Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
2310.16834
0
0
📊
Abstract
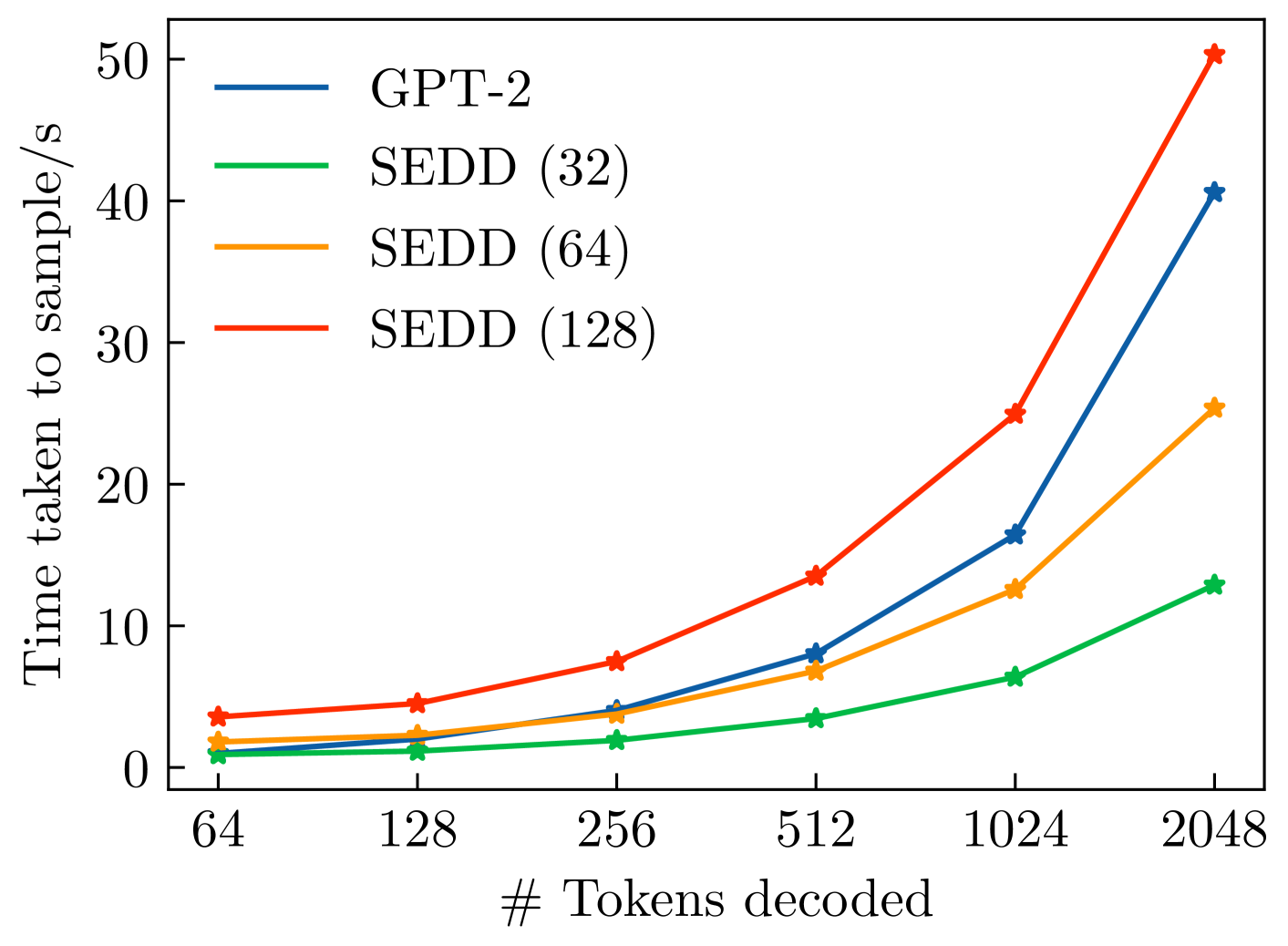
Despite their groundbreaking performance for many generative modeling tasks, diffusion models have fallen short on discrete data domains such as natural language. Crucially, standard diffusion models rely on the well-established theory of score matching, but efforts to generalize this to discrete structures have not yielded the same empirical gains. In this work, we bridge this gap by proposing score entropy, a novel loss that naturally extends score matching to discrete spaces, integrates seamlessly to build discrete diffusion models, and significantly boosts performance. Experimentally, we test our Score Entropy Discrete Diffusion models (SEDD) on standard language modeling tasks. For comparable model sizes, SEDD beats existing language diffusion paradigms (reducing perplexity by $25$-$75$%) and is competitive with autoregressive models, in particular outperforming GPT-2. Furthermore, compared to autoregressive mdoels, SEDD generates faithful text without requiring distribution annealing techniques like temperature scaling (around $6$-$8times$ better generative perplexity than un-annealed GPT-2), can trade compute and quality (similar quality with $32times$ fewer network evaluations), and enables controllable infilling (matching nucleus sampling quality while enabling other strategies besides left to right prompting).
Create account to get full access
Overview
- Diffusion models have shown impressive performance on many generative tasks, but have struggled with discrete data like natural language.
- Standard diffusion models rely on score matching, but efforts to extend this to discrete domains have not been as successful.
- This paper proposes a novel loss called "score entropy" that enables diffusion models to effectively learn on discrete data, significantly boosting their performance.
Plain English Explanation
Diffusion models are a type of machine learning algorithm that have become very good at generating new data, like images or audio, that looks realistic. However, when it comes to generating text or other discrete data (data that comes in specific units, like words), diffusion models have not been as successful.
The key reason for this is that diffusion models rely on a technique called "score matching" to learn how to generate new data. Score matching works well for continuous data like images, but it's not as straightforward to apply to discrete data. Researchers have tried to extend score matching to discrete domains, but the results haven't been as impressive as for continuous data.
This new paper proposes a solution to this problem. The researchers developed a new loss function called "score entropy" that allows diffusion models to effectively learn on discrete data, like text. By using this new loss function, the diffusion models are able to generate text that is much better - it has lower "perplexity" (a measure of how surprised the model is by the text), and it can generate coherent text without needing special techniques like "temperature scaling" that other text generation models require.
Importantly, the new diffusion models with score entropy can match the performance of state-of-the-art autoregressive language models, like GPT-2, while being more efficient in terms of the number of computations required. They also enable new capabilities, like being able to "infill" text (generate text to fill in the middle of a passage) rather than just generating text sequentially from left to right.
Technical Explanation
The key innovation in this paper is the introduction of "score entropy", a novel loss function that extends the well-established score matching principle to discrete data domains like natural language. Score matching is a powerful technique for training generative models, but its direct application to discrete structures has not led to the same empirical gains.
The authors show that by optimizing for score entropy instead of standard score matching objectives, diffusion models can be effectively trained on discrete data. This approach seamlessly integrates into the diffusion framework and leads to significant performance boosts on standard language modeling benchmarks.
Experimentally, the authors evaluate their "Score Entropy Discrete Diffusion" (SEDD) models on text generation tasks. They find that SEDD models outperform existing discrete diffusion approaches by 25-75% in terms of perplexity, and are competitive with autoregressive models like GPT-2. Importantly, SEDD models are able to generate faithful text without requiring distribution annealing techniques like temperature scaling, which are commonly used for autoregressive models. Additionally, SEDD models enable more control and flexibility in the text generation process, like enabling infilling rather than just left-to-right prompting.
Critical Analysis
The work presented in this paper represents an important advance in applying diffusion models to discrete data domains, specifically natural language. By developing the novel "score entropy" loss function, the authors have found a way to effectively train diffusion models on text data, overcoming the limitations of previous approaches that relied on score matching.
One potential area for further research is exploring how the score entropy objective could be adapted to learn low-dimensional structures in the discrete data, which may lead to even stronger performance. Additionally, while the results on language modeling are impressive, it would be valuable to see how the SEDD models perform on other discrete data tasks, such as code generation or structured data modeling.
Overall, this work makes a significant contribution to the field of generative modeling, demonstrating that diffusion models can be a viable alternative to autoregressive approaches even for discrete data domains. The improved efficiency and control afforded by the SEDD models suggest they could be a useful tool for a variety of text generation applications.
Conclusion
This paper presents a novel approach to training diffusion models on discrete data, specifically for natural language tasks. By introducing the "score entropy" loss function, the authors have found a way to effectively extend the powerful score matching principle to discrete domains, overcoming a key limitation of previous diffusion models.
The experimental results show that the new "Score Entropy Discrete Diffusion" (SEDD) models significantly outperform existing discrete diffusion models and are competitive with state-of-the-art autoregressive language models, while offering additional benefits like improved efficiency and more flexible generation capabilities. This work represents an important advancement in the field of generative modeling and could have far-reaching implications for a variety of text-based applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Promises, Outlooks and Challenges of Diffusion Language Modeling
Justin Deschenaux, Caglar Gulcehre
0
0
The modern autoregressive Large Language Models (LLMs) have achieved outstanding performance on NLP benchmarks, and they are deployed in the real world. However, they still suffer from limitations of the autoregressive training paradigm. For example, autoregressive token generation is notably slow and can be prone to textit{exposure bias}. The diffusion-based language models were proposed as an alternative to autoregressive generation to address some of these limitations. We evaluate the recently proposed Score Entropy Discrete Diffusion (SEDD) approach and show it is a promising alternative to autoregressive generation but it has some short-comings too. We empirically demonstrate the advantages and challenges of SEDD, and observe that SEDD generally matches autoregressive models in perplexity and on benchmarks such as HellaSwag, Arc or WinoGrande. Additionally, we show that in terms of inference latency, SEDD can be up to 4.5$times$ more efficient than GPT-2. While SEDD allows conditioning on tokens at abitrary positions, SEDD appears slightly weaker than GPT-2 for conditional generation given short prompts. Finally, we reproduced the main results from the original SEDD paper.
6/18/2024
Simplified and Generalized Masked Diffusion for Discrete Data
Jiaxin Shi, Kehang Han, Zhe Wang, Arnaud Doucet, Michalis K. Titsias
0
0
Masked (or absorbing) diffusion is actively explored as an alternative to autoregressive models for generative modeling of discrete data. However, existing work in this area has been hindered by unnecessarily complex model formulations and unclear relationships between different perspectives, leading to suboptimal parameterization, training objectives, and ad hoc adjustments to counteract these issues. In this work, we aim to provide a simple and general framework that unlocks the full potential of masked diffusion models. We show that the continuous-time variational objective of masked diffusion models is a simple weighted integral of cross-entropy losses. Our framework also enables training generalized masked diffusion models with state-dependent masking schedules. When evaluated by perplexity, our models trained on OpenWebText surpass prior diffusion language models at GPT-2 scale and demonstrate superior performance on 4 out of 5 zero-shot language modeling tasks. Furthermore, our models vastly outperform previous discrete diffusion models on pixel-level image modeling, achieving 2.78~(CIFAR-10) and 3.42 (ImageNet 64$times$64) bits per dimension that are comparable or better than autoregressive models of similar sizes.
6/7/2024

Improving Discrete Diffusion Models via Structured Preferential Generation
Severi Rissanen, Markus Heinonen, Arno Solin
0
0
In the domains of image and audio, diffusion models have shown impressive performance. However, their application to discrete data types, such as language, has often been suboptimal compared to autoregressive generative models. This paper tackles the challenge of improving discrete diffusion models by introducing a structured forward process that leverages the inherent information hierarchy in discrete categories, such as words in text. Our approach biases the generative process to produce certain categories before others, resulting in a notable improvement in log-likelihood scores on the text8 dataset. This work paves the way for more advances in discrete diffusion models with potentially significant enhancements in performance.
5/29/2024
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
Jingyang Ou, Shen Nie, Kaiwen Xue, Fengqi Zhu, Jiacheng Sun, Zhenguo Li, Chongxuan Li
0
0
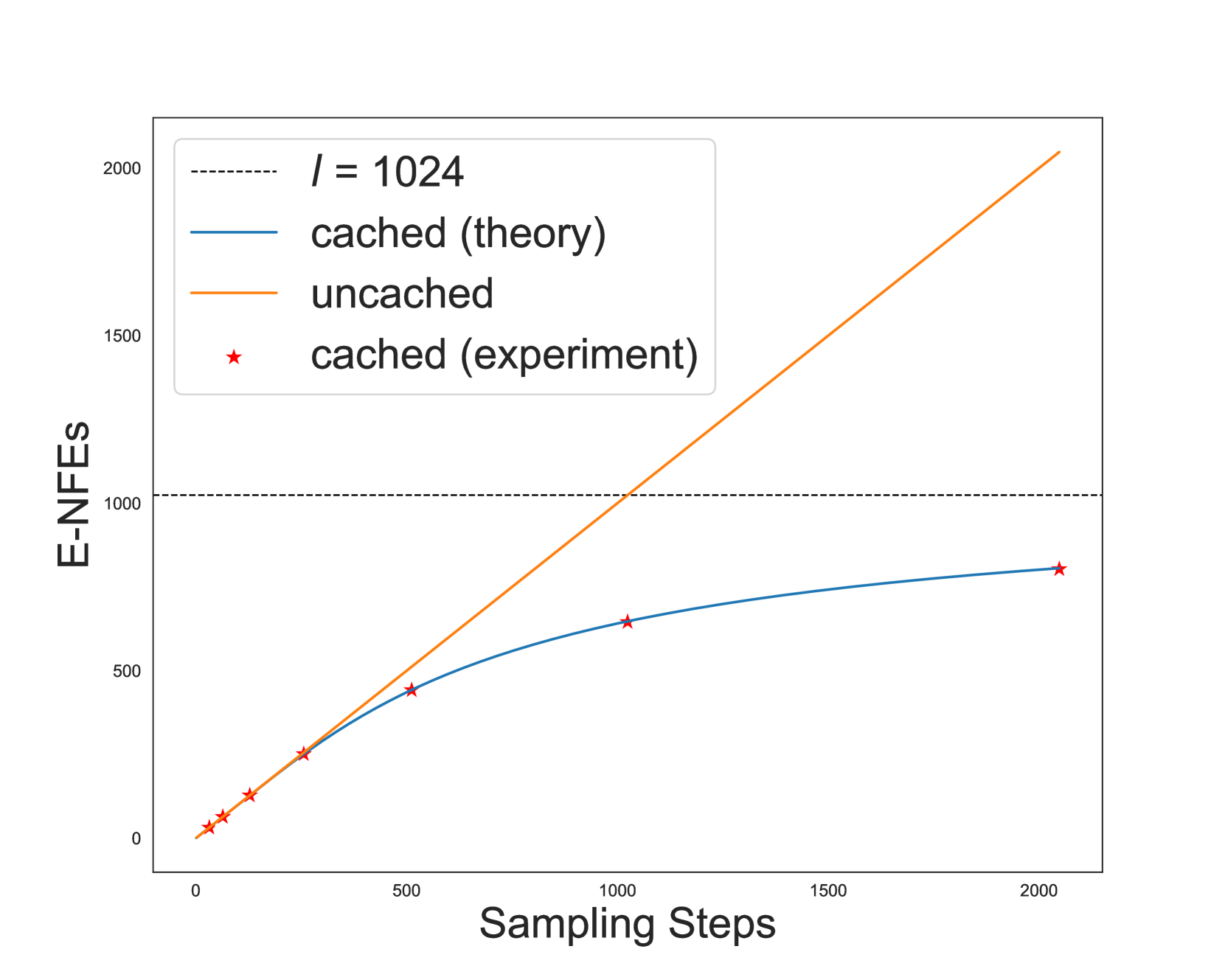
Discrete diffusion models with absorbing processes have shown promise in language modeling. The key quantities to be estimated are the ratios between the marginal probabilities of two transitive states at all timesteps, called the concrete score. In this paper, we reveal that the concrete score in absorbing diffusion can be expressed as conditional probabilities of clean data, multiplied by a time-dependent scalar in an analytic form. Motivated by the finding, we propose reparameterized absorbing discrete diffusion (RADD), a dedicated diffusion model that characterizes the time-independent conditional probabilities. Besides its simplicity, RADD can reduce the number of function evaluations (NFEs) by caching the output of the time-independent network when the noisy sample remains unchanged in a sampling interval. Empirically, RADD is up to 3.5 times faster while consistently achieving a better performance than the strongest baseline. Built upon the new factorization of the concrete score, we further prove a surprising result that the exact likelihood of absorbing diffusion can be rewritten to a simple form (named denoising cross-entropy) and then estimated efficiently by the Monte Carlo method. The resulting approach also applies to the original parameterization of the concrete score. It significantly advances the state-of-the-art discrete diffusion on 5 zero-shot language modeling benchmarks (measured by perplexity) at the GPT-2 scale.
6/7/2024