XLD: A Cross-Lane Dataset for Benchmarking Novel Driving View Synthesis
2406.18360
0
0

Abstract
Thoroughly testing autonomy systems is crucial in the pursuit of safe autonomous driving vehicles. It necessitates creating safety-critical scenarios that go beyond what can be safely collected from real-world data, as many of these scenarios occur infrequently on public roads. However, the evaluation of most existing NVS methods relies on sporadic sampling of image frames from the training data, comparing the rendered images with ground truth images using metrics. Unfortunately, this evaluation protocol falls short of meeting the actual requirements in closed-loop simulations. Specifically, the true application demands the capability to render novel views that extend beyond the original trajectory (such as cross-lane views), which are challenging to capture in the real world. To address this, this paper presents a novel driving view synthesis dataset and benchmark specifically designed for autonomous driving simulations. This dataset is unique as it includes testing images captured by deviating from the training trajectory by 1-4 meters. It comprises six sequences encompassing various time and weather conditions. Each sequence contains 450 training images, 150 testing images, and their corresponding camera poses and intrinsic parameters. Leveraging this novel dataset, we establish the first realistic benchmark for evaluating existing NVS approaches under front-only and multi-camera settings. The experimental findings underscore the significant gap that exists in current approaches, revealing their inadequate ability to fulfill the demanding prerequisites of cross-lane or closed-loop simulation. Our dataset is released publicly at the project page: https://3d-aigc.github.io/XLD/.
Create account to get full access
Overview
- This paper introduces a new dataset called XLD (Cross-Lane Dataset) for benchmarking novel driving view synthesis.
- Driving view synthesis is the task of generating a novel viewpoint of a driving scene from a given set of input views.
- The XLD dataset contains images and annotations for multi-lane driving scenarios, which can be used to evaluate the performance of driving view synthesis models.
- The dataset includes various challenging scenarios such as occluded and distant vehicles, complex road structures, and diverse weather conditions.
Plain English Explanation
The researchers have created a new dataset called XLD that can be used to test and compare different AI models for a task called "driving view synthesis". This task is about generating a new view of a driving scene, like what you might see from a different camera angle, based on the images from the original camera(s).
The key idea behind the XLD dataset is that it contains a wide variety of challenging driving scenarios, like when vehicles are partially blocked from view or when the road is complex with multiple lanes. This makes it a good benchmark to evaluate how well different AI models can handle these tricky real-world driving situations when generating novel views.
The researchers argue that existing datasets for driving view synthesis don't capture this level of complexity, so the XLD dataset fills an important gap. By having a more realistic and diverse dataset, researchers can get a better sense of which AI models work best for this task in practical applications like autonomous vehicles.
Technical Explanation
The XLD dataset contains images and annotations for multi-lane driving scenarios, which can be used to evaluate the performance of driving view synthesis models. The dataset includes various challenging scenarios such as occluded and distant vehicles, complex road structures, and diverse weather conditions.
To capture these diverse driving scenes, the researchers used a multi-camera setup in a real vehicle to record footage from different viewpoints. This allows the dataset to provide the input views needed for driving view synthesis, as well as the target views that models should try to generate.
In addition to the image data, the XLD dataset also includes 3D annotations of the scene, such as the locations of vehicles, road structure, and other relevant objects. These annotations can be used to facilitate more advanced driving view synthesis approaches that leverage 3D information.
The researchers demonstrate the value of the XLD dataset by evaluating several state-of-the-art driving view synthesis models on the benchmark. Their results show that the XLD dataset poses significant challenges that existing models struggle with, highlighting the need for further advancements in this field.
Critical Analysis
The XLD dataset represents an important contribution to the field of driving view synthesis by providing a more realistic and challenging benchmark. However, the paper does not fully explore the limitations of the dataset or the models evaluated.
For example, the dataset is still constrained to a single vehicle's viewpoint, and it is unclear how well the models would generalize to a broader range of driving scenarios or camera setups. Additionally, the paper does not delve into the potential biases or artifacts in the dataset that could affect model performance.
Furthermore, the critical analysis of the model results is relatively superficial, focusing mainly on the performance gaps between models. More in-depth discussions of the underlying strengths, weaknesses, and failure modes of the different approaches could provide greater insights for the research community.
Conclusion
The XLD dataset introduces a new benchmark for driving view synthesis that captures a more diverse and challenging set of real-world driving scenarios. By providing this dataset, the researchers aim to spur further advancements in this important computer vision task, which has applications in areas like autonomous vehicles and augmented reality.
The dataset's focus on multi-lane driving, occluded vehicles, and complex road structures represents a significant step forward in benchmarking the capabilities of driving view synthesis models. While the initial results show that existing models still struggle with the XLD dataset's challenges, the availability of this new benchmark should drive the development of more robust and capable approaches in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LanEvil: Benchmarking the Robustness of Lane Detection to Environmental Illusions
Tianyuan Zhang, Lu Wang, Hainan Li, Yisong Xiao, Siyuan Liang, Aishan Liu, Xianglong Liu, Dacheng Tao
0
0
Lane detection (LD) is an essential component of autonomous driving systems, providing fundamental functionalities like adaptive cruise control and automated lane centering. Existing LD benchmarks primarily focus on evaluating common cases, neglecting the robustness of LD models against environmental illusions such as shadows and tire marks on the road. This research gap poses significant safety challenges since these illusions exist naturally in real-world traffic situations. For the first time, this paper studies the potential threats caused by these environmental illusions to LD and establishes the first comprehensive benchmark LanEvil for evaluating the robustness of LD against this natural corruption. We systematically design 14 prevalent yet critical types of environmental illusions (e.g., shadow, reflection) that cover a wide spectrum of real-world influencing factors in LD tasks. Based on real-world environments, we create 94 realistic and customizable 3D cases using the widely used CARLA simulator, resulting in a dataset comprising 90,292 sampled images. Through extensive experiments, we benchmark the robustness of popular LD methods using LanEvil, revealing substantial performance degradation (-5.37% Accuracy and -10.70% F1-Score on average), with shadow effects posing the greatest risk (-7.39% Accuracy). Additionally, we assess the performance of commercial auto-driving systems OpenPilot and Apollo through collaborative simulations, demonstrating that proposed environmental illusions can lead to incorrect decisions and potential traffic accidents. To defend against environmental illusions, we propose the Attention Area Mixing (AAM) approach using hard examples, which witness significant robustness improvement (+3.76%) under illumination effects. We hope our paper can contribute to advancing more robust auto-driving systems in the future. Website: https://lanevil.github.io/.
6/12/2024
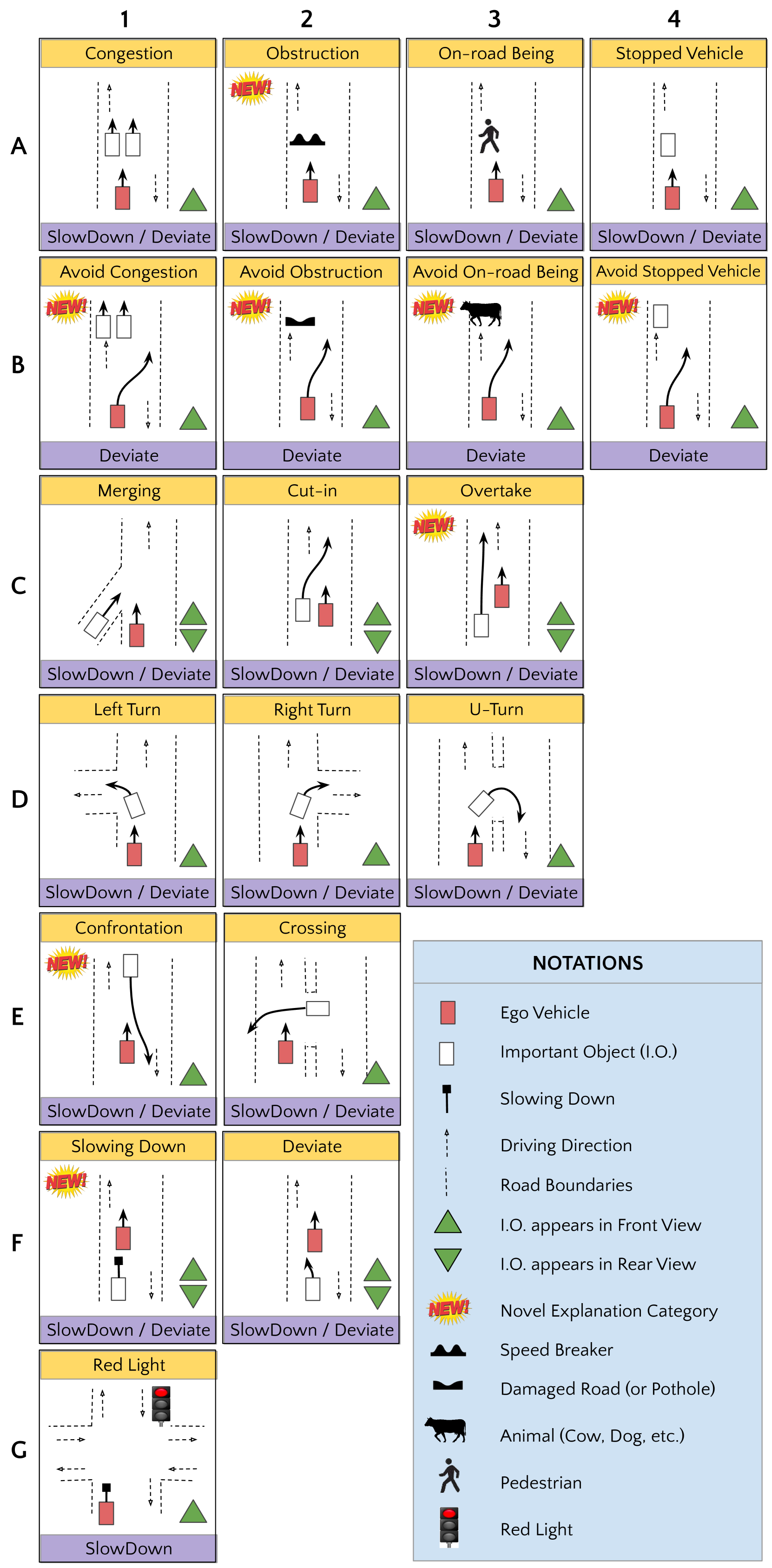
IDD-X: A Multi-View Dataset for Ego-relative Important Object Localization and Explanation in Dense and Unstructured Traffic
Chirag Parikh, Rohit Saluja, C. V. Jawahar, Ravi Kiran Sarvadevabhatla
0
0
Intelligent vehicle systems require a deep understanding of the interplay between road conditions, surrounding entities, and the ego vehicle's driving behavior for safe and efficient navigation. This is particularly critical in developing countries where traffic situations are often dense and unstructured with heterogeneous road occupants. Existing datasets, predominantly geared towards structured and sparse traffic scenarios, fall short of capturing the complexity of driving in such environments. To fill this gap, we present IDD-X, a large-scale dual-view driving video dataset. With 697K bounding boxes, 9K important object tracks, and 1-12 objects per video, IDD-X offers comprehensive ego-relative annotations for multiple important road objects covering 10 categories and 19 explanation label categories. The dataset also incorporates rearview information to provide a more complete representation of the driving environment. We also introduce custom-designed deep networks aimed at multiple important object localization and per-object explanation prediction. Overall, our dataset and introduced prediction models form the foundation for studying how road conditions and surrounding entities affect driving behavior in complex traffic situations.
4/15/2024
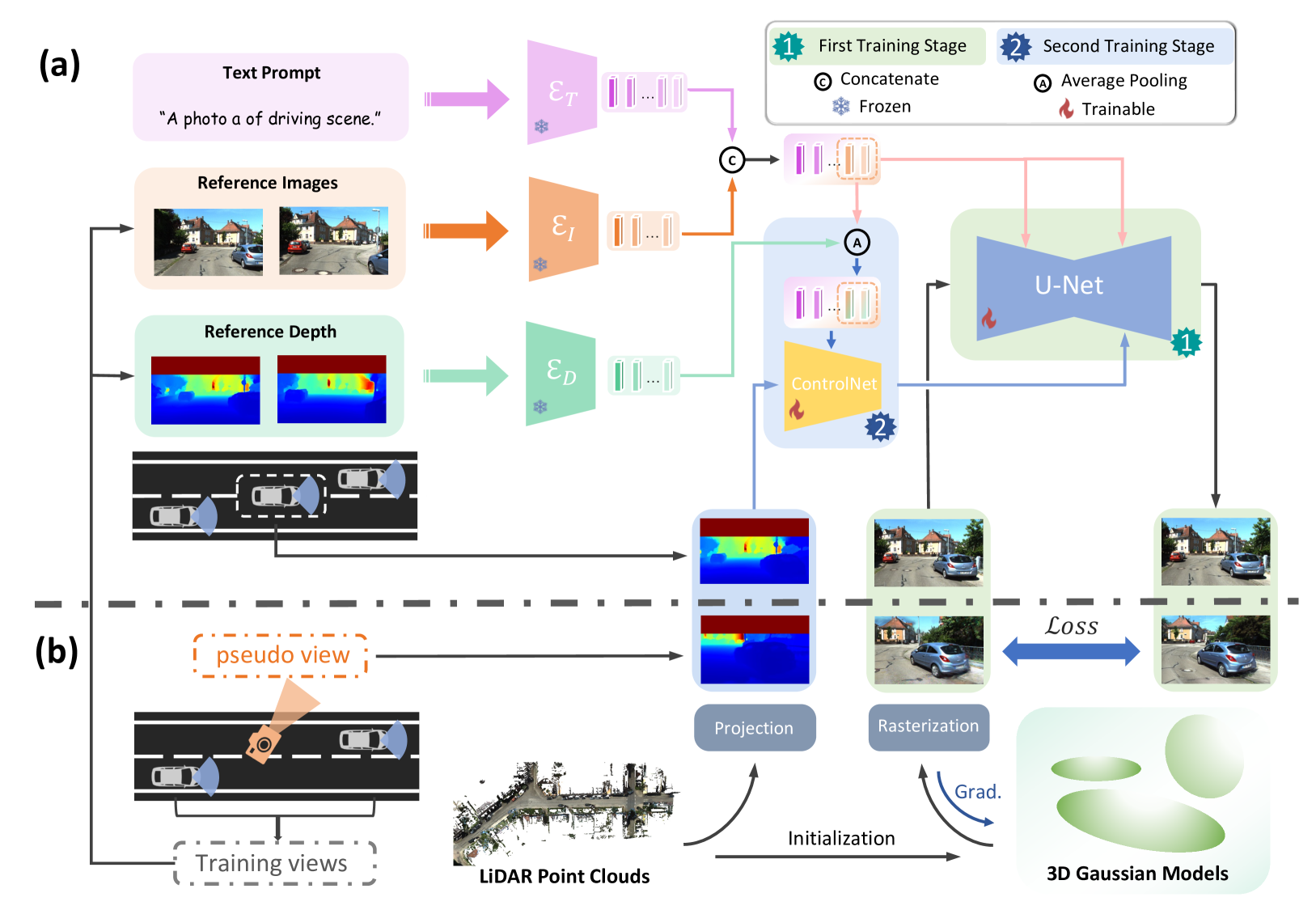
SGD: Street View Synthesis with Gaussian Splatting and Diffusion Prior
Zhongrui Yu, Haoran Wang, Jinze Yang, Hanzhang Wang, Zeke Xie, Yunfeng Cai, Jiale Cao, Zhong Ji, Mingming Sun
0
0
Novel View Synthesis (NVS) for street scenes play a critical role in the autonomous driving simulation. The current mainstream technique to achieve it is neural rendering, such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS). Although thrilling progress has been made, when handling street scenes, current methods struggle to maintain rendering quality at the viewpoint that deviates significantly from the training viewpoints. This issue stems from the sparse training views captured by a fixed camera on a moving vehicle. To tackle this problem, we propose a novel approach that enhances the capacity of 3DGS by leveraging prior from a Diffusion Model along with complementary multi-modal data. Specifically, we first fine-tune a Diffusion Model by adding images from adjacent frames as condition, meanwhile exploiting depth data from LiDAR point clouds to supply additional spatial information. Then we apply the Diffusion Model to regularize the 3DGS at unseen views during training. Experimental results validate the effectiveness of our method compared with current state-of-the-art models, and demonstrate its advance in rendering images from broader views.
4/1/2024
👁️
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, Hang Zhao
0
0
A primary hurdle of autonomous driving in urban environments is understanding complex and long-tail scenarios, such as challenging road conditions and delicate human behaviors. We introduce DriveVLM, an autonomous driving system leveraging Vision-Language Models (VLMs) for enhanced scene understanding and planning capabilities. DriveVLM integrates a unique combination of reasoning modules for scene description, scene analysis, and hierarchical planning. Furthermore, recognizing the limitations of VLMs in spatial reasoning and heavy computational requirements, we propose DriveVLM-Dual, a hybrid system that synergizes the strengths of DriveVLM with the traditional autonomous driving pipeline. Experiments on both the nuScenes dataset and our SUP-AD dataset demonstrate the efficacy of DriveVLM and DriveVLM-Dual in handling complex and unpredictable driving conditions. Finally, we deploy the DriveVLM-Dual on a production vehicle, verifying it is effective in real-world autonomous driving environments.
6/26/2024