On the weight dynamics of learning networks
2405.00743
0
0
Abstract
Neural networks have become a widely adopted tool for tackling a variety of problems in machine learning and artificial intelligence. In this contribution we use the mathematical framework of local stability analysis to gain a deeper understanding of the learning dynamics of feed forward neural networks. Therefore, we derive equations for the tangent operator of the learning dynamics of three-layer networks learning regression tasks. The results are valid for an arbitrary numbers of nodes and arbitrary choices of activation functions. Applying the results to a network learning a regression task, we investigate numerically, how stability indicators relate to the final training-loss. Although the specific results vary with different choices of initial conditions and activation functions, we demonstrate that it is possible to predict the final training loss, by monitoring finite-time Lyapunov exponents or covariant Lyapunov vectors during the training process.
Create account to get full access
Overview
- This paper explores the dynamics of the weights in learning networks, such as artificial neural networks.
- The authors develop a mathematical model to analyze the weight dynamics and derive analytical expressions for the weight evolution.
- The model provides insights into the stability and chaos in neural network trajectories, which is relevant for learning stable passive neural differential equations and learning stable dynamic systems with Lyapunov energy functions.
Plain English Explanation
The paper investigates how the connection weights, or parameters, in a learning network like an artificial neural network change and evolve over time during the training process. The researchers created a mathematical model to describe this weight dynamics, which allows them to analyze the stability and chaotic behavior of the network's behavior, as it learns.
This is an important topic because understanding the weight dynamics can provide insights into how to train neural networks to be more stable and predictable, rather than exhibiting complex, unpredictable behavior. Stable weight dynamics are crucial for applications where the network needs to behave in a reliable, consistent way, such as in controlling dynamic systems with neural networks.
By deriving analytical expressions for how the weights change over time, the authors aim to give researchers a better theoretical understanding of the underlying processes governing neural network training and performance.
Technical Explanation
The paper develops a mathematical model to describe the weight dynamics in learning networks, such as artificial neural networks. The model takes into account the network architecture, learning rule, and input data distribution to derive analytical expressions for how the connection weights evolve over time during training.
The authors show that the weight dynamics exhibit both stable and chaotic behavior, depending on the specific parameters of the network and learning process. This aligns with prior research on the dynamical stability and chaos in neural network trajectories and the complex network dynamics underlying neural predictions.
By understanding these weight dynamics, the researchers aim to provide a theoretical foundation for techniques that learn stable, passive neural differential equations and dynamic systems with Lyapunov energy functions. This could lead to more reliable and predictable neural network behavior, which is crucial for safety-critical applications.
Critical Analysis
The paper provides a comprehensive theoretical analysis of weight dynamics in learning networks, deriving analytical expressions that offer insights into the stability and chaotic behavior of neural networks during training. However, the model relies on several simplifying assumptions, such as linear activation functions and Gaussian input distributions, which may limit the generalizability of the results to more complex, nonlinear neural network architectures and real-world datasets.
Additionally, the analysis focuses on the weight dynamics in isolation, without considering the impact of other factors, such as the network's loss function, optimization algorithm, and hyperparameters. These elements can also significantly influence the stability and convergence of the learning process, and should be considered for a more holistic understanding of neural network behavior.
Further research is needed to explore the weight dynamics in more realistic, nonlinear neural network models, as well as to investigate the interplay between weight dynamics, network architecture, and learning algorithms. This could lead to the development of more robust techniques for learning stable, dynamic systems with Lyapunov energy functions, which are crucial for real-world applications of neural networks.
Conclusion
This paper presents a theoretical analysis of the weight dynamics in learning networks, such as artificial neural networks. The authors develop a mathematical model to derive analytical expressions for how the connection weights evolve over time during the training process. Their analysis reveals both stable and chaotic behavior in the weight dynamics, which has important implications for techniques that aim to learn stable, passive neural differential equations and dynamic systems with Lyapunov energy functions.
While the model relies on some simplifying assumptions, the insights provided by this work contribute to a deeper understanding of the underlying processes governing neural network training and performance. Further research is needed to explore the weight dynamics in more realistic, nonlinear neural network models and to investigate the interplay between weight dynamics, network architecture, and learning algorithms.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
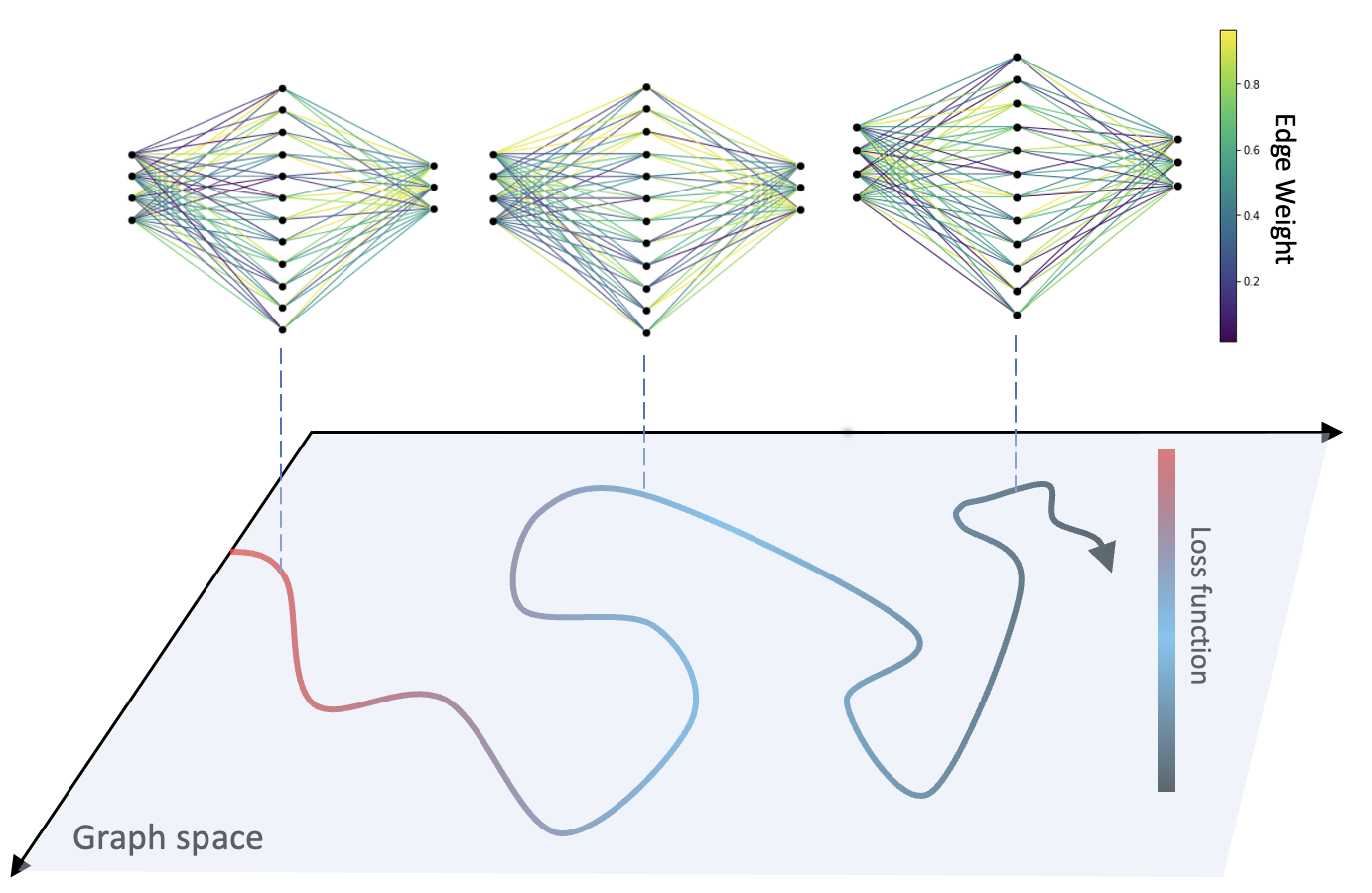
Dynamical stability and chaos in artificial neural network trajectories along training
Kaloyan Danovski, Miguel C. Soriano, Lucas Lacasa
0
0
The process of training an artificial neural network involves iteratively adapting its parameters so as to minimize the error of the network's prediction, when confronted with a learning task. This iterative change can be naturally interpreted as a trajectory in network space -- a time series of networks -- and thus the training algorithm (e.g. gradient descent optimization of a suitable loss function) can be interpreted as a dynamical system in graph space. In order to illustrate this interpretation, here we study the dynamical properties of this process by analyzing through this lens the network trajectories of a shallow neural network, and its evolution through learning a simple classification task. We systematically consider different ranges of the learning rate and explore both the dynamical and orbital stability of the resulting network trajectories, finding hints of regular and chaotic behavior depending on the learning rate regime. Our findings are put in contrast to common wisdom on convergence properties of neural networks and dynamical systems theory. This work also contributes to the cross-fertilization of ideas between dynamical systems theory, network theory and machine learning
4/10/2024

On instabilities in neural network-based physics simulators
Daniel Floryan
0
0
When neural networks are trained from data to simulate the dynamics of physical systems, they encounter a persistent challenge: the long-time dynamics they produce are often unphysical or unstable. We analyze the origin of such instabilities when learning linear dynamical systems, focusing on the training dynamics. We make several analytical findings which empirical observations suggest extend to nonlinear dynamical systems. First, the rate of convergence of the training dynamics is uneven and depends on the distribution of energy in the data. As a special case, the dynamics in directions where the data have no energy cannot be learned. Second, in the unlearnable directions, the dynamics produced by the neural network depend on the weight initialization, and common weight initialization schemes can produce unstable dynamics. Third, injecting synthetic noise into the data during training adds damping to the training dynamics and can stabilize the learned simulator, though doing so undesirably biases the learned dynamics. For each contributor to instability, we suggest mitigative strategies. We also highlight important differences between learning discrete-time and continuous-time dynamics, and discuss extensions to nonlinear systems.
6/21/2024
🧠
Stretched and measured neural predictions of complex network dynamics
Vaiva Vasiliauskaite, Nino Antulov-Fantulin
0
0
Differential equations are a ubiquitous tool to study dynamics, ranging from physical systems to complex systems, where a large number of agents interact through a graph with non-trivial topological features. Data-driven approximations of differential equations present a promising alternative to traditional methods for uncovering a model of dynamical systems, especially in complex systems that lack explicit first principles. A recently employed machine learning tool for studying dynamics is neural networks, which can be used for data-driven solution finding or discovery of differential equations. Specifically for the latter task, however, deploying deep learning models in unfamiliar settings - such as predicting dynamics in unobserved state space regions or on novel graphs - can lead to spurious results. Focusing on complex systems whose dynamics are described with a system of first-order differential equations coupled through a graph, we show that extending the model's generalizability beyond traditional statistical learning theory limits is feasible. However, achieving this advanced level of generalization requires neural network models to conform to fundamental assumptions about the dynamical model. Additionally, we propose a statistical significance test to assess prediction quality during inference, enabling the identification of a neural network's confidence level in its predictions.
4/26/2024

Weight fluctuations in (deep) linear neural networks and a derivation of the inverse-variance flatness relation
Markus Gross, Arne P. Raulf, Christoph Rath
0
0
We investigate the stationary (late-time) training regime of single- and two-layer underparameterized linear neural networks within the continuum limit of stochastic gradient descent (SGD) for synthetic Gaussian data. In the case of a single-layer network in the weakly underparameterized regime, the spectrum of the noise covariance matrix deviates notably from the Hessian, which can be attributed to the broken detailed balance of SGD dynamics. The weight fluctuations are in this case generally anisotropic, but effectively experience an isotropic loss. For an underparameterized two-layer network, we describe the stochastic dynamics of the weights in each layer and analyze the associated stationary covariances. We identify the inter-layer coupling as a distinct source of anisotropy for the weight fluctuations. In contrast to the single-layer case, the weight fluctuations are effectively subject to an anisotropic loss, the flatness of which is inversely related to the fluctuation variance. We thereby provide an analytical derivation of the recently observed inverse variance-flatness relation in a model of a deep linear neural network.
6/26/2024