Why Would You Suggest That? Human Trust in Language Model Responses
2406.02018
0
0

Abstract
The emergence of Large Language Models (LLMs) has revealed a growing need for human-AI collaboration, especially in creative decision-making scenarios where trust and reliance are paramount. Through human studies and model evaluations on the open-ended News Headline Generation task from the LaMP benchmark, we analyze how the framing and presence of explanations affect user trust and model performance. Overall, we provide evidence that adding an explanation in the model response to justify its reasoning significantly increases self-reported user trust in the model when the user has the opportunity to compare various responses. Position and faithfulness of these explanations are also important factors. However, these gains disappear when users are shown responses independently, suggesting that humans trust all model responses, including deceptive ones, equitably when they are shown in isolation. Our findings urge future research to delve deeper into the nuanced evaluation of trust in human-machine teaming systems.
Create account to get full access
Overview
- This paper explores the factors that influence human trust in language model responses.
- The researchers conducted experiments to understand how factors like anthropomorphic cues, explanations, and honesty affect people's willingness to trust and rely on language model outputs.
- The findings provide insights into the complex relationship between humans and AI systems, and have implications for the design and deployment of trustworthy language models.
Plain English Explanation
When interacting with AI language models, people often need to decide how much to trust the responses they receive. This paper investigates the factors that shape human trust in language model outputs.
The researchers ran a series of experiments to see how different elements, like whether the model seems human-like, provides explanations, or is transparent about its capabilities, impact people's willingness to trust and follow the model's suggestions. For example, the study looked at whether people are more likely to trust a language model that gives a clear rationale for its responses compared to one that doesn't.
The results shed light on the nuanced way humans interpret and assess language model behavior. They suggest that designing AI systems that are transparent about their limitations and provide relevant explanations can help foster greater trust and appropriate reliance from human users. This is an important consideration as language models become more widely adopted.
Technical Explanation
This paper investigates the factors that influence human trust in language model responses. The researchers conducted a series of experiments to understand how anthropomorphic cues, explanations, and honesty about capabilities affect people's willingness to trust and rely on language model outputs.
The experimental design involved presenting participants with language model responses under different conditions. For example, some responses included anthropomorphic cues that made the model seem more human-like, while others provided explanations for the model's reasoning. The researchers then measured how much participants trusted and intended to follow the model's suggestions.
The results suggest that both anthropomorphic cues and explanations can increase trust, but that honesty about the model's capabilities is also important. Participants were less trusting when the model's responses lacked transparency about its limitations. The findings indicate that the design of language models should carefully consider how to balance human-like attributes with clear communication of the system's actual abilities.
Critical Analysis
The paper provides valuable insights into the complex relationship between humans and language models, but also highlights some important caveats and areas for further research.
One limitation is the reliance on hypothetical scenarios rather than real-world interactions. While this allowed for controlled experiments, it may not fully capture the nuances of how people assess trust in practical applications. Future work could explore trust dynamics in more naturalistic settings.
Additionally, the study focused on a single language model with a specific set of capabilities. The findings may not generalize to other models with different architectures or functionality. Further research is needed to understand how trust factors may vary across diverse AI systems.
The paper also does not delve into potential biases or errors that language models may exhibit, which could undermine human trust. Addressing these issues of model reliability and transparency is crucial for developing trustworthy AI systems.
Overall, this paper lays important groundwork for understanding the factors that shape human-AI trust, but continued exploration and a critical eye are necessary to ensure language models are designed to be truly trustworthy.
Conclusion
This study provides valuable insights into the complex factors that influence human trust in language model responses. The findings suggest that design elements like anthropomorphic cues, explanations, and honesty about capabilities can all play a role in shaping people's willingness to trust and rely on language model outputs.
These insights have important implications for the development of trustworthy AI systems. As language models become more widely adopted, understanding how to foster appropriate trust and reliance will be crucial. The paper's recommendations around transparent communication and balancing human-like attributes with clear articulation of limitations can help guide the design of language models that are more aligned with human expectations and needs.
Further research is needed to explore trust dynamics in more realistic settings and across diverse AI architectures. Ongoing critical examination of language model reliability and potential biases is also essential. By continuing to study and address the complexities of human-AI trust, we can work towards developing AI systems that are truly worthy of people's confidence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Unraveling the Dilemma of AI Errors: Exploring the Effectiveness of Human and Machine Explanations for Large Language Models
Marvin Pafla, Kate Larson, Mark Hancock
0
0
The field of eXplainable artificial intelligence (XAI) has produced a plethora of methods (e.g., saliency-maps) to gain insight into artificial intelligence (AI) models, and has exploded with the rise of deep learning (DL). However, human-participant studies question the efficacy of these methods, particularly when the AI output is wrong. In this study, we collected and analyzed 156 human-generated text and saliency-based explanations collected in a question-answering task (N=40) and compared them empirically to state-of-the-art XAI explanations (integrated gradients, conservative LRP, and ChatGPT) in a human-participant study (N=136). Our findings show that participants found human saliency maps to be more helpful in explaining AI answers than machine saliency maps, but performance negatively correlated with trust in the AI model and explanations. This finding hints at the dilemma of AI errors in explanation, where helpful explanations can lead to lower task performance when they support wrong AI predictions.
4/12/2024
💬
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Chenglei Si, Navita Goyal, Sherry Tongshuang Wu, Chen Zhao, Shi Feng, Hal Daum'e III, Jordan Boyd-Graber
0
0
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they get, LLMs should not only provide information but also help users fact-check it. Our experiments with 80 crowdworkers compare language models with search engines (information retrieval systems) at facilitating fact-checking. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than those using search engines while achieving similar accuracy. However, they over-rely on the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. Further, showing both search engine results and LLM explanations offers no complementary benefits compared to search engines alone. Taken together, our study highlights that natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
4/3/2024
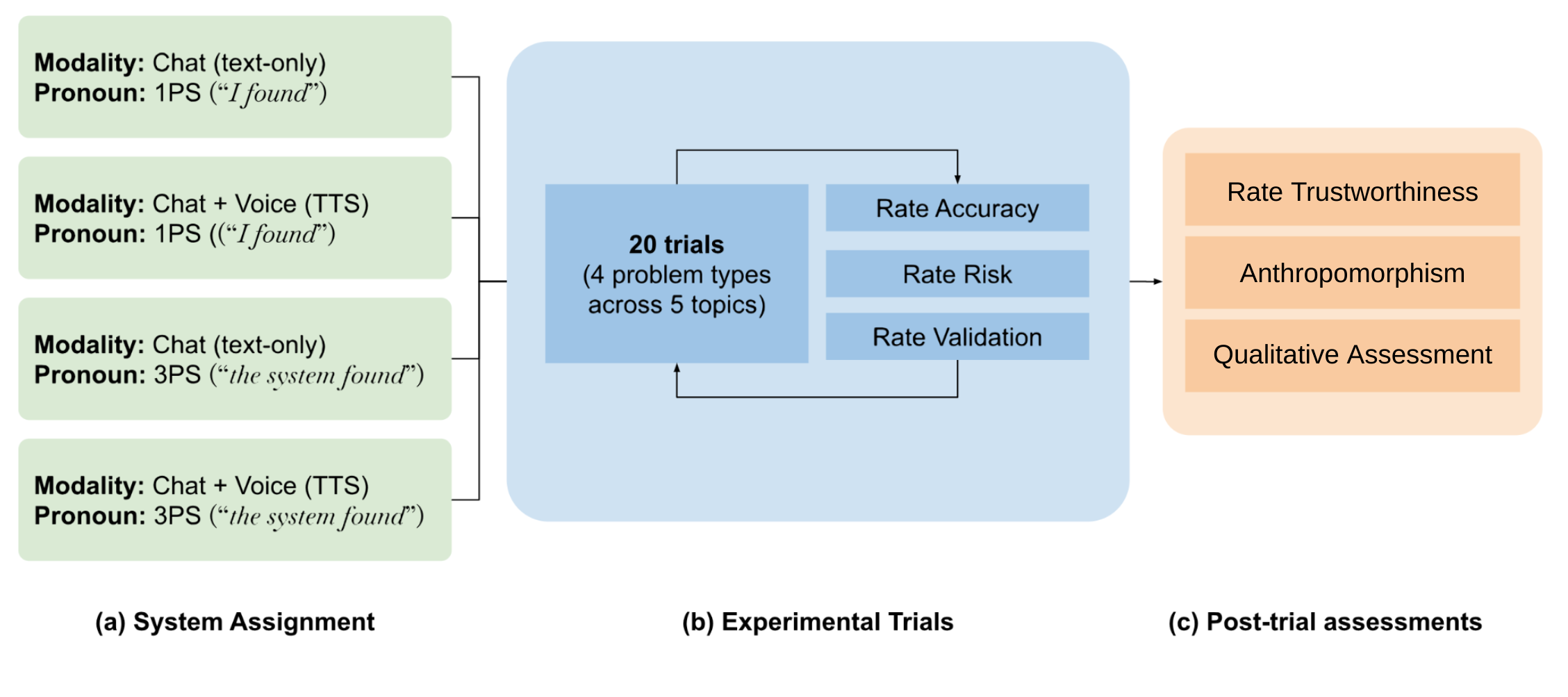
Believing Anthropomorphism: Examining the Role of Anthropomorphic Cues on Trust in Large Language Models
Michelle Cohn, Mahima Pushkarna, Gbolahan O. Olanubi, Joseph M. Moran, Daniel Padgett, Zion Mengesha, Courtney Heldreth
0
0
People now regularly interface with Large Language Models (LLMs) via speech and text (e.g., Bard) interfaces. However, little is known about the relationship between how users anthropomorphize an LLM system (i.e., ascribe human-like characteristics to a system) and how they trust the information the system provides. Participants (n=2,165; ranging in age from 18-90 from the United States) completed an online experiment, where they interacted with a pseudo-LLM that varied in modality (text only, speech + text) and grammatical person (I vs. the system) in its responses. Results showed that the speech + text condition led to higher anthropomorphism of the system overall, as well as higher ratings of accuracy of the information the system provides. Additionally, the first-person pronoun (I) led to higher information accuracy and reduced risk ratings, but only in one context. We discuss these findings for their implications for the design of responsible, human-generative AI experiences.
5/13/2024

Evaluating Transparency of Machine Generated Fact Checking Explanations
Rui Xing, Timothy Baldwin, Jey Han Lau
0
0
An important factor when it comes to generating fact-checking explanations is the selection of evidence: intuitively, high-quality explanations can only be generated given the right evidence. In this work, we investigate the impact of human-curated vs. machine-selected evidence for explanation generation using large language models. To assess the quality of explanations, we focus on transparency (whether an explanation cites sources properly) and utility (whether an explanation is helpful in clarifying a claim). Surprisingly, we found that large language models generate similar or higher quality explanations using machine-selected evidence, suggesting carefully curated evidence (by humans) may not be necessary. That said, even with the best model, the generated explanations are not always faithful to the sources, suggesting further room for improvement in explanation generation for fact-checking.
6/19/2024