What Is Wrong with My Model? Identifying Systematic Problems with Semantic Data Slicing

0
Sign in to get full access
Overview
- This paper introduces a technique called "semantic data slicing" to help identify systematic problems in machine learning models.
- The key idea is to analyze model performance across semantically meaningful subsets of the data, rather than just looking at overall metrics.
- This can uncover hidden biases or weaknesses that are obscured by aggregate metrics, allowing developers to better understand and improve their models.
Plain English Explanation
The paper presents a method called "semantic data slicing" to help identify issues with machine learning models. The core idea is to look at how a model performs on different subsets of the data, based on the semantic meaning of that data, rather than just looking at the model's overall performance metrics.
For example, rather than just measuring the model's accuracy on an entire dataset, you would break the dataset into different subgroups - like images of dogs, cats, and birds - and see how the model performs on each of those slices. This can reveal systematic biases or weaknesses in the model that might be hidden when you only look at the average performance.
By analyzing model performance across these semantic data slices, developers can get a much more nuanced and insightful picture of what their model is actually doing. This allows them to more effectively diagnose and address problems, ultimately improving the model's robustness and reliability.
Technical Explanation
The paper introduces "semantic data slicing" as a technique to uncover systematic problems in machine learning models. Traditional model evaluation often focuses on aggregate metrics like overall accuracy, but this can mask important issues that are visible only in subsets of the data.
The authors propose analyzing model performance across semantically meaningful data slices - for example, measuring accuracy separately for images of dogs, cats, and birds. This allows developers to identify systematic biases or weaknesses that may be obscured in the overall numbers.
The paper describes a framework for defining these semantic data slices, including using techniques like natural language processing to automatically extract relevant concepts from the data. They demonstrate the approach on several real-world machine learning tasks, showing how semantic slicing can reveal insights that wouldn't be visible from aggregate metrics alone.
Critical Analysis
The semantic data slicing approach seems promising as a way to get deeper insights into machine learning model behavior. By looking at performance across meaningful subsets of the data, it can uncover issues that would otherwise be hidden. This aligns with a growing recognition that aggregate metrics like accuracy can be misleading, and there is a need for more nuanced evaluation techniques.
That said, the paper does not address some potential limitations or challenges. For example, defining the appropriate semantic slices requires careful thought and may not be straightforward for all datasets. There is also the risk of "cherry-picking" slices that confirm the developer's preconceptions, rather than taking a more comprehensive view.
Additionally, the paper focuses on diagnosis of model issues, but does not delve into how to actually fix the problems that are uncovered. More guidance on the remediation process would be valuable for practitioners trying to apply these techniques.
Overall, the semantic data slicing approach seems like a valuable tool, but it should be considered as part of a broader model evaluation and improvement process, rather than a silver bullet solution. Developers will need to think critically about how to define and interpret the semantic slices in their specific contexts.
Conclusion
This paper introduces "semantic data slicing" as a novel technique to help diagnose and address systematic issues in machine learning models. By analyzing model performance across semantically meaningful subsets of the data, rather than just looking at aggregate metrics, developers can uncover hidden biases and weaknesses.
The approach has the potential to significantly improve model transparency and robustness, allowing for more effective model development and deployment. While the paper does not address all the potential challenges, it represents an important step forward in the quest for more nuanced and insightful model evaluation methods.
As machine learning systems become increasingly pervasive, techniques like semantic data slicing will be crucial for building models that are reliable, fair, and trustworthy across a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
What Is Wrong with My Model? Identifying Systematic Problems with Semantic Data Slicing
Chenyang Yang, Yining Hong, Grace A. Lewis, Tongshuang Wu, Christian Kastner
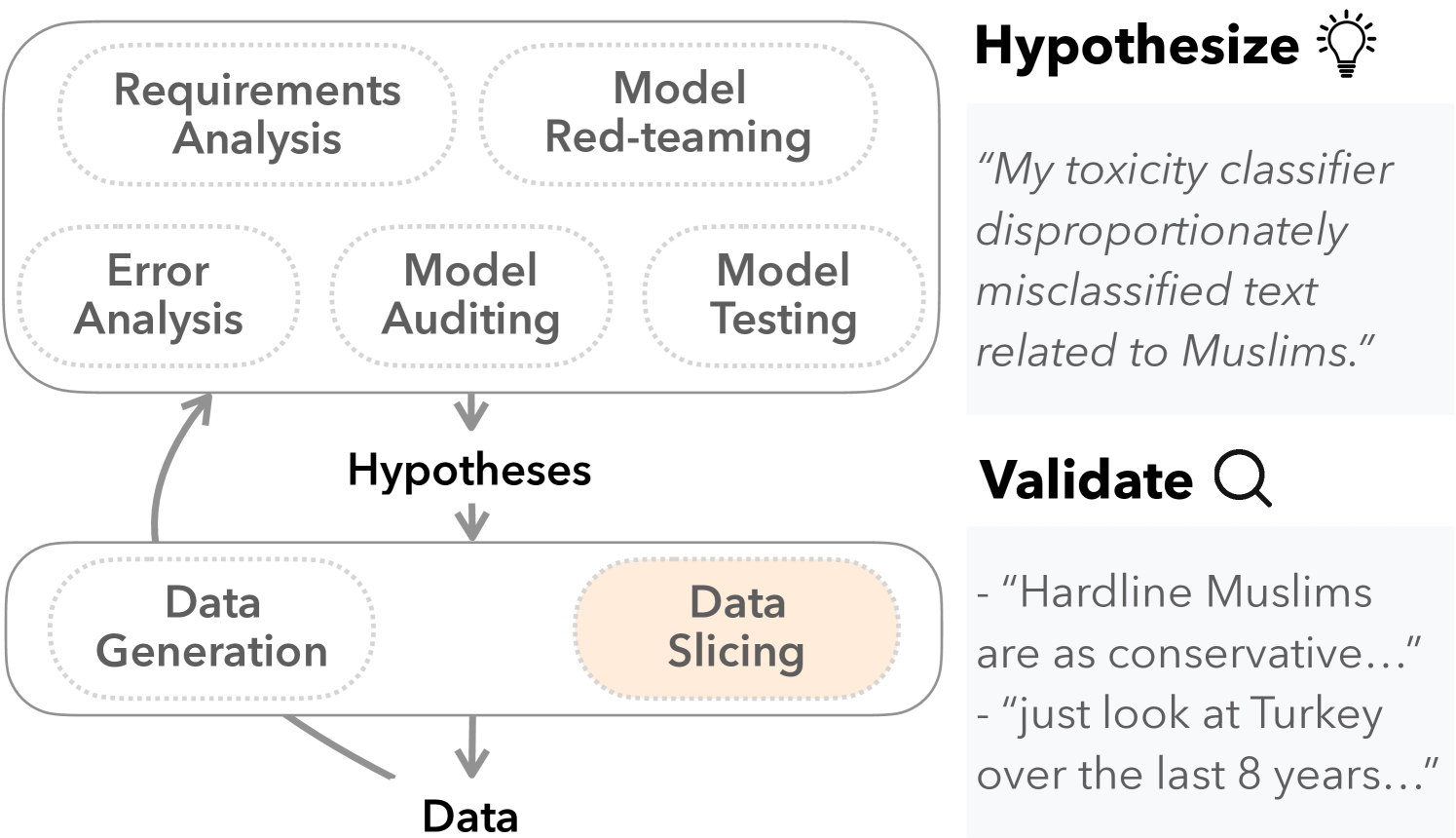
Machine learning models make mistakes, yet sometimes it is difficult to identify the systematic problems behind the mistakes. Practitioners engage in various activities, including error analysis, testing, auditing, and red-teaming, to form hypotheses of what can go (or has gone) wrong with their models. To validate these hypotheses, practitioners employ data slicing to identify relevant examples. However, traditional data slicing is limited by available features and programmatic slicing functions. In this work, we propose SemSlicer, a framework that supports semantic data slicing, which identifies a semantically coherent slice, without the need for existing features. SemSlicer uses Large Language Models to annotate datasets and generate slices from any user-defined slicing criteria. We show that SemSlicer generates accurate slices with low cost, allows flexible trade-offs between different design dimensions, reliably identifies under-performing data slices, and helps practitioners identify useful data slices that reflect systematic problems.
Read more9/17/2024

0
NeuSemSlice: Towards Effective DNN Model Maintenance via Neuron-level Semantic Slicing
Shide Zhou, Tianlin Li, Yihao Huang, Ling Shi, Kailong Wang, Yang Liu, Haoyu Wang
Deep Neural networks (DNNs), extensively applied across diverse disciplines, are characterized by their integrated and monolithic architectures, setting them apart from conventional software systems. This architectural difference introduces particular challenges to maintenance tasks, such as model restructuring (e.g., model compression), re-adaptation (e.g., fitting new samples), and incremental development (e.g., continual knowledge accumulation). Prior research addresses these challenges by identifying task-critical neuron layers, and dividing neural networks into semantically-similar sequential modules. However, such layer-level approaches fail to precisely identify and manipulate neuron-level semantic components, restricting their applicability to finer-grained model maintenance tasks. In this work, we implement NeuSemSlice, a novel framework that introduces the semantic slicing technique to effectively identify critical neuron-level semantic components in DNN models for semantic-aware model maintenance tasks. Specifically, semantic slicing identifies, categorizes and merges critical neurons across different categories and layers according to their semantic similarity, enabling their flexibility and effectiveness in the subsequent tasks. For semantic-aware model maintenance tasks, we provide a series of novel strategies based on semantic slicing to enhance NeuSemSlice. They include semantic components (i.e., critical neurons) preservation for model restructuring, critical neuron tuning for model re-adaptation, and non-critical neuron training for model incremental development. A thorough evaluation has demonstrated that NeuSemSlice significantly outperforms baselines in all three tasks.
Read more7/31/2024

0
Trusting Semantic Segmentation Networks
Samik Some, Vinay P. Namboodiri
Semantic segmentation has become an important task in computer vision with the growth of self-driving cars, medical image segmentation, etc. Although current models provide excellent results, they are still far from perfect and while there has been significant work in trying to improve the performance, both with respect to accuracy and speed of segmentation, there has been little work which analyses the failure cases of such systems. In this work, we aim to provide an analysis of how segmentation fails across different models and consider the question of whether these can be predicted reasonably at test time. To do so, we explore existing uncertainty-based metrics and see how well they correlate with misclassifications, allowing us to define the degree of trust we put in the output of our prediction models. Through several experiments on three different models across three datasets, we show that simple measures such as entropy can be used to capture misclassification with high recall rates.
Read more6/21/2024
0
Slicing Through Bias: Explaining Performance Gaps in Medical Image Analysis using Slice Discovery Methods
Vincent Olesen, Nina Weng, Aasa Feragen, Eike Petersen
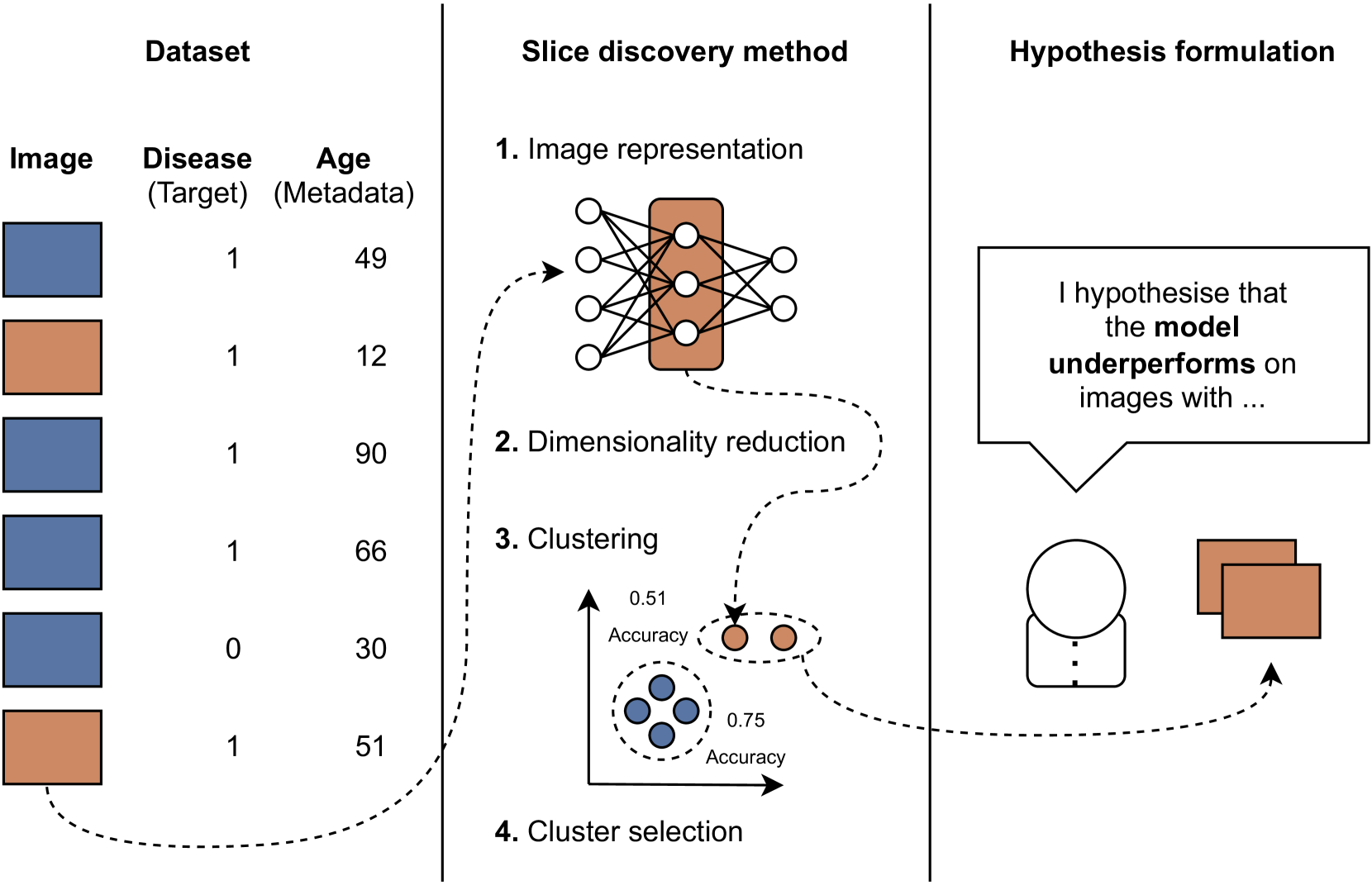
Machine learning models have achieved high overall accuracy in medical image analysis. However, performance disparities on specific patient groups pose challenges to their clinical utility, safety, and fairness. This can affect known patient groups - such as those based on sex, age, or disease subtype - as well as previously unknown and unlabeled groups. Furthermore, the root cause of such observed performance disparities is often challenging to uncover, hindering mitigation efforts. In this paper, to address these issues, we leverage Slice Discovery Methods (SDMs) to identify interpretable underperforming subsets of data and formulate hypotheses regarding the cause of observed performance disparities. We introduce a novel SDM and apply it in a case study on the classification of pneumothorax and atelectasis from chest x-rays. Our study demonstrates the effectiveness of SDMs in hypothesis formulation and yields an explanation of previously observed but unexplained performance disparities between male and female patients in widely used chest X-ray datasets and models. Our findings indicate shortcut learning in both classification tasks, through the presence of chest drains and ECG wires, respectively. Sex-based differences in the prevalence of these shortcut features appear to cause the observed classification performance gap, representing a previously underappreciated interaction between shortcut learning and model fairness analyses.
Read more6/19/2024