Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
2406.03736
0
0
Abstract
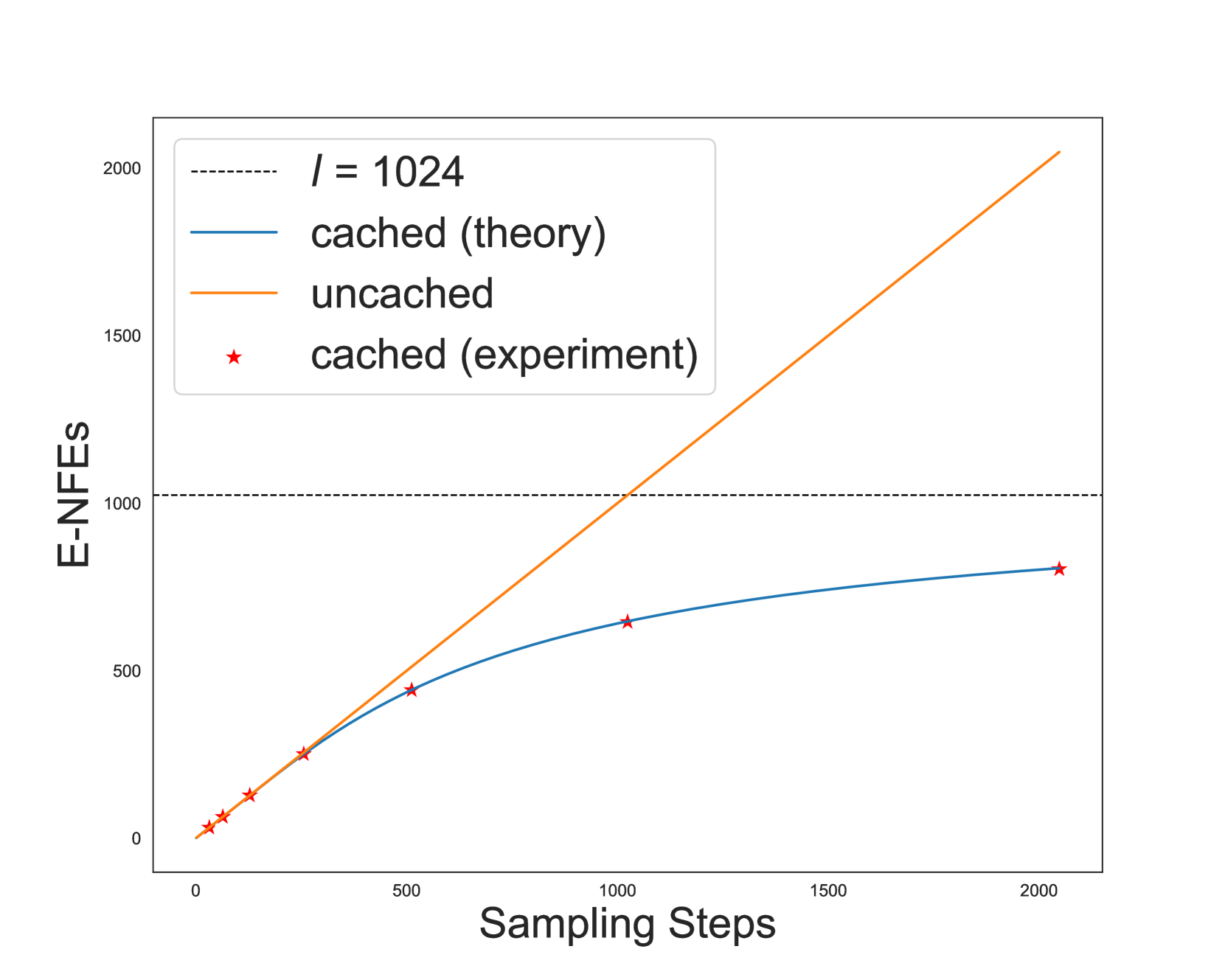
Discrete diffusion models with absorbing processes have shown promise in language modeling. The key quantities to be estimated are the ratios between the marginal probabilities of two transitive states at all timesteps, called the concrete score. In this paper, we reveal that the concrete score in absorbing diffusion can be expressed as conditional probabilities of clean data, multiplied by a time-dependent scalar in an analytic form. Motivated by the finding, we propose reparameterized absorbing discrete diffusion (RADD), a dedicated diffusion model that characterizes the time-independent conditional probabilities. Besides its simplicity, RADD can reduce the number of function evaluations (NFEs) by caching the output of the time-independent network when the noisy sample remains unchanged in a sampling interval. Empirically, RADD is up to 3.5 times faster while consistently achieving a better performance than the strongest baseline. Built upon the new factorization of the concrete score, we further prove a surprising result that the exact likelihood of absorbing diffusion can be rewritten to a simple form (named denoising cross-entropy) and then estimated efficiently by the Monte Carlo method. The resulting approach also applies to the original parameterization of the concrete score. It significantly advances the state-of-the-art discrete diffusion on 5 zero-shot language modeling benchmarks (measured by perplexity) at the GPT-2 scale.
Create account to get full access
Overview
- This paper explores a new technique called "absorbing discrete diffusion" that can be used to model the conditional distributions of clean data.
- The authors show that this approach can outperform existing methods, such as Simplified Generalized Masked Diffusion for Discrete Data, Distilling Diffusion Models into Conditional GANs, and Robust Classification via a Single Diffusion Model.
- The key ideas behind this technique and its potential applications are explained in detail below.
Plain English Explanation
The paper introduces a new machine learning method called "absorbing discrete diffusion" that can be used to model the underlying patterns and distributions in clean data. This is useful for a variety of applications, such as generating realistic synthetic data, filling in missing values, and improving the performance of machine learning models.
The core idea is to start with noisy data and gradually "clean" it by applying a series of small, controlled transformations. This process, known as diffusion, gradually reveals the true structure of the clean data. The authors show that this approach can capture the conditional distributions of the clean data more effectively than previous methods.
To illustrate, imagine you have a collection of images of cats, and you want to build a model that can generate new cat images that look just as realistic. The absorbing discrete diffusion approach would start with a set of very noisy, distorted cat images, and then slowly refine them, step-by-step, until they converge to clean, realistic cat images. By studying how the model transforms the noisy images into the clean ones, you can learn the underlying patterns and distributions of the clean cat data.
This technique has several advantages over alternative approaches. It is more flexible, as it can be applied to a wide range of data types, and it is also more robust, as it can handle noisy or corrupted input data. Additionally, the authors show that it can outperform other state-of-the-art methods on a variety of benchmark tasks.
Technical Explanation
The core idea behind absorbing discrete diffusion is to model the clean data distribution as a sequence of gradual transformations, starting from a noisy initial state. This is done by defining a Markov chain, where each step of the chain corresponds to a small, controlled transformation of the data.
The authors show that this Markov chain can be designed in such a way that, as the number of steps increases, the distribution of the transformed data converges to the true, clean data distribution. This is achieved by carefully designing the transition probabilities of the Markov chain, such that they satisfy certain technical conditions.
Importantly, the authors demonstrate that this absorbing discrete diffusion approach can be applied to a wide range of data types, including both continuous and discrete data. They also show that it can outperform other state-of-the-art methods, such as Missing U-Efficient Diffusion Models and Non-Asymptotic Convergence of Discrete-Time Diffusion Models, on a variety of benchmark tasks.
Critical Analysis
The paper presents a novel and promising technique for modeling the conditional distributions of clean data. The authors have done a thorough job of evaluating their approach against state-of-the-art methods and demonstrating its advantages.
However, there are a few potential limitations and areas for further research. First, the authors only provide theoretical guarantees for the convergence of their Markov chain, but do not give a detailed analysis of the convergence rate. Understanding the convergence rate would be important for practical applications, where the number of diffusion steps may be limited.
Additionally, the authors do not explore the potential sensitivity of their approach to hyperparameter choices or the quality of the initial noisy data. Understanding the robustness of the method to these factors would be important for its real-world deployment.
Finally, while the authors show that their approach can outperform other methods on a variety of benchmark tasks, it would be valuable to see more extensive empirical evaluations, particularly on large-scale, real-world datasets and applications.
Conclusion
Overall, this paper presents a novel and promising approach to modeling the conditional distributions of clean data using an absorbing discrete diffusion process. The authors have demonstrated its theoretical advantages and empirical performance, and the technique has the potential to be a valuable tool for a variety of machine learning applications, such as data generation, imputation, and classification.
While there are a few areas for further research, the work represents an important contribution to the field of diffusion-based generative modeling and is likely to inspire further developments in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, Stefano Ermon
0
0
Despite their groundbreaking performance for many generative modeling tasks, diffusion models have fallen short on discrete data domains such as natural language. Crucially, standard diffusion models rely on the well-established theory of score matching, but efforts to generalize this to discrete structures have not yielded the same empirical gains. In this work, we bridge this gap by proposing score entropy, a novel loss that naturally extends score matching to discrete spaces, integrates seamlessly to build discrete diffusion models, and significantly boosts performance. Experimentally, we test our Score Entropy Discrete Diffusion models (SEDD) on standard language modeling tasks. For comparable model sizes, SEDD beats existing language diffusion paradigms (reducing perplexity by $25$-$75$%) and is competitive with autoregressive models, in particular outperforming GPT-2. Furthermore, compared to autoregressive mdoels, SEDD generates faithful text without requiring distribution annealing techniques like temperature scaling (around $6$-$8times$ better generative perplexity than un-annealed GPT-2), can trade compute and quality (similar quality with $32times$ fewer network evaluations), and enables controllable infilling (matching nucleus sampling quality while enabling other strategies besides left to right prompting).
6/10/2024
Simplified and Generalized Masked Diffusion for Discrete Data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, Michalis K. Titsias
0
0
Masked (or absorbing) diffusion is actively explored as an alternative to autoregressive models for generative modeling of discrete data. However, existing work in this area has been hindered by unnecessarily complex model formulations and unclear relationships between different perspectives, leading to suboptimal parameterization, training objectives, and ad hoc adjustments to counteract these issues. In this work, we aim to provide a simple and general framework that unlocks the full potential of masked diffusion models. We show that the continuous-time variational objective of masked diffusion models is a simple weighted integral of cross-entropy losses. Our framework also enables training generalized masked diffusion models with state-dependent masking schedules. When evaluated by perplexity, our models trained on OpenWebText surpass prior diffusion language models at GPT-2 scale and demonstrate superior performance on 4 out of 5 zero-shot language modeling tasks. Furthermore, our models vastly outperform previous discrete diffusion models on pixel-level image modeling, achieving 2.78~(CIFAR-10) and 3.42 (ImageNet 64$times$64) bits per dimension that are comparable or better than autoregressive models of similar sizes.
6/7/2024
📉
Distilling Diffusion Models into Conditional GANs
Minguk Kang, Richard Zhang, Connelly Barnes, Sylvain Paris, Suha Kwak, Jaesik Park, Eli Shechtman, Jun-Yan Zhu, Taesung Park
0
0
We propose a method to distill a complex multistep diffusion model into a single-step conditional GAN student model, dramatically accelerating inference, while preserving image quality. Our approach interprets diffusion distillation as a paired image-to-image translation task, using noise-to-image pairs of the diffusion model's ODE trajectory. For efficient regression loss computation, we propose E-LatentLPIPS, a perceptual loss operating directly in diffusion model's latent space, utilizing an ensemble of augmentations. Furthermore, we adapt a diffusion model to construct a multi-scale discriminator with a text alignment loss to build an effective conditional GAN-based formulation. E-LatentLPIPS converges more efficiently than many existing distillation methods, even accounting for dataset construction costs. We demonstrate that our one-step generator outperforms cutting-edge one-step diffusion distillation models -- DMD, SDXL-Turbo, and SDXL-Lightning -- on the zero-shot COCO benchmark.
6/17/2024
🏷️
Robust Classification via a Single Diffusion Model
Huanran Chen, Yinpeng Dong, Zhengyi Wang, Xiao Yang, Chengqi Duan, Hang Su, Jun Zhu
0
0
Diffusion models have been applied to improve adversarial robustness of image classifiers by purifying the adversarial noises or generating realistic data for adversarial training. However, diffusion-based purification can be evaded by stronger adaptive attacks while adversarial training does not perform well under unseen threats, exhibiting inevitable limitations of these methods. To better harness the expressive power of diffusion models, this paper proposes Robust Diffusion Classifier (RDC), a generative classifier that is constructed from a pre-trained diffusion model to be adversarially robust. RDC first maximizes the data likelihood of a given input and then predicts the class probabilities of the optimized input using the conditional likelihood estimated by the diffusion model through Bayes' theorem. To further reduce the computational cost, we propose a new diffusion backbone called multi-head diffusion and develop efficient sampling strategies. As RDC does not require training on particular adversarial attacks, we demonstrate that it is more generalizable to defend against multiple unseen threats. In particular, RDC achieves $75.67%$ robust accuracy against various $ell_infty$ norm-bounded adaptive attacks with $epsilon_infty=8/255$ on CIFAR-10, surpassing the previous state-of-the-art adversarial training models by $+4.77%$. The results highlight the potential of generative classifiers by employing pre-trained diffusion models for adversarial robustness compared with the commonly studied discriminative classifiers. Code is available at url{https://github.com/huanranchen/DiffusionClassifier}.
5/22/2024