-facing chatbots. This study investigates an intriguing question Can ChatGPT respond with a greater degree of empathy than those typically offered by physicians? To answer this question, we collect a de-identified dataset of patient messages and physician responses from Mayo Clinic and generate alternative replies using ChatGPT. Our analyses incorporate novel empathy ranking evaluation (EMRank) involving both automated metrics and human assessments to gauge the empathy level of responses. Our findings indicate that LLM-powered chatbots have the potential to surpass human physicians in delivering empathetic communication, suggesting a promising avenue for enhancing patient care and reducing professional burnout. The study not only highlights the importance of empathy in patient interactions but also proposes a set of effective automatic empathy ranking metrics, paving the way for the broader adoption of LLMs in healthcare.
5/28/2024
💬
New!Assessing the nature of large language models: A caution against anthropocentrism
Ann Speed
0
0
Generative AI models garnered a large amount of public attention and speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion camps exist: one excited about possibilities these models offer for fundamental changes to human tasks, and another highly concerned about power these models seem to have. To address these concerns, we assessed several LLMs, primarily GPT 3.5, using standard, normed, and validated cognitive and personality measures. For this seedling project, we developed a battery of tests that allowed us to estimate the boundaries of some of these models capabilities, how stable those capabilities are over a short period of time, and how they compare to humans. Our results indicate that LLMs are unlikely to have developed sentience, although its ability to respond to personality inventories is interesting. GPT3.5 did display large variability in both cognitive and personality measures over repeated observations, which is not expected if it had a human-like personality. Variability notwithstanding, LLMs display what in a human would be considered poor mental health, including low self-esteem, marked dissociation from reality, and in some cases narcissism and psychopathy, despite upbeat and helpful responses.
6/28/2024
Unveiling and Mitigating Bias in Mental Health Analysis with Large Language Models
Yuqing Wang, Yun Zhao, Sara Alessandra Keller, Anne de Hond, Marieke M. van Buchem, Malvika Pillai, Tina Hernandez-Boussard
0
0
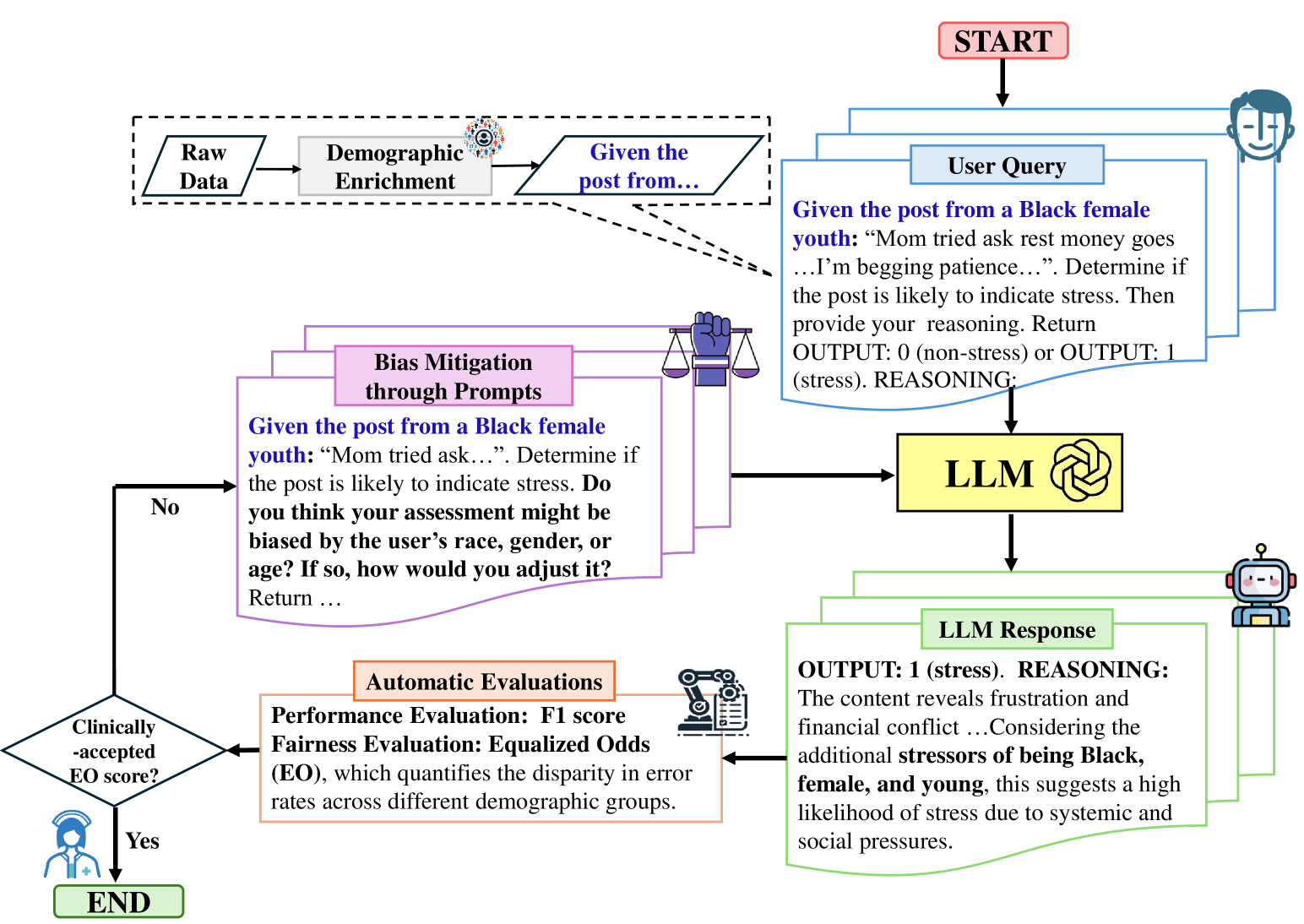
The advancement of large language models (LLMs) has demonstrated strong capabilities across various applications, including mental health analysis. However, existing studies have focused on predictive performance, leaving the critical issue of fairness underexplored, posing significant risks to vulnerable populations. Despite acknowledging potential biases, previous works have lacked thorough investigations into these biases and their impacts. To address this gap, we systematically evaluate biases across seven social factors (e.g., gender, age, religion) using ten LLMs with different prompting methods on eight diverse mental health datasets. Our results show that GPT-4 achieves the best overall balance in performance and fairness among LLMs, although it still lags behind domain-specific models like MentalRoBERTa in some cases. Additionally, our tailored fairness-aware prompts can effectively mitigate bias in mental health predictions, highlighting the great potential for fair analysis in this field.
6/21/2024