Weakly-supervised Audio Separation via Bi-modal Semantic Similarity
2404.01740
0
0
Abstract
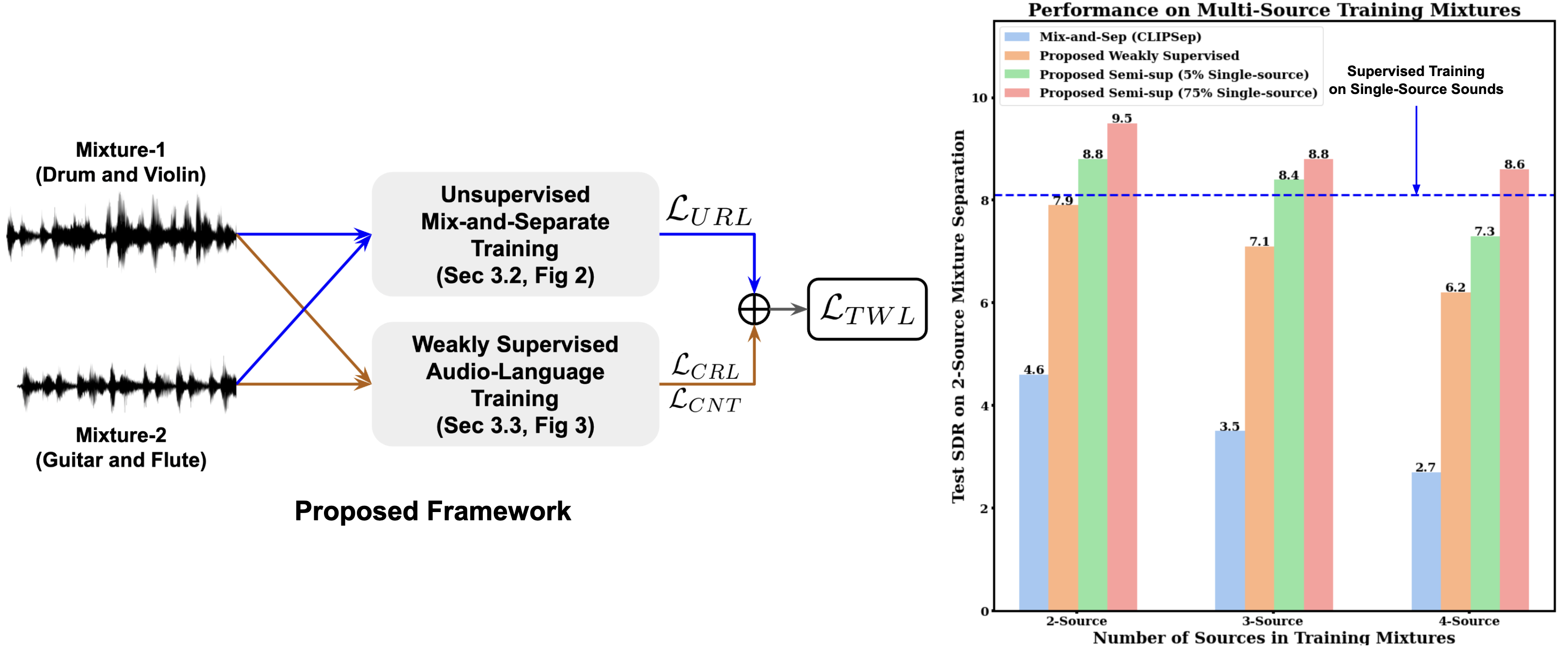
Conditional sound separation in multi-source audio mixtures without having access to single source sound data during training is a long standing challenge. Existing mix-and-separate based methods suffer from significant performance drop with multi-source training mixtures due to the lack of supervision signal for single source separation cases during training. However, in the case of language-conditional audio separation, we do have access to corresponding text descriptions for each audio mixture in our training data, which can be seen as (rough) representations of the audio samples in the language modality. To this end, in this paper, we propose a generic bi-modal separation framework which can enhance the existing unsupervised frameworks to separate single-source signals in a target modality (i.e., audio) using the easily separable corresponding signals in the conditioning modality (i.e., language), without having access to single-source samples in the target modality during training. We empirically show that this is well within reach if we have access to a pretrained joint embedding model between the two modalities (i.e., CLAP). Furthermore, we propose to incorporate our framework into two fundamental scenarios to enhance separation performance. First, we show that our proposed methodology significantly improves the performance of purely unsupervised baselines by reducing the distribution shift between training and test samples. In particular, we show that our framework can achieve 71% boost in terms of Signal-to-Distortion Ratio (SDR) over the baseline, reaching 97.5% of the supervised learning performance. Second, we show that we can further improve the performance of the supervised learning itself by 17% if we augment it by our proposed weakly-supervised framework, that enables a powerful semi-supervised framework for audio separation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a method for separating audio signals into their individual components using weak supervision, meaning the system is trained without needing fully labeled training data.
- The key idea is to use semantic similarity between visual and audio data to guide the audio separation process, rather than relying on traditional fully-supervised approaches.
- The authors demonstrate that their approach can effectively separate audio signals into sources like speech, music, and environmental sounds without requiring detailed annotations of the training data.
Plain English Explanation
The goal of this research is to find a way to separate different sounds in an audio recording, like speech, music, and background noises, without having detailed information about what each sound is. Normally, training a system to do this kind of audio separation requires lots of labeled training data where each sound is carefully annotated. However, collecting that kind of detailed data can be very time-consuming and expensive.
The key insight in this paper is that we can use the semantic similarity between visual and audio data to guide the audio separation, rather than relying only on the audio data itself. For example, if we see an image of a person speaking, we can use that visual information to help identify the speech component in the corresponding audio recording. Similarly, images of musical instruments or environments can provide cues to separate those audio elements.
By leveraging this cross-modal semantic connection between visual and audio data, the authors show they can train an effective audio separation system using only weakly-labeled training data - for example, just knowing that an audio clip contains speech, music, and environmental sounds, without precise timestamps or boundaries for each component. This makes the training process much more efficient and practical compared to fully-supervised approaches.
Technical Explanation
The core of the authors' approach is a bi-modal neural network that learns to map both visual and audio data into a shared semantic embedding space. This allows the network to exploit the semantic connections between what is seen and what is heard in order to separate the audio into distinct sources.
The network has two main components - a visual encoder that processes image inputs, and an audio encoder that processes audio spectrograms. Both encoders produce embeddings that are then fed into a separation module, which learns to isolate the individual audio sources.
The key innovation is that the audio separation is guided by the bi-modal similarity between the visual and audio embeddings. Sounds that are semantically associated with the visual inputs (e.g. speech with a face, music with instruments) will be grouped together, while unrelated sounds will be separated out.
The authors evaluate their method on standard audio separation benchmarks and show it can achieve competitive performance compared to fully-supervised approaches, while only requiring weakly-labeled training data. They also demonstrate qualitative examples of the separated audio sources aligning well with the semantic cues from the visual inputs.
Critical Analysis
A strength of this work is that it provides an effective way to perform audio separation without the need for detailed, per-sound annotations in the training data. This makes the approach much more scalable and practical compared to traditional fully-supervised techniques.
However, a potential limitation is that the method still relies on having access to aligned visual-audio data during training. In many real-world scenarios, this type of cross-modal data may not be readily available. The authors note that future work could explore ways to learn the audio-visual associations in a more unsupervised manner.
Additionally, the paper does not provide a deep analysis of the types of audio mixtures and visual inputs that the method works best on. Further exploration of the limitations and failure cases could help identify areas for future improvements.
Overall, this work demonstrates a promising new direction for audio separation that leverages semantic connections between modalities. With further refinements, the approach could become a valuable tool for applications like audio editing, automatic video captioning, and auditory scene analysis.
Conclusion
This paper presents a novel method for separating audio signals into their individual components using weak supervision. By learning to map visual and audio data into a shared semantic space, the system can exploit cross-modal associations to guide the audio separation, without requiring detailed per-sound annotations in the training data.
The authors show this approach can achieve competitive performance on standard audio separation benchmarks, making it a promising alternative to traditional fully-supervised techniques. While the method still relies on having access to aligned visual-audio data, the ability to train with weaker supervision is an important step towards more scalable and practical audio source separation.
Overall, this research demonstrates the power of leveraging cross-modal information to tackle complex auditory processing tasks. As audio-visual data becomes increasingly ubiquitous, techniques like this could have significant impact on a wide range of applications in multimedia, robotics, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
0
0
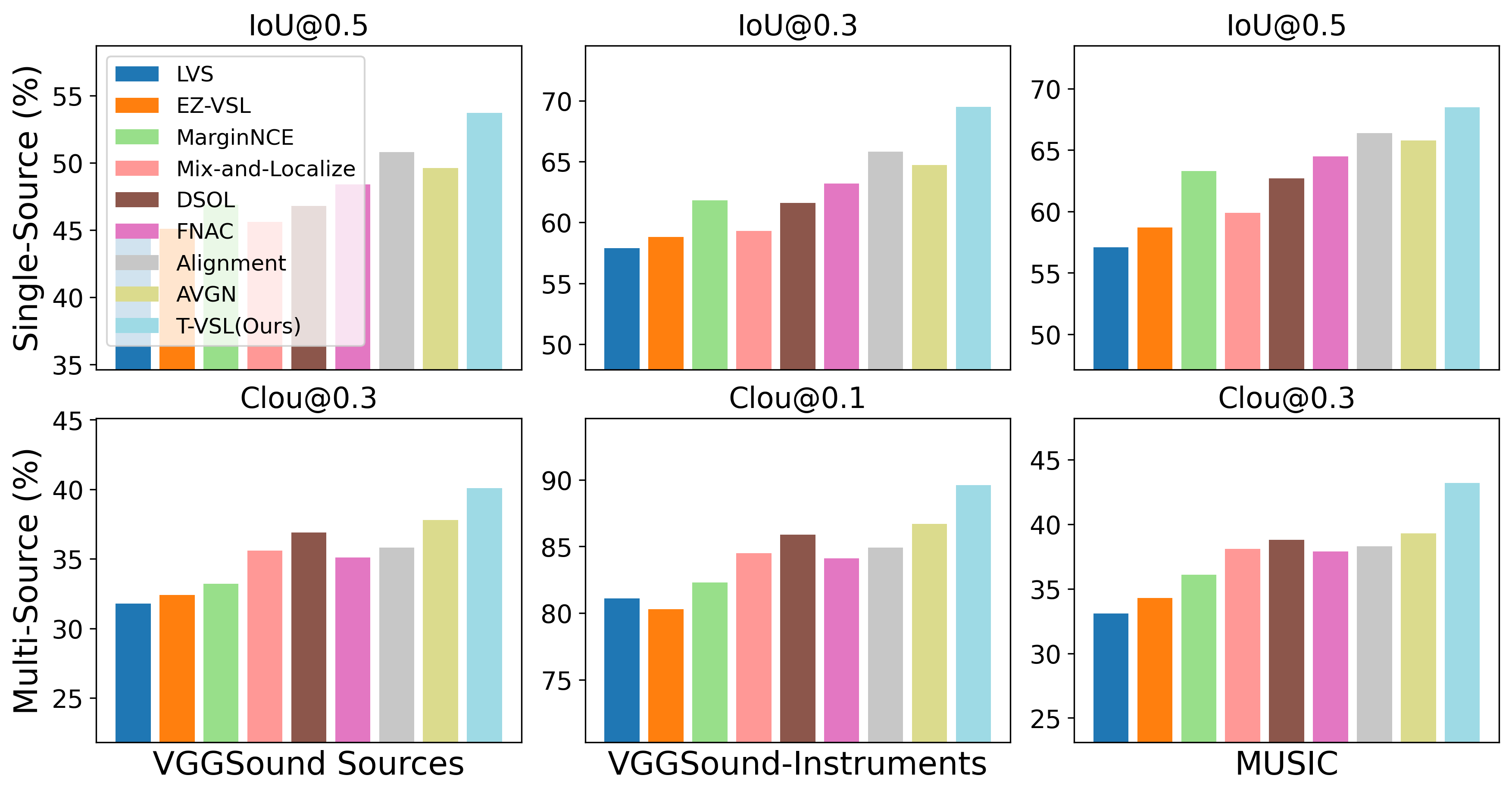
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods.
4/3/2024
Separate in the Speech Chain: Cross-Modal Conditional Audio-Visual Target Speech Extraction
Zhaoxi Mu, Xinyu Yang
0
0
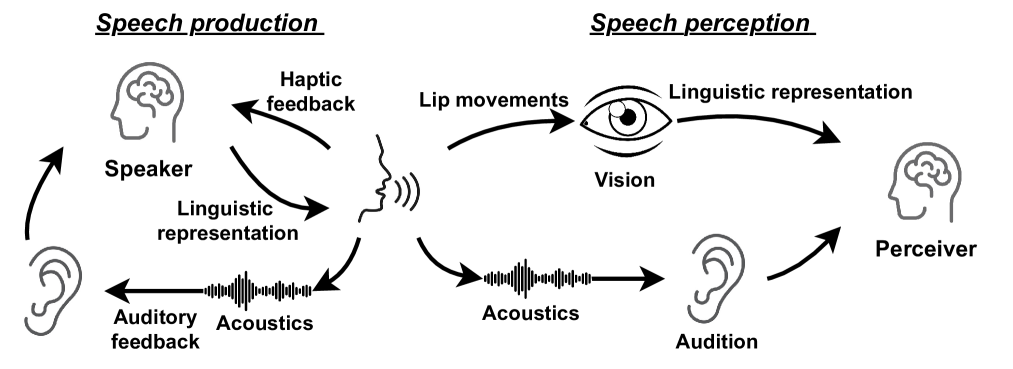
The integration of visual cues has revitalized the performance of the target speech extraction task, elevating it to the forefront of the field. Nevertheless, this multi-modal learning paradigm often encounters the challenge of modality imbalance. In audio-visual target speech extraction tasks, the audio modality tends to dominate, potentially overshadowing the importance of visual guidance. To tackle this issue, we propose AVSepChain, drawing inspiration from the speech chain concept. Our approach partitions the audio-visual target speech extraction task into two stages: speech perception and speech production. In the speech perception stage, audio serves as the dominant modality, while visual information acts as the conditional modality. Conversely, in the speech production stage, the roles are reversed. This transformation of modality status aims to alleviate the problem of modality imbalance. Additionally, we introduce a contrastive semantic matching loss to ensure that the semantic information conveyed by the generated speech aligns with the semantic information conveyed by lip movements during the speech production stage. Through extensive experiments conducted on multiple benchmark datasets for audio-visual target speech extraction, we showcase the superior performance achieved by our proposed method.
5/7/2024
CLAPSep: Leveraging Contrastive Pre-trained Model for Multi-Modal Query-Conditioned Target Sound Extraction
Hao Ma, Zhiyuan Peng, Xu Li, Mingjie Shao, Xixin Wu, Ju Liu
0
0
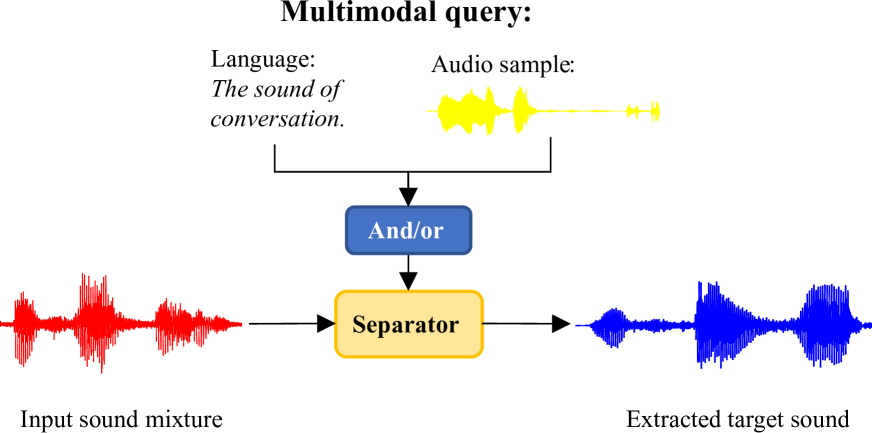
Universal sound separation (USS) aims to extract arbitrary types of sounds from real-world recordings. This can be achieved by language-queried target sound extraction (TSE), which typically consists of two components: a query network that converts user queries into conditional embeddings, and a separation network that extracts the target sound accordingly. Existing methods commonly train models from scratch. As a consequence, substantial data and computational resources are required to improve the models' performance and generalizability. In this paper, we propose to integrate pre-trained models into TSE models to address the above issue. To be specific, we tailor and adapt the powerful contrastive language-audio pre-trained model (CLAP) for USS, denoted as CLAPSep. CLAPSep also accepts flexible user inputs, taking both positive and negative user prompts of uni- and/or multi-modalities for target sound extraction. These key features of CLAPSep can not only enhance the extraction performance but also improve the versatility of its application. We provide extensive experiments on 5 diverse datasets to demonstrate the superior performance and zero- and few-shot generalizability of our proposed CLAPSep with fast training convergence, surpassing previous methods by a significant margin. Full codes and some audio examples are released for reproduction and evaluation.
5/9/2024
Unified Video-Language Pre-training with Synchronized Audio
Shentong Mo, Haofan Wang, Huaxia Li, Xu Tang
0
0
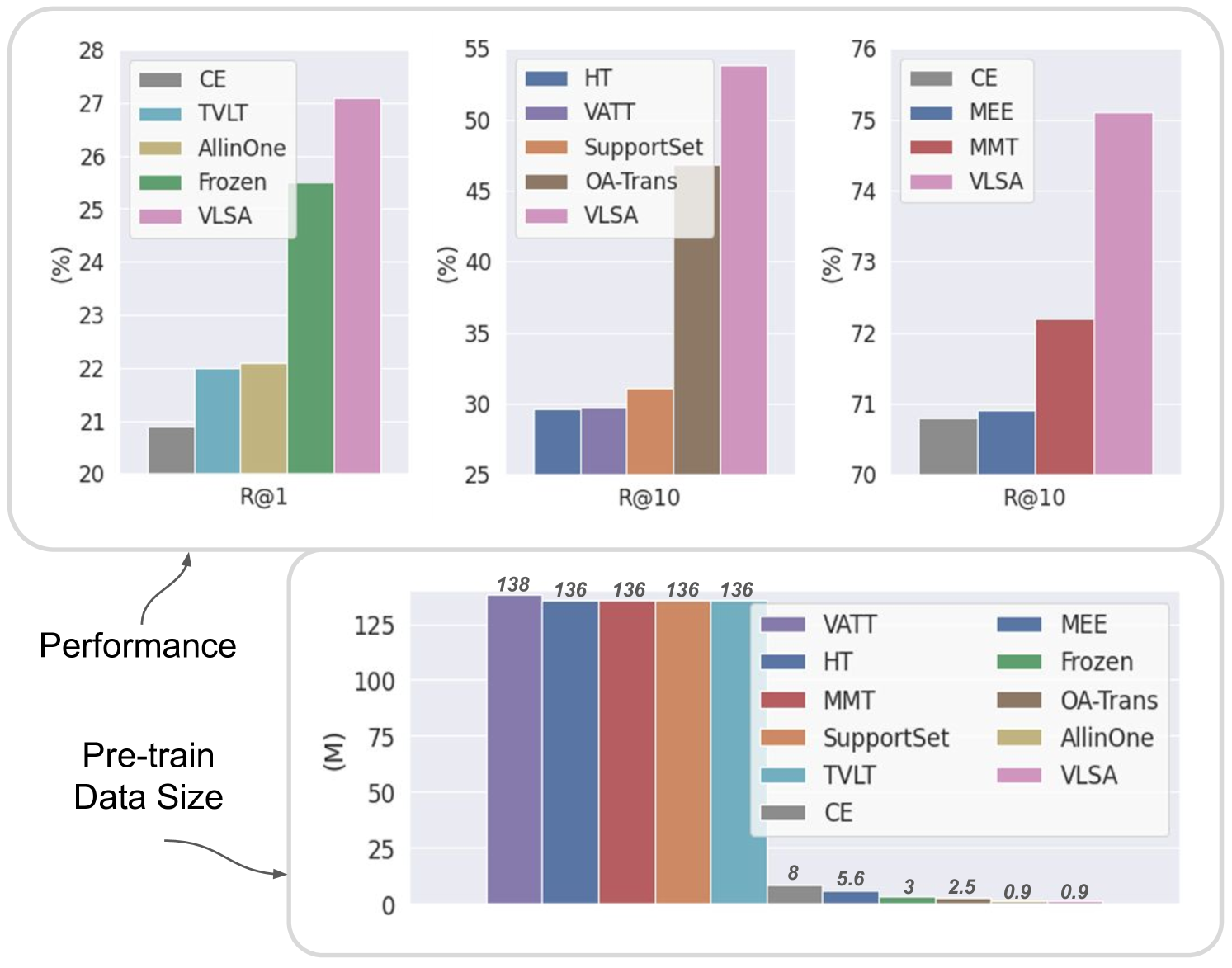
Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
5/14/2024