DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning

0
Sign in to get full access
Overview
- This paper proposes a new approach called DELAN (Dual-Level Alignment) for vision-and-language navigation tasks.
- The key idea is to use cross-modal contrastive learning to align visual and language representations at both the global and local levels.
- The authors demonstrate that DELAN outperforms previous state-of-the-art methods on standard vision-and-language navigation benchmarks.
Plain English Explanation
The paper tackles the challenge of vision-and-language navigation, where an AI system needs to understand natural language instructions and use visual information from the environment to navigate to a target location. The researchers developed a new technique called DELAN that aims to better align the visual and language representations used by the AI system.
Traditionally, these systems have been trained to match the overall language instructions to the entire visual scene. DELAN goes a step further by also trying to align the specific parts of the language instructions with the corresponding regions in the visual input. This dual-level alignment helps the AI system understand the relationship between the language and the visual details more precisely.
The key innovation is the use of cross-modal contrastive learning, which forces the visual and language representations to be close to each other for matching pairs of instructions and scenes, while pushing them apart for mismatched pairs. This encourages the AI to learn robust correspondences between the language and visual modalities.
The experiments show that this approach leads to better navigation performance compared to previous methods, demonstrating the value of the dual-level alignment strategy. In essence, DELAN helps the AI system develop a deeper, more nuanced understanding of how language and vision work together to enable effective navigation.
Technical Explanation
The paper introduces DELAN, a new framework for vision-and-language navigation that uses cross-modal contrastive learning to align visual and language representations at both global and local levels. The intuition is that aligning these representations at multiple granularities can improve the AI system's understanding of the relationship between language instructions and visual observations.
DELAN consists of two main components: a global alignment module and a local alignment module. The global alignment module matches the overall language instruction to the entire visual scene, similar to prior work. The local alignment module, on the other hand, attempts to associate specific parts of the language instruction with corresponding regions in the visual input.
The cross-modal contrastive learning objective is applied to both the global and local representations. This objective encourages the model to push the representations of matching language-vision pairs closer together in the shared embedding space, while pulling apart the representations of mismatched pairs. This dual-level alignment strategy helps the model learn richer correspondences between the two modalities.
The authors evaluate DELAN on standard vision-and-language navigation benchmarks and demonstrate that it outperforms previous state-of-the-art approaches. The results indicate that the additional local alignment component and the cross-modal contrastive learning indeed help the model develop a more comprehensive understanding of the task.
Critical Analysis
The paper provides a thorough technical explanation of the DELAN approach and presents compelling empirical results on challenging benchmarks. The key strength of the work is the intuition to align visual and language representations at multiple levels, going beyond just global-level matching.
However, the paper does not fully address potential limitations or future research directions. For example, it would be interesting to understand how DELAN's performance scales with the complexity of the navigation tasks or the diversity of the language instructions. Additionally, the paper could have discussed ways to interpret the learned alignments and understand what the model is truly learning.
While the results are strong, it is also important to consider potential biases or dataset artifacts that could be influencing the model's performance. Further analysis on the generalization capabilities of DELAN would help solidify the significance of the findings.
Overall, the DELAN approach represents a promising step forward in vision-and-language navigation, but there are still avenues for improving the model's robustness and interpretability, as well as exploring the broader implications of this dual-level alignment strategy.
Conclusion
This paper introduces DELAN, a new framework for vision-and-language navigation that uses cross-modal contrastive learning to align visual and language representations at both global and local levels. The key insight is that achieving this dual-level alignment can lead to a more comprehensive understanding of the relationship between language instructions and visual observations, resulting in improved navigation performance.
The empirical results demonstrate the effectiveness of DELAN compared to previous state-of-the-art methods, highlighting the value of the proposed approach. While the paper provides a solid technical foundation, further research is needed to fully address potential limitations and explore the broader implications of this work.
Nonetheless, DELAN represents an important step forward in the field of vision-and-language navigation, showcasing the potential of cross-modal contrastive learning to enable AI systems that can better bridge the gap between language and vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning
Mengfei Du, Binhao Wu, Jiwen Zhang, Zhihao Fan, Zejun Li, Ruipu Luo, Xuanjing Huang, Zhongyu Wei
Vision-and-Language navigation (VLN) requires an agent to navigate in unseen environment by following natural language instruction. For task completion, the agent needs to align and integrate various navigation modalities, including instruction, observation and navigation history. Existing works primarily concentrate on cross-modal attention at the fusion stage to achieve this objective. Nevertheless, modality features generated by disparate uni-encoders reside in their own spaces, leading to a decline in the quality of cross-modal fusion and decision. To address this problem, we propose a Dual-levEL AligNment (DELAN) framework by cross-modal contrastive learning. This framework is designed to align various navigation-related modalities before fusion, thereby enhancing cross-modal interaction and action decision-making. Specifically, we divide the pre-fusion alignment into dual levels: instruction-history level and landmark-observation level according to their semantic correlations. We also reconstruct a dual-level instruction for adaptation to the dual-level alignment. As the training signals for pre-fusion alignment are extremely limited, self-supervised contrastive learning strategies are employed to enforce the matching between different modalities. Our approach seamlessly integrates with the majority of existing models, resulting in improved navigation performance on various VLN benchmarks, including R2R, R4R, RxR and CVDN.
Read more4/3/2024

0
Why Only Text: Empowering Vision-and-Language Navigation with Multi-modal Prompts
Haodong Hong, Sen Wang, Zi Huang, Qi Wu, Jiajun Liu
Current Vision-and-Language Navigation (VLN) tasks mainly employ textual instructions to guide agents. However, being inherently abstract, the same textual instruction can be associated with different visual signals, causing severe ambiguity and limiting the transfer of prior knowledge in the vision domain from the user to the agent. To fill this gap, we propose Vision-and-Language Navigation with Multi-modal Prompts (VLN-MP), a novel task augmenting traditional VLN by integrating both natural language and images in instructions. VLN-MP not only maintains backward compatibility by effectively handling text-only prompts but also consistently shows advantages with different quantities and relevance of visual prompts. Possible forms of visual prompts include both exact and similar object images, providing adaptability and versatility in diverse navigation scenarios. To evaluate VLN-MP under a unified framework, we implement a new benchmark that offers: (1) a training-free pipeline to transform textual instructions into multi-modal forms with landmark images; (2) diverse datasets with multi-modal instructions for different downstream tasks; (3) a novel module designed to process various image prompts for seamless integration with state-of-the-art VLN models. Extensive experiments on four VLN benchmarks (R2R, RxR, REVERIE, CVDN) show that incorporating visual prompts significantly boosts navigation performance. While maintaining efficiency with text-only prompts, VLN-MP enables agents to navigate in the pre-explore setting and outperform text-based models, showing its broader applicability.
Read more6/5/2024

0
Vision-Language Navigation with Continual Learning
Zhiyuan Li, Yanfeng Lv, Ziqin Tu, Di Shang, Hong Qiao
Vision-language navigation (VLN) is a critical domain within embedded intelligence, requiring agents to navigate 3D environments based on natural language instructions. Traditional VLN research has focused on improving environmental understanding and decision accuracy. However, these approaches often exhibit a significant performance gap when agents are deployed in novel environments, mainly due to the limited diversity of training data. Expanding datasets to cover a broader range of environments is impractical and costly. We propose the Vision-Language Navigation with Continual Learning (VLNCL) paradigm to address this challenge. In this paradigm, agents incrementally learn new environments while retaining previously acquired knowledge. VLNCL enables agents to maintain an environmental memory and extract relevant knowledge, allowing rapid adaptation to new environments while preserving existing information. We introduce a novel dual-loop scenario replay method (Dual-SR) inspired by brain memory replay mechanisms integrated with VLN agents. This method facilitates consolidating past experiences and enhances generalization across new tasks. By utilizing a multi-scenario memory buffer, the agent efficiently organizes and replays task memories, thereby bolstering its ability to adapt quickly to new environments and mitigating catastrophic forgetting. Our work pioneers continual learning in VLN agents, introducing a novel experimental setup and evaluation metrics. We demonstrate the effectiveness of our approach through extensive evaluations and establish a benchmark for the VLNCL paradigm. Comparative experiments with existing continual learning and VLN methods show significant improvements, achieving state-of-the-art performance in continual learning ability and highlighting the potential of our approach in enabling rapid adaptation while preserving prior knowledge.
Read more9/24/2024
0
Narrowing the Gap between Vision and Action in Navigation
Yue Zhang, Parisa Kordjamshidi
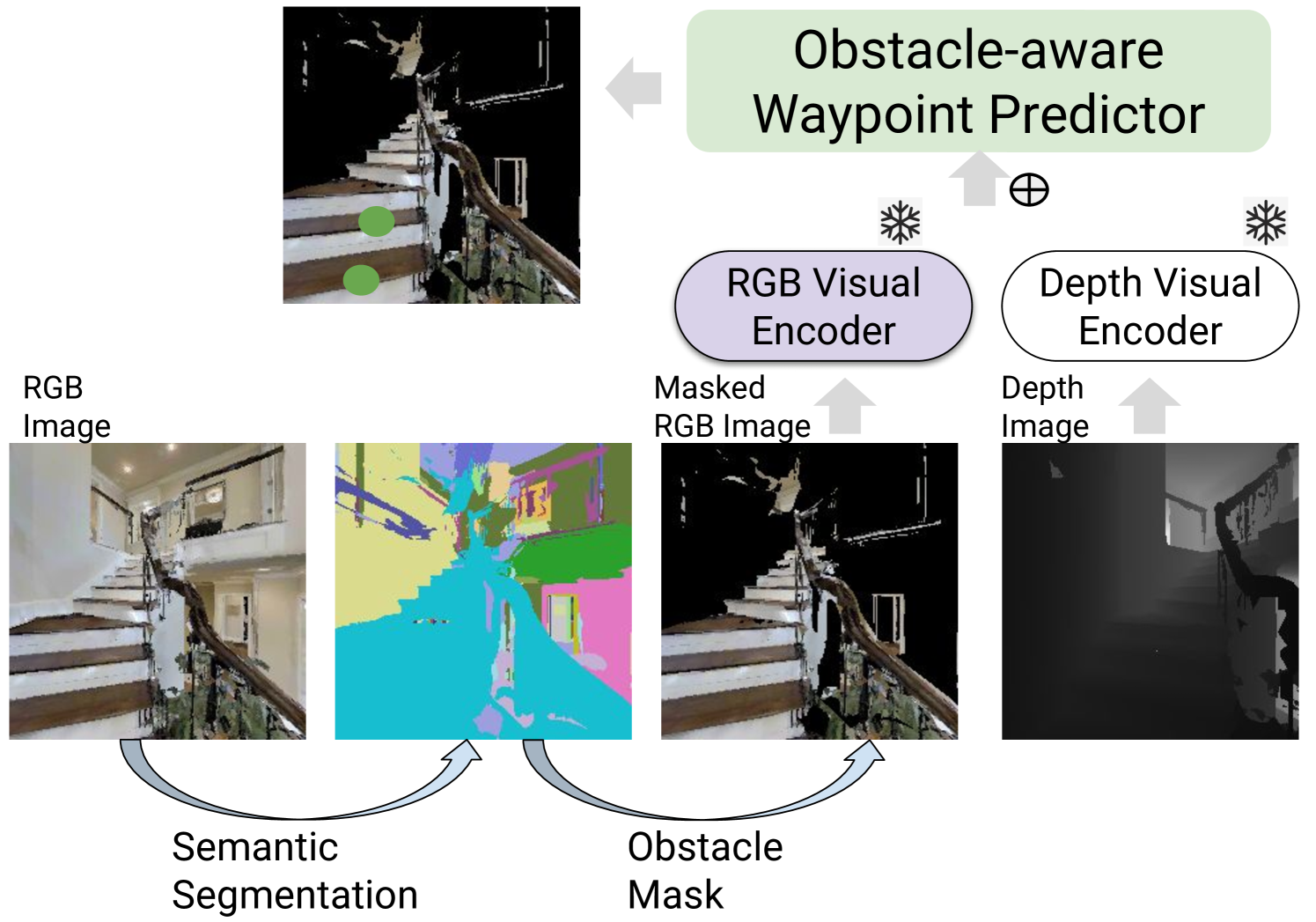
The existing methods for Vision and Language Navigation in the Continuous Environment (VLN-CE) commonly incorporate a waypoint predictor to discretize the environment. This simplifies the navigation actions into a view selection task and improves navigation performance significantly compared to direct training using low-level actions. However, the VLN-CE agents are still far from the real robots since there are gaps between their visual perception and executed actions. First, VLN-CE agents that discretize the visual environment are primarily trained with high-level view selection, which causes them to ignore crucial spatial reasoning within the low-level action movements. Second, in these models, the existing waypoint predictors neglect object semantics and their attributes related to passibility, which can be informative in indicating the feasibility of actions. To address these two issues, we introduce a low-level action decoder jointly trained with high-level action prediction, enabling the current VLN agent to learn and ground the selected visual view to the low-level controls. Moreover, we enhance the current waypoint predictor by utilizing visual representations containing rich semantic information and explicitly masking obstacles based on humans' prior knowledge about the feasibility of actions. Empirically, our agent can improve navigation performance metrics compared to the strong baselines on both high-level and low-level actions.
Read more8/21/2024