IDD-X: A Multi-View Dataset for Ego-relative Important Object Localization and Explanation in Dense and Unstructured Traffic
2404.08561
0
0
Abstract
Intelligent vehicle systems require a deep understanding of the interplay between road conditions, surrounding entities, and the ego vehicle's driving behavior for safe and efficient navigation. This is particularly critical in developing countries where traffic situations are often dense and unstructured with heterogeneous road occupants. Existing datasets, predominantly geared towards structured and sparse traffic scenarios, fall short of capturing the complexity of driving in such environments. To fill this gap, we present IDD-X, a large-scale dual-view driving video dataset. With 697K bounding boxes, 9K important object tracks, and 1-12 objects per video, IDD-X offers comprehensive ego-relative annotations for multiple important road objects covering 10 categories and 19 explanation label categories. The dataset also incorporates rearview information to provide a more complete representation of the driving environment. We also introduce custom-designed deep networks aimed at multiple important object localization and per-object explanation prediction. Overall, our dataset and introduced prediction models form the foundation for studying how road conditions and surrounding entities affect driving behavior in complex traffic situations.
Create account to get full access
Overview
- This paper introduces the IDD-X dataset, a novel multi-view dataset for studying ego-relative important object localization and explanation in dense and unstructured traffic scenarios.
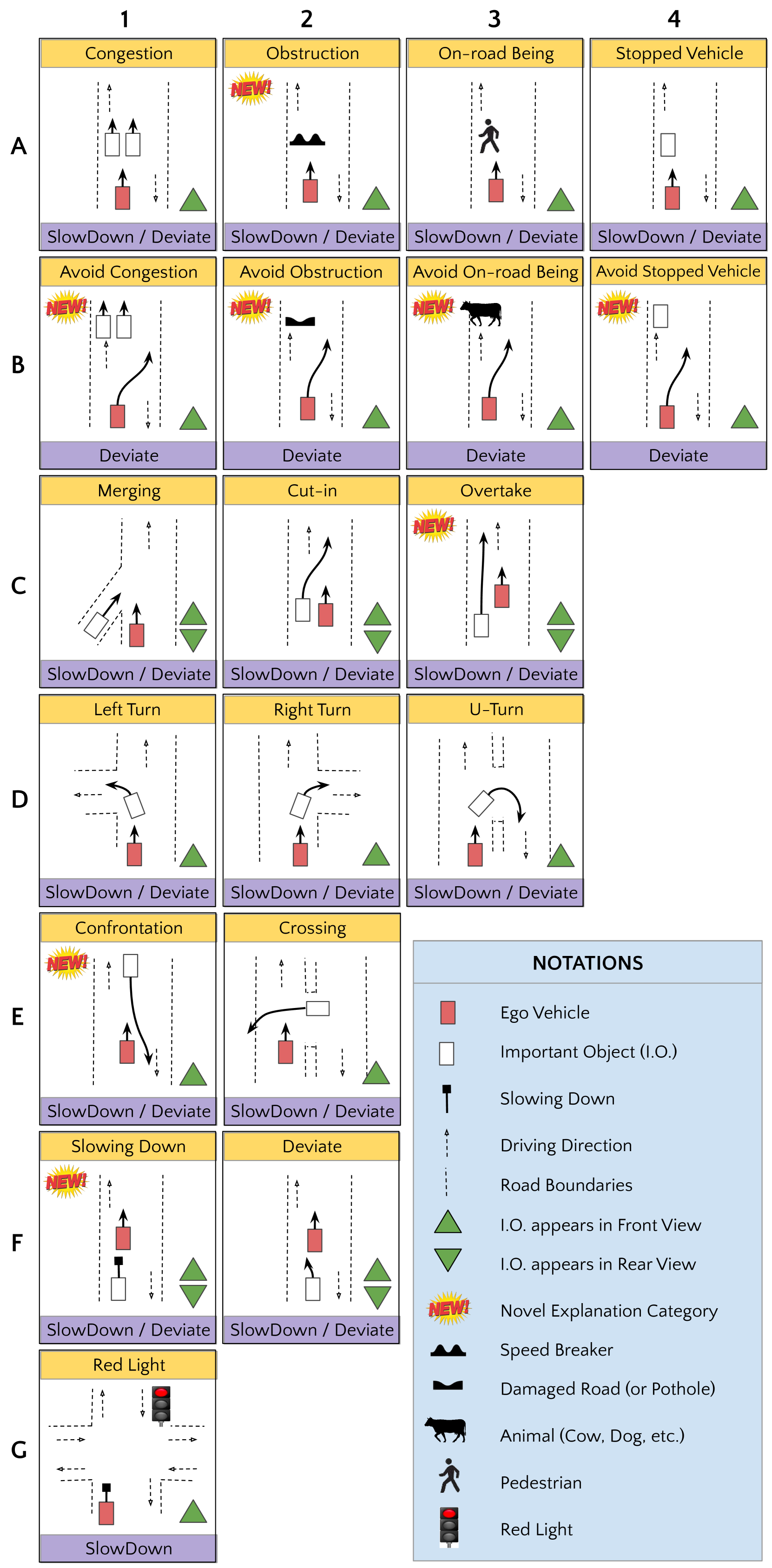
- The dataset provides rich sensor data, including RGB, depth, and semantic segmentation, along with annotations for important objects from the perspective of the ego-vehicle.
- The key contributions of this work are the dataset creation, benchmark tasks, and baseline models for important object detection and explanation.
Plain English Explanation
The research paper presents a new dataset called IDD-X that is designed to help self-driving cars and other autonomous vehicles better understand their surroundings, especially in busy and unstructured traffic environments. The dataset includes various types of sensor data, such as camera images, depth information, and semantic labels, all from the perspective of the vehicle itself.
The main purpose of this dataset is to allow AI systems to not only detect objects around the vehicle, but also determine which of those objects are most important or relevant from the vehicle's point of view. This could be crucial for making safe driving decisions, as the vehicle needs to be able to prioritize and focus on the objects that pose the greatest risk or opportunity.
The IDD-X dataset builds on previous efforts like the 360x Panoptic Multi-Modal Scene Understanding Dataset and the SGV3D Towards Scenario Generalization in Vision-Based Roadside 3D Object Detection dataset, which have also aimed to provide rich data for training and evaluating autonomous vehicle perception systems.
Technical Explanation
The IDD-X dataset is a multi-view dataset that captures data from the perspective of the ego-vehicle, including RGB images, depth maps, and semantic segmentation. The dataset was collected in dense and unstructured traffic environments in India, providing a challenging scenario for autonomous driving systems.
The key contributions of this work are:
-
Dataset Creation: The authors collected a large-scale dataset with over 100,000 frames across multiple views, including front-facing, side-facing, and rear-facing cameras. The dataset also includes annotations for important objects, which are defined as objects that are relevant to the ego-vehicle's driving task.
-
Benchmark Tasks: The authors propose two main benchmark tasks using the IDD-X dataset: (1) ego-relative important object localization, which aims to detect and localize important objects around the vehicle, and (2) important object explanation, which aims to provide an interpretable explanation for why certain objects are deemed important.
-
Baseline Models: The authors provide baseline models for both the important object localization and explanation tasks. For localization, they use a deep learning-based object detection model, and for explanation, they use a conditional generative adversarial network (cGAN) approach to generate natural language explanations.
The dataset and benchmark tasks presented in this work are intended to advance research in autonomous vehicle perception, particularly in challenging traffic scenarios where the vehicle needs to quickly identify and respond to the most critical objects in its surroundings.
Critical Analysis
The IDD-X dataset and associated tasks represent a valuable contribution to the field of autonomous driving and computer vision. By focusing on the identification and explanation of important objects from the ego-vehicle's perspective, the authors are addressing a crucial problem that current perception systems often struggle with.
However, the authors acknowledge several limitations and areas for future research:
-
Sensor Coverage: While the dataset includes multiple camera views, it does not incorporate other sensor modalities like radar or lidar, which could provide additional information about the environment.
-
Annotation Quality: The authors note that the important object annotations were manually labeled, which could introduce some subjectivity and inconsistencies. Automated or semi-automated annotation approaches may be needed to scale up the dataset.
-
Generalization: The dataset is currently limited to the specific traffic conditions in India, and further research is needed to understand how well the models and benchmarks generalize to other regions and scenarios.
Despite these limitations, the IDD-X dataset and associated tasks represent an important step forward in advancing autonomous vehicle perception and decision-making capabilities, particularly in complex traffic environments. The work also highlights the value of ego-centric, multi-view datasets for training robust and explainable AI systems.
Conclusion
The IDD-X dataset and benchmarks introduced in this paper address a critical challenge in autonomous driving: the ability to quickly identify and understand the most important objects in a vehicle's surroundings, especially in dense and unstructured traffic scenarios. By providing a rich, multi-view dataset and establishing baselines for important object localization and explanation, the authors have laid the groundwork for future research that could significantly improve the safety and reliability of self-driving cars and other autonomous vehicles.
The work also underscores the importance of developing AI systems that can not only detect objects, but also provide interpretable explanations for their decisions. This ability to "explain" the reasoning behind important object detection could be crucial for building trust and acceptance of autonomous vehicle technology among end-users.
Overall, the IDD-X dataset and associated research represent an important contribution to the field of autonomous driving, with the potential to drive meaningful progress in this rapidly evolving and high-stakes domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

XLD: A Cross-Lane Dataset for Benchmarking Novel Driving View Synthesis
Hao Li, Ming Yuan, Yan Zhang, Chenming Wu, Chen Zhao, Chunyu Song, Haocheng Feng, Errui Ding, Dingwen Zhang, Jingdong Wang
0
0
Thoroughly testing autonomy systems is crucial in the pursuit of safe autonomous driving vehicles. It necessitates creating safety-critical scenarios that go beyond what can be safely collected from real-world data, as many of these scenarios occur infrequently on public roads. However, the evaluation of most existing NVS methods relies on sporadic sampling of image frames from the training data, comparing the rendered images with ground truth images using metrics. Unfortunately, this evaluation protocol falls short of meeting the actual requirements in closed-loop simulations. Specifically, the true application demands the capability to render novel views that extend beyond the original trajectory (such as cross-lane views), which are challenging to capture in the real world. To address this, this paper presents a novel driving view synthesis dataset and benchmark specifically designed for autonomous driving simulations. This dataset is unique as it includes testing images captured by deviating from the training trajectory by 1-4 meters. It comprises six sequences encompassing various time and weather conditions. Each sequence contains 450 training images, 150 testing images, and their corresponding camera poses and intrinsic parameters. Leveraging this novel dataset, we establish the first realistic benchmark for evaluating existing NVS approaches under front-only and multi-camera settings. The experimental findings underscore the significant gap that exists in current approaches, revealing their inadequate ability to fulfill the demanding prerequisites of cross-lane or closed-loop simulation. Our dataset is released publicly at the project page: https://3d-aigc.github.io/XLD/.
6/28/2024

Collaborative Perception Datasets in Autonomous Driving: A Survey
Melih Yazgan, Mythra Varun Akkanapragada, J. Marius Zoellner
0
0
This survey offers a comprehensive examination of collaborative perception datasets in the context of Vehicle-to-Infrastructure (V2I), Vehicle-to-Vehicle (V2V), and Vehicle-to-Everything (V2X). It highlights the latest developments in large-scale benchmarks that accelerate advancements in perception tasks for autonomous vehicles. The paper systematically analyzes a variety of datasets, comparing them based on aspects such as diversity, sensor setup, quality, public availability, and their applicability to downstream tasks. It also highlights the key challenges such as domain shift, sensor setup limitations, and gaps in dataset diversity and availability. The importance of addressing privacy and security concerns in the development of datasets is emphasized, regarding data sharing and dataset creation. The conclusion underscores the necessity for comprehensive, globally accessible datasets and collaborative efforts from both technological and research communities to overcome these challenges and fully harness the potential of autonomous driving.
4/23/2024
💬
D2E-An Autonomous Decision-making Dataset involving Driver States and Human Evaluation
Zehong Ke, Yanbo Jiang, Yuning Wang, Hao Cheng, Jinhao Li, Jianqiang Wang
0
0
With the advancement of deep learning technology, data-driven methods are increasingly used in the decision-making of autonomous driving, and the quality of datasets greatly influenced the model performance. Although current datasets have made significant progress in the collection of vehicle and environment data, emphasis on human-end data including the driver states and human evaluation is not sufficient. In addition, existing datasets consist mostly of simple scenarios such as car following, resulting in low interaction levels. In this paper, we introduce the Driver to Evaluation dataset (D2E), an autonomous decision-making dataset that contains data on driver states, vehicle states, environmental situations, and evaluation scores from human reviewers, covering a comprehensive process of vehicle decision-making. Apart from regular agents and surrounding environment information, we not only collect driver factor data including first-person view videos, physiological signals, and eye attention data, but also provide subjective rating scores from 40 human volunteers. The dataset is mixed of driving simulator scenes and real-road ones. High-interaction situations are designed and filtered to ensure behavior diversity. Through data organization, analysis, and preprocessing, D2E contains over 1100 segments of interactive driving case data covering from human driver factor to evaluation results, supporting the development of data-driven decision-making related algorithms.
6/5/2024

360+x: A Panoptic Multi-modal Scene Understanding Dataset
Hao Chen, Yuqi Hou, Chenyuan Qu, Irene Testini, Xiaohan Hong, Jianbo Jiao
0
0
Human perception of the world is shaped by a multitude of viewpoints and modalities. While many existing datasets focus on scene understanding from a certain perspective (e.g. egocentric or third-person views), our dataset offers a panoptic perspective (i.e. multiple viewpoints with multiple data modalities). Specifically, we encapsulate third-person panoramic and front views, as well as egocentric monocular/binocular views with rich modalities including video, multi-channel audio, directional binaural delay, location data and textual scene descriptions within each scene captured, presenting comprehensive observation of the world. Figure 1 offers a glimpse of all 28 scene categories of our 360+x dataset. To the best of our knowledge, this is the first database that covers multiple viewpoints with multiple data modalities to mimic how daily information is accessed in the real world. Through our benchmark analysis, we presented 5 different scene understanding tasks on the proposed 360+x dataset to evaluate the impact and benefit of each data modality and perspective in panoptic scene understanding. We hope this unique dataset could broaden the scope of comprehensive scene understanding and encourage the community to approach these problems from more diverse perspectives.
4/9/2024