What if you said that differently?: How Explanation Formats Affect Human Feedback Efficacy and User Perception
2311.09558
0
0
📊
Abstract
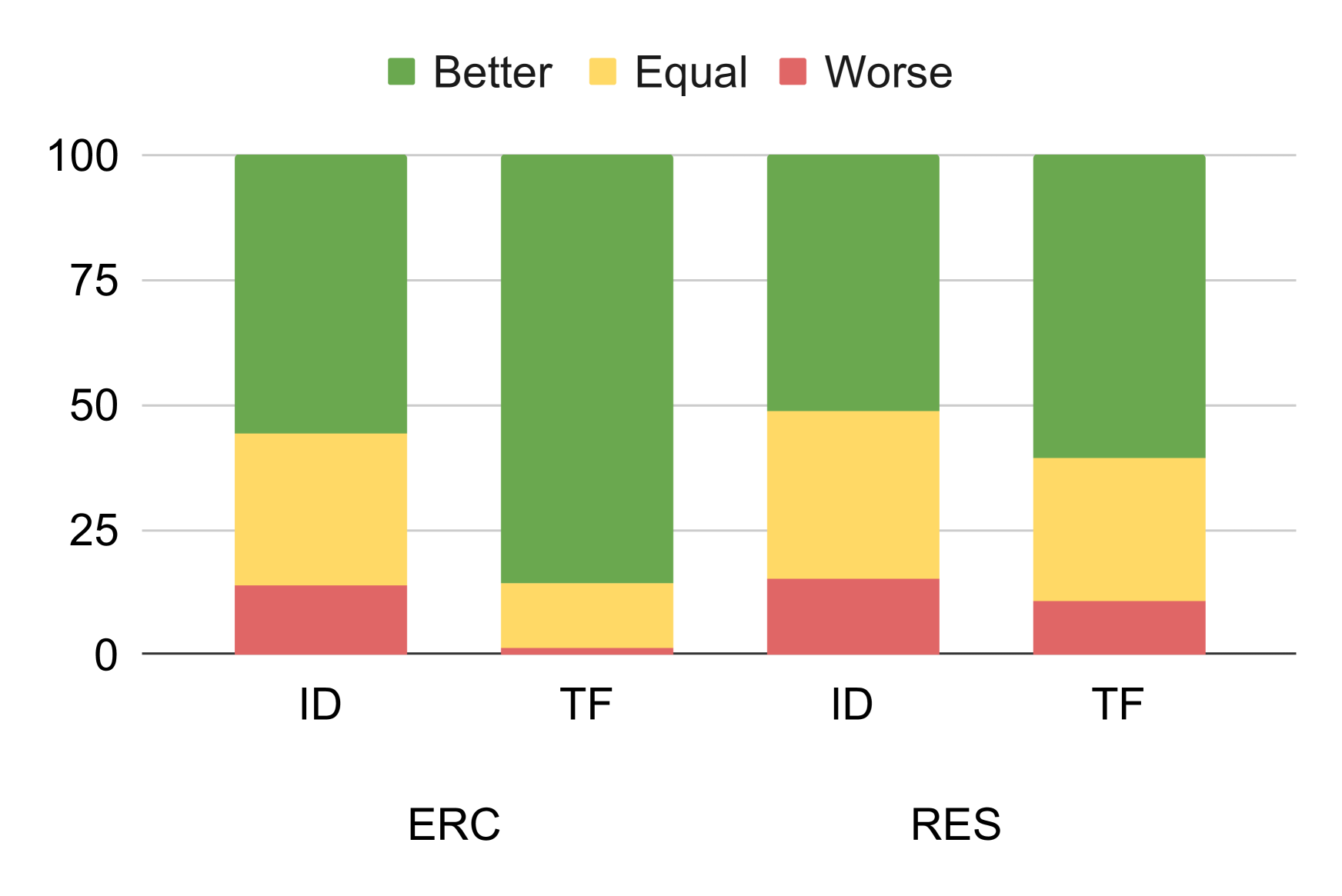
Eliciting feedback from end users of NLP models can be beneficial for improving models. However, how should we present model responses to users so they are most amenable to be corrected from user feedback? Further, what properties do users value to understand and trust responses? We answer these questions by analyzing the effect of rationales (or explanations) generated by QA models to support their answers. We specifically consider decomposed QA models that first extract an intermediate rationale based on a context and a question and then use solely this rationale to answer the question. A rationale outlines the approach followed by the model to answer the question. Our work considers various formats of these rationales that vary according to well-defined properties of interest. We sample rationales from language models using few-shot prompting for two datasets, and then perform two user studies. First, we present users with incorrect answers and corresponding rationales in various formats and ask them to provide natural language feedback to revise the rationale. We then measure the effectiveness of this feedback in patching these rationales through in-context learning. The second study evaluates how well different rationale formats enable users to understand and trust model answers, when they are correct. We find that rationale formats significantly affect how easy it is (1) for users to give feedback for rationales, and (2) for models to subsequently execute this feedback. In addition, formats with attributions to the context and in-depth reasoning significantly enhance user-reported understanding and trust of model outputs.
Create account to get full access
Overview
- Eliciting user feedback can help improve natural language processing (NLP) models, but how should model responses be presented to make users more receptive to providing feedback?
- The study examines different formats of "rationales" (explanations) generated by question-answering (QA) models to understand what properties help users trust and understand the model's responses.
- The researchers conducted two user studies to evaluate how different rationale formats affect the user's ability to provide feedback and the model's ability to incorporate that feedback.
Plain English Explanation
Imagine you're trying to teach a friend how to bake a cake. You could simply give them the final recipe, but it might be more helpful to also explain each step and why you're doing it a certain way. This "rationale" behind the steps can make it easier for your friend to understand the process, spot any mistakes, and provide feedback to improve the recipe.
Similarly, with NLP models that answer questions, providing explanations for how the model arrived at its answer can help users better understand and trust the model's responses. The researchers in this study explored different formats for these model "rationales" to see which ones made it easier for users to give feedback and for the models to incorporate that feedback to improve.
They had users review model answers with various rationale formats, like those that explained the reasoning in more depth or attributed key information to the original context. The researchers then measured how well users could provide feedback to revise the rationales, and how effectively the models could then learn from that feedback.
The study found that the rationale format had a significant impact on both the user's ability to give feedback and the model's ability to improve based on that feedback. Formats that provided more detailed explanations and context references tended to be more effective at helping users understand and trust the model's responses.
Technical Explanation
The researchers focused on "decomposed" QA models, which first extract an intermediate "rationale" based on the context and question, and then use only this rationale to generate the final answer. They explored different formats for these rationales, varying properties like the level of detail, attribution to the original context, and degree of reasoning provided.
The study consisted of two user experiments. In the first, users were shown incorrect model answers along with different rationale formats, and asked to provide natural language feedback to revise the rationales. The researchers then measured how effectively the models could learn from this feedback through in-context learning.
In the second experiment, users were shown correct model answers with different rationale formats, and asked to report their understanding and trust in the responses. This evaluated how well the rationale formats enabled users to comprehend and rely on the model's outputs.
The results showed that rationale format had a significant impact on both user feedback provision and model learning. Formats with more detailed reasoning and stronger context attribution led to more effective user feedback and model improvement. Additionally, these more informative rationale formats also enhanced user-reported understanding and trust in the model's correct answers.
Critical Analysis
The paper provides a thoughtful examination of an important challenge in building effective human-AI collaborations for NLP tasks. Eliciting useful feedback from end users is crucial, but the way model responses are presented can greatly impact the quality and receptiveness of that feedback.
One limitation noted is that the study focused on a specific type of QA model architecture. The insights may not generalize as readily to other NLP model types or task domains. Additionally, the experiments were conducted with a limited number of users, so the statistical power and generalizability of the findings could be further strengthened.
The research also does not deeply explore potential downsides or unintended consequences of over-explaining model reasoning. Excessive detail or attribution information could potentially confuse or overwhelm users, reducing trust rather than enhancing it. Finding the right balance is an area warranting further study.
Overall, this work provides a valuable foundation for understanding how to design model explanations that facilitate productive human-AI collaboration. Continued research in this direction, with broader scopes and more diverse user populations, could yield important advances in making NLP systems more transparent, accountable, and user-centric.
Conclusion
This study investigates how the format of model "rationales" or explanations can impact a user's ability to provide feedback and the model's capacity to learn from that feedback. The findings suggest that more detailed and contextual rationale formats tend to be more effective at soliciting useful user input and enabling models to improve based on that input.
These insights could help guide the development of NLP systems that are more collaborative and responsive to end-user needs. By carefully designing model explanation interfaces, developers can foster greater user trust, understanding, and engagement - ultimately leading to NLP models that are more accurate, reliable, and aligned with human priorities. Further research in this direction has the potential to significantly advance the field of human-centered AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring the Trade-off Between Model Performance and Explanation Plausibility of Text Classifiers Using Human Rationales
Lucas E. Resck, Marcos M. Raimundo, Jorge Poco
0
0
Saliency post-hoc explainability methods are important tools for understanding increasingly complex NLP models. While these methods can reflect the model's reasoning, they may not align with human intuition, making the explanations not plausible. In this work, we present a methodology for incorporating rationales, which are text annotations explaining human decisions, into text classification models. This incorporation enhances the plausibility of post-hoc explanations while preserving their faithfulness. Our approach is agnostic to model architectures and explainability methods. We introduce the rationales during model training by augmenting the standard cross-entropy loss with a novel loss function inspired by contrastive learning. By leveraging a multi-objective optimization algorithm, we explore the trade-off between the two loss functions and generate a Pareto-optimal frontier of models that balance performance and plausibility. Through extensive experiments involving diverse models, datasets, and explainability methods, we demonstrate that our approach significantly enhances the quality of model explanations without causing substantial (sometimes negligible) degradation in the original model's performance.
4/5/2024

Towards a Framework for Evaluating Explanations in Automated Fact Verification
Neema Kotonya, Francesca Toni
0
0
As deep neural models in NLP become more complex, and as a consequence opaque, the necessity to interpret them becomes greater. A burgeoning interest has emerged in rationalizing explanations to provide short and coherent justifications for predictions. In this position paper, we advocate for a formal framework for key concepts and properties about rationalizing explanations to support their evaluation systematically. We also outline one such formal framework, tailored to rationalizing explanations of increasingly complex structures, from free-form explanations to deductive explanations, to argumentative explanations (with the richest structure). Focusing on the automated fact verification task, we provide illustrations of the use and usefulness of our formalization for evaluating explanations, tailored to their varying structures.
5/21/2024

Why Would You Suggest That? Human Trust in Language Model Responses
Manasi Sharma, Ho Chit Siu, Rohan Paleja, Jaime D. Pe~na
0
0
The emergence of Large Language Models (LLMs) has revealed a growing need for human-AI collaboration, especially in creative decision-making scenarios where trust and reliance are paramount. Through human studies and model evaluations on the open-ended News Headline Generation task from the LaMP benchmark, we analyze how the framing and presence of explanations affect user trust and model performance. Overall, we provide evidence that adding an explanation in the model response to justify its reasoning significantly increases self-reported user trust in the model when the user has the opportunity to compare various responses. Position and faithfulness of these explanations are also important factors. However, these gains disappear when users are shown responses independently, suggesting that humans trust all model responses, including deceptive ones, equitably when they are shown in isolation. Our findings urge future research to delve deeper into the nuanced evaluation of trust in human-machine teaming systems.
6/5/2024
New!Leveraging Machine-Generated Rationales to Facilitate Social Meaning Detection in Conversations
Ritam Dutt, Zhen Wu, Kelly Shi, Divyanshu Sheth, Prakhar Gupta, Carolyn Penstein Rose
0
0
We present a generalizable classification approach that leverages Large Language Models (LLMs) to facilitate the detection of implicitly encoded social meaning in conversations. We design a multi-faceted prompt to extract a textual explanation of the reasoning that connects visible cues to underlying social meanings. These extracted explanations or rationales serve as augmentations to the conversational text to facilitate dialogue understanding and transfer. Our empirical results over 2,340 experimental settings demonstrate the significant positive impact of adding these rationales. Our findings hold true for in-domain classification, zero-shot, and few-shot domain transfer for two different social meaning detection tasks, each spanning two different corpora.
7/1/2024