Zero Shot Context-Based Object Segmentation using SLIP (SAM+CLIP)

0
➖
Sign in to get full access
Overview
- SLIP (SAM+CLIP) is a new architecture that combines the Segment Anything Model (SAM) and Contrastive Language-Image Pretraining (CLIP) to enable zero-shot object segmentation.
- By incorporating text prompts into SAM using CLIP, SLIP allows for object segmentation without prior training on specific classes or categories.
- SLIP demonstrates the ability to recognize and segment objects in images based on contextual information from text prompts, expanding the capabilities of SAM for versatile object segmentation.
Plain English Explanation
SLIP is a new AI system that can identify and outline objects in images based on text descriptions, without needing to be trained on those specific objects beforehand. It does this by combining two powerful AI models: SAM, which can segment objects in images, and CLIP, which can understand the meaning of text and how it relates to images.
By linking SAM and CLIP together, SLIP can take a text description like "a red apple on a table" and use that information to identify and outline the apple in an image, even if it hasn't seen that exact apple before. This makes object segmentation much more flexible and practical, as you don't need to train the system on every possible object ahead of time.
The researchers trained CLIP on a dataset of Pokémon characters, teaching it to associate images with their names and descriptions. Then they integrated this text-image understanding capability into SAM, allowing the combined SLIP system to segment objects based on textual cues. This shows how blending different AI technologies can expand the possibilities for computer vision tasks like object detection.
Technical Explanation
SLIP combines the Segment Anything Model (SAM) with the Contrastive Language-Image Pretraining (CLIP) model to enable zero-shot object segmentation. By incorporating CLIP's text-image understanding capabilities into SAM, SLIP can segment objects in images based on textual cues, without requiring prior training on those specific object classes.
The researchers fine-tuned the CLIP model on a Pokémon dataset, teaching it to associate Pokémon images with their names and descriptions. This allowed CLIP to learn meaningful image-text representations that SLIP could then leverage for object segmentation. The integrated SLIP architecture demonstrates the ability to recognize and segment objects in images based on contextual information from text prompts, expanding the versatility of SAM.
Critical Analysis
The paper highlights the potential of combining complementary AI models like SAM and CLIP to tackle complex computer vision tasks in more flexible and context-aware ways. By integrating CLIP's text-image understanding, SLIP overcomes limitations of SAM, which requires prior training on specific object classes.
However, the paper does not address potential biases or limitations that could arise from the CLIP model's training on the Pokémon dataset. Additionally, the performance and generalization of SLIP beyond the Pokémon domain is not extensively evaluated. Further research is needed to assess the broader applicability and robustness of the SLIP approach, as well as its scalability to larger and more diverse object categories.
Exploring techniques like compositional image-text matching could further enhance SLIP's ability to understand and segment objects based on complex textual descriptions. Investigating the semantic robustness of SLIP's text-guided segmentation in the face of linguistic variation or adversarial prompts would also be valuable.
Conclusion
SLIP represents an innovative approach to zero-shot object segmentation by leveraging the complementary strengths of SAM and CLIP. By combining a powerful object segmentation model with a text-image understanding system, SLIP demonstrates the potential to expand the capabilities of computer vision beyond traditional object recognition. This research highlights the benefits of integrating diverse AI technologies to tackle complex real-world challenges in a more flexible and contextual manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
0
Zero Shot Context-Based Object Segmentation using SLIP (SAM+CLIP)
Saaketh Koundinya Gundavarapu, Arushi Arora, Shreya Agarwal
We present SLIP (SAM+CLIP), an enhanced architecture for zero-shot object segmentation. SLIP combines the Segment Anything Model (SAM) cite{kirillov2023segment} with the Contrastive Language-Image Pretraining (CLIP) cite{radford2021learning}. By incorporating text prompts into SAM using CLIP, SLIP enables object segmentation without prior training on specific classes or categories. We fine-tune CLIP on a Pokemon dataset, allowing it to learn meaningful image-text representations. SLIP demonstrates the ability to recognize and segment objects in images based on contextual information from text prompts, expanding the capabilities of SAM for versatile object segmentation. Our experiments demonstrate the effectiveness of the SLIP architecture in segmenting objects in images based on textual cues. The integration of CLIP's text-image understanding capabilities into SAM expands the capabilities of the original architecture and enables more versatile and context-aware object segmentation.
Read more5/27/2024

0
Test-Time Adaptation with SaLIP: A Cascade of SAM and CLIP for Zero shot Medical Image Segmentation
Sidra Aleem, Fangyijie Wang, Mayug Maniparambil, Eric Arazo, Julia Dietlmeier, Guenole Silvestre, Kathleen Curran, Noel E. O'Connor, Suzanne Little
The Segment Anything Model (SAM) and CLIP are remarkable vision foundation models (VFMs). SAM, a prompt driven segmentation model, excels in segmentation tasks across diverse domains, while CLIP is renowned for its zero shot recognition capabilities. However, their unified potential has not yet been explored in medical image segmentation. To adapt SAM to medical imaging, existing methods primarily rely on tuning strategies that require extensive data or prior prompts tailored to the specific task, making it particularly challenging when only a limited number of data samples are available. This work presents an in depth exploration of integrating SAM and CLIP into a unified framework for medical image segmentation. Specifically, we propose a simple unified framework, SaLIP, for organ segmentation. Initially, SAM is used for part based segmentation within the image, followed by CLIP to retrieve the mask corresponding to the region of interest (ROI) from the pool of SAM generated masks. Finally, SAM is prompted by the retrieved ROI to segment a specific organ. Thus, SaLIP is training and fine tuning free and does not rely on domain expertise or labeled data for prompt engineering. Our method shows substantial enhancements in zero shot segmentation, showcasing notable improvements in DICE scores across diverse segmentation tasks like brain (63.46%), lung (50.11%), and fetal head (30.82%), when compared to un prompted SAM. Code and text prompts are available at: https://github.com/aleemsidra/SaLIP.
Read more5/1/2024
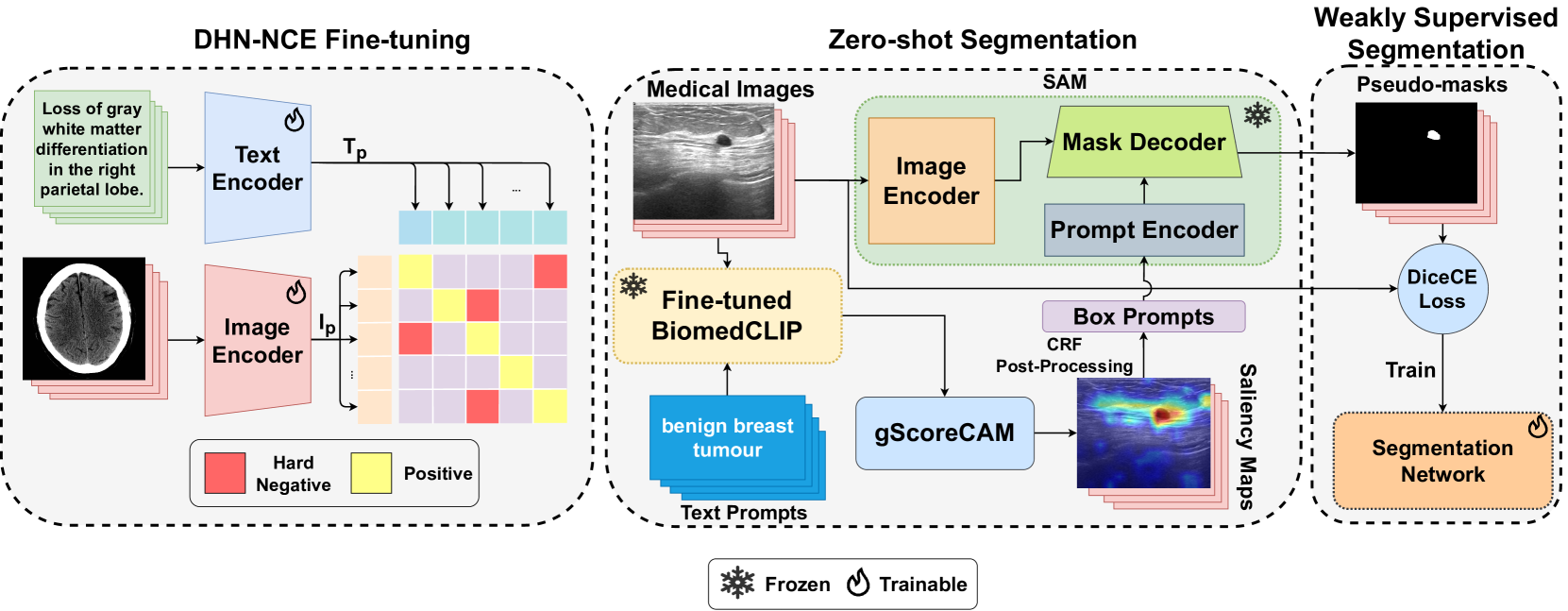
0
MedCLIP-SAM: Bridging Text and Image Towards Universal Medical Image Segmentation
Taha Koleilat, Hojat Asgariandehkordi, Hassan Rivaz, Yiming Xiao
Medical image segmentation of anatomical structures and pathology is crucial in modern clinical diagnosis, disease study, and treatment planning. To date, great progress has been made in deep learning-based segmentation techniques, but most methods still lack data efficiency, generalizability, and interactability. Consequently, the development of new, precise segmentation methods that demand fewer labeled datasets is of utmost importance in medical image analysis. Recently, the emergence of foundation models, such as CLIP and Segment-Anything-Model (SAM), with comprehensive cross-domain representation opened the door for interactive and universal image segmentation. However, exploration of these models for data-efficient medical image segmentation is still limited, but is highly necessary. In this paper, we propose a novel framework, called MedCLIP-SAM that combines CLIP and SAM models to generate segmentation of clinical scans using text prompts in both zero-shot and weakly supervised settings. To achieve this, we employed a new Decoupled Hard Negative Noise Contrastive Estimation (DHN-NCE) loss to fine-tune the BiomedCLIP model and the recent gScoreCAM to generate prompts to obtain segmentation masks from SAM in a zero-shot setting. Additionally, we explored the use of zero-shot segmentation labels in a weakly supervised paradigm to improve the segmentation quality further. By extensively testing three diverse segmentation tasks and medical image modalities (breast tumor ultrasound, brain tumor MRI, and lung X-ray), our proposed framework has demonstrated excellent accuracy. Code is available at https://github.com/HealthX-Lab/MedCLIP-SAM.
Read more6/21/2024

0
Open-Vocabulary SAM: Segment and Recognize Twenty-thousand Classes Interactively
Haobo Yuan, Xiangtai Li, Chong Zhou, Yining Li, Kai Chen, Chen Change Loy
The CLIP and Segment Anything Model (SAM) are remarkable vision foundation models (VFMs). SAM excels in segmentation tasks across diverse domains, whereas CLIP is renowned for its zero-shot recognition capabilities. This paper presents an in-depth exploration of integrating these two models into a unified framework. Specifically, we introduce the Open-Vocabulary SAM, a SAM-inspired model designed for simultaneous interactive segmentation and recognition, leveraging two unique knowledge transfer modules: SAM2CLIP and CLIP2SAM. The former adapts SAM's knowledge into the CLIP via distillation and learnable transformer adapters, while the latter transfers CLIP knowledge into SAM, enhancing its recognition capabilities. Extensive experiments on various datasets and detectors show the effectiveness of Open-Vocabulary SAM in both segmentation and recognition tasks, significantly outperforming the na{i}ve baselines of simply combining SAM and CLIP. Furthermore, aided with image classification data training, our method can segment and recognize approximately 22,000 classes.
Read more9/17/2024