Why Only Text: Empowering Vision-and-Language Navigation with Multi-modal Prompts
2406.02208
0
0

Abstract
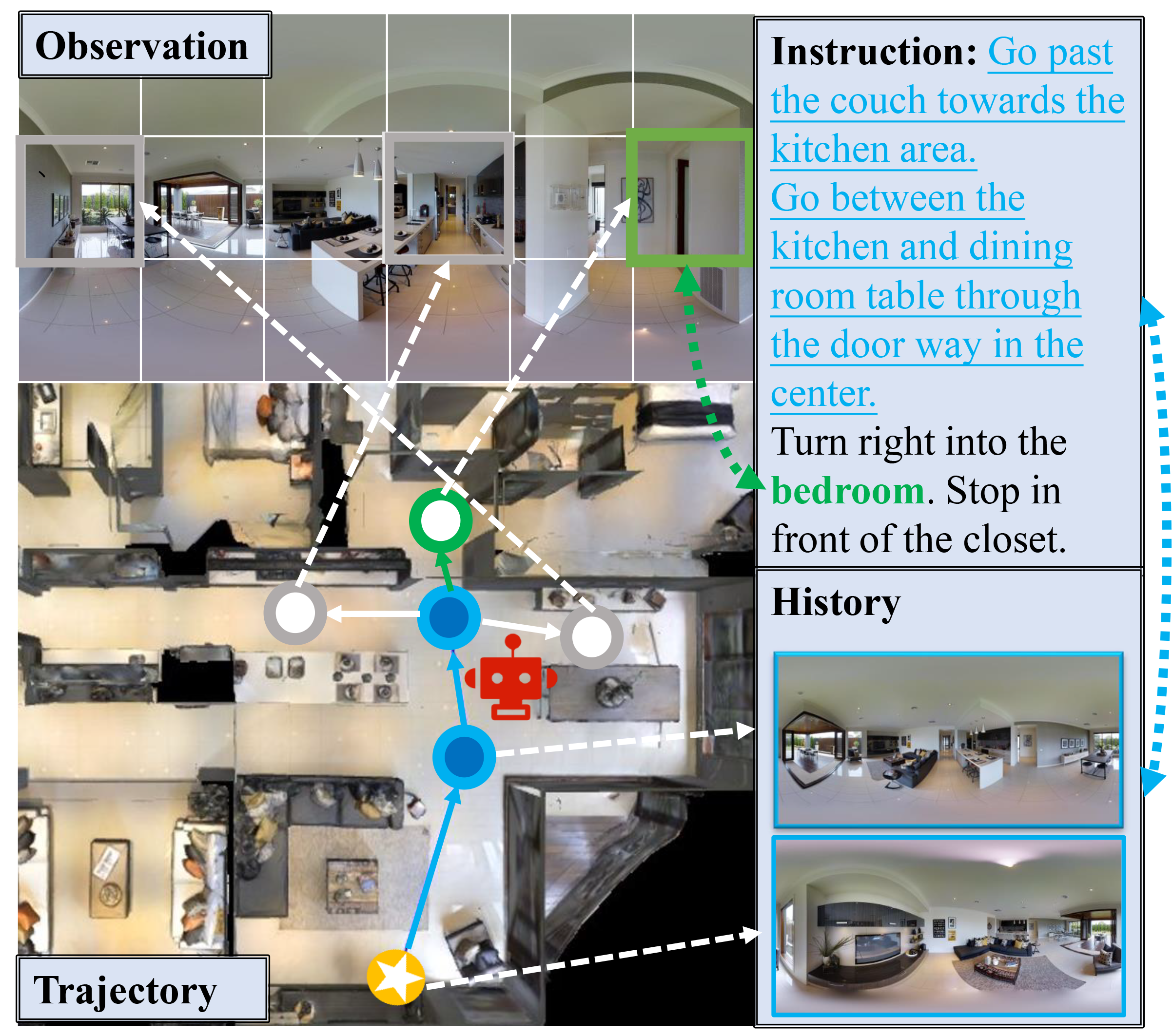
Current Vision-and-Language Navigation (VLN) tasks mainly employ textual instructions to guide agents. However, being inherently abstract, the same textual instruction can be associated with different visual signals, causing severe ambiguity and limiting the transfer of prior knowledge in the vision domain from the user to the agent. To fill this gap, we propose Vision-and-Language Navigation with Multi-modal Prompts (VLN-MP), a novel task augmenting traditional VLN by integrating both natural language and images in instructions. VLN-MP not only maintains backward compatibility by effectively handling text-only prompts but also consistently shows advantages with different quantities and relevance of visual prompts. Possible forms of visual prompts include both exact and similar object images, providing adaptability and versatility in diverse navigation scenarios. To evaluate VLN-MP under a unified framework, we implement a new benchmark that offers: (1) a training-free pipeline to transform textual instructions into multi-modal forms with landmark images; (2) diverse datasets with multi-modal instructions for different downstream tasks; (3) a novel module designed to process various image prompts for seamless integration with state-of-the-art VLN models. Extensive experiments on four VLN benchmarks (R2R, RxR, REVERIE, CVDN) show that incorporating visual prompts significantly boosts navigation performance. While maintaining efficiency with text-only prompts, VLN-MP enables agents to navigate in the pre-explore setting and outperform text-based models, showing its broader applicability.
Create account to get full access
Overview
- This paper explores the use of multi-modal prompts to improve vision-and-language navigation (VLN) tasks.
- VLN involves navigating through visual environments based on natural language instructions.
- The authors propose leveraging multi-modal prompts, combining text, images, and other modalities, to enhance the performance of VLN models.
- The paper compares the effectiveness of multi-modal prompts against traditional text-only prompts across various VLN benchmarks.
Plain English Explanation
The paper focuses on a task called vision-and-language navigation (VLN), where the goal is to navigate through a visual environment based on natural language instructions. For example, imagine you're in a virtual building and a voice tells you to "Go down the hallway, turn left at the second door, and enter the room on the right."
Traditionally, VLN models have relied solely on text-based instructions to guide their navigation. However, the authors of this paper hypothesized that providing additional visual information, along with the text, could improve the models' performance.
They experimented with using "multi-modal prompts" - a combination of text, images, and potentially other modalities - to give the VLN models more context and guidance. The idea is that the additional visual cues could help the models better understand the environment and follow the instructions more accurately.
The researchers tested their multi-modal approach on several VLN benchmark datasets and found that it outperformed traditional text-only prompts. This suggests that incorporating diverse modalities can indeed empower VLN models to navigate more effectively in complex, real-world environments.
Technical Explanation
The paper proposes a novel approach to vision-and-language navigation (VLN) that leverages multi-modal prompts. VLN involves navigating through visual environments based on natural language instructions. Traditionally, VLN models have relied solely on text-based prompts to guide their navigation.
The authors hypothesized that incorporating additional modalities, such as images, into the prompts could enhance the models' performance. To test this, they developed a multi-modal prompt format that combines textual instructions with relevant visual information.
The researchers evaluated their approach on several VLN benchmark datasets, including MC-GPT, DELAN, and NavID. They compared the performance of multi-modal prompts against traditional text-only prompts and found that the multi-modal approach consistently outperformed the text-only baseline across the different benchmarks.
The authors also conducted ablation studies to understand the relative contributions of the various prompt modalities. Their results suggest that the combination of text, images, and other modalities is more effective than any single modality alone, highlighting the value of a multi-modal prompt format for VLN tasks.
Critical Analysis
The paper presents a compelling approach to improving VLN models by leveraging multi-modal prompts. The authors provide a thorough evaluation across multiple benchmark datasets, which strengthens the validity of their findings.
One potential limitation, as mentioned in the paper, is the need for additional work to scale the multi-modal prompt generation to larger and more diverse datasets. The current approach relies on carefully curated prompts, which may not be feasible for real-world applications with vast amounts of data.
Additionally, the paper does not discuss the computational costs or inference times associated with the multi-modal prompt format, which could be an important consideration for practical deployments. Further research may be needed to optimize the efficiency of the proposed approach.
The authors also acknowledge that their work primarily focuses on navigation in static environments and suggest exploring dynamic, video-based scenarios as a future direction. Extending the multi-modal prompt concept to handle more complex, real-world navigation tasks could be a valuable area for further investigation.
Conclusion
This paper presents a novel approach to vision-and-language navigation (VLN) that leverages multi-modal prompts, combining text, images, and potentially other modalities. The authors demonstrate that this multi-modal approach outperforms traditional text-only prompts across several VLN benchmark datasets.
The findings suggest that incorporating diverse modalities can significantly empower VLN models, enabling them to better understand and navigate complex visual environments based on natural language instructions. This research has the potential to drive advancements in applications such as autonomous navigation, interactive virtual assistants, and augmented reality experiences.
By continuing to explore the potential of multi-modal prompts and other innovative techniques, the field of VLN can further enhance the capabilities of language-guided navigation systems, making them more robust, efficient, and adaptable to real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
0
0
While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a red bounding box or pointed arrow. Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
4/30/2024

MC-GPT: Empowering Vision-and-Language Navigation with Memory Map and Reasoning Chains
Zhaohuan Zhan, Lisha Yu, Sijie Yu, Guang Tan
0
0
In the Vision-and-Language Navigation (VLN) task, the agent is required to navigate to a destination following a natural language instruction. While learning-based approaches have been a major solution to the task, they suffer from high training costs and lack of interpretability. Recently, Large Language Models (LLMs) have emerged as a promising tool for VLN due to their strong generalization capabilities. However, existing LLM-based methods face limitations in memory construction and diversity of navigation strategies. To address these challenges, we propose a suite of techniques. Firstly, we introduce a method to maintain a topological map that stores navigation history, retaining information about viewpoints, objects, and their spatial relationships. This map also serves as a global action space. Additionally, we present a Navigation Chain of Thoughts module, leveraging human navigation examples to enrich navigation strategy diversity. Finally, we establish a pipeline that integrates navigational memory and strategies with perception and action prediction modules. Experimental results on the REVERIE and R2R datasets show that our method effectively enhances the navigation ability of the LLM and improves the interpretability of navigation reasoning.
5/20/2024
DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning
Mengfei Du, Binhao Wu, Jiwen Zhang, Zhihao Fan, Zejun Li, Ruipu Luo, Xuanjing Huang, Zhongyu Wei
0
0
Vision-and-Language navigation (VLN) requires an agent to navigate in unseen environment by following natural language instruction. For task completion, the agent needs to align and integrate various navigation modalities, including instruction, observation and navigation history. Existing works primarily concentrate on cross-modal attention at the fusion stage to achieve this objective. Nevertheless, modality features generated by disparate uni-encoders reside in their own spaces, leading to a decline in the quality of cross-modal fusion and decision. To address this problem, we propose a Dual-levEL AligNment (DELAN) framework by cross-modal contrastive learning. This framework is designed to align various navigation-related modalities before fusion, thereby enhancing cross-modal interaction and action decision-making. Specifically, we divide the pre-fusion alignment into dual levels: instruction-history level and landmark-observation level according to their semantic correlations. We also reconstruct a dual-level instruction for adaptation to the dual-level alignment. As the training signals for pre-fusion alignment are extremely limited, self-supervised contrastive learning strategies are employed to enforce the matching between different modalities. Our approach seamlessly integrates with the majority of existing models, resulting in improved navigation performance on various VLN benchmarks, including R2R, R4R, RxR and CVDN.
4/3/2024

NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, He Wang
0
0
Vision-and-language navigation (VLN) stands as a key research problem of Embodied AI, aiming at enabling agents to navigate in unseen environments following linguistic instructions. In this field, generalization is a long-standing challenge, either to out-of-distribution scenes or from Sim to Real. In this paper, we propose NaVid, a video-based large vision language model (VLM), to mitigate such a generalization gap. NaVid makes the first endeavor to showcase the capability of VLMs to achieve state-of-the-art level navigation performance without any maps, odometers, or depth inputs. Following human instruction, NaVid only requires an on-the-fly video stream from a monocular RGB camera equipped on the robot to output the next-step action. Our formulation mimics how humans navigate and naturally gets rid of the problems introduced by odometer noises, and the Sim2Real gaps from map or depth inputs. Moreover, our video-based approach can effectively encode the historical observations of robots as spatio-temporal contexts for decision making and instruction following. We train NaVid with 510k navigation samples collected from continuous environments, including action-planning and instruction-reasoning samples, along with 763k large-scale web data. Extensive experiments show that NaVid achieves state-of-the-art performance in simulation environments and the real world, demonstrating superior cross-dataset and Sim2Real transfer. We thus believe our proposed VLM approach plans the next step for not only the navigation agents but also this research field.
5/28/2024