Krthr
Models by this creator
clip-embeddings

155
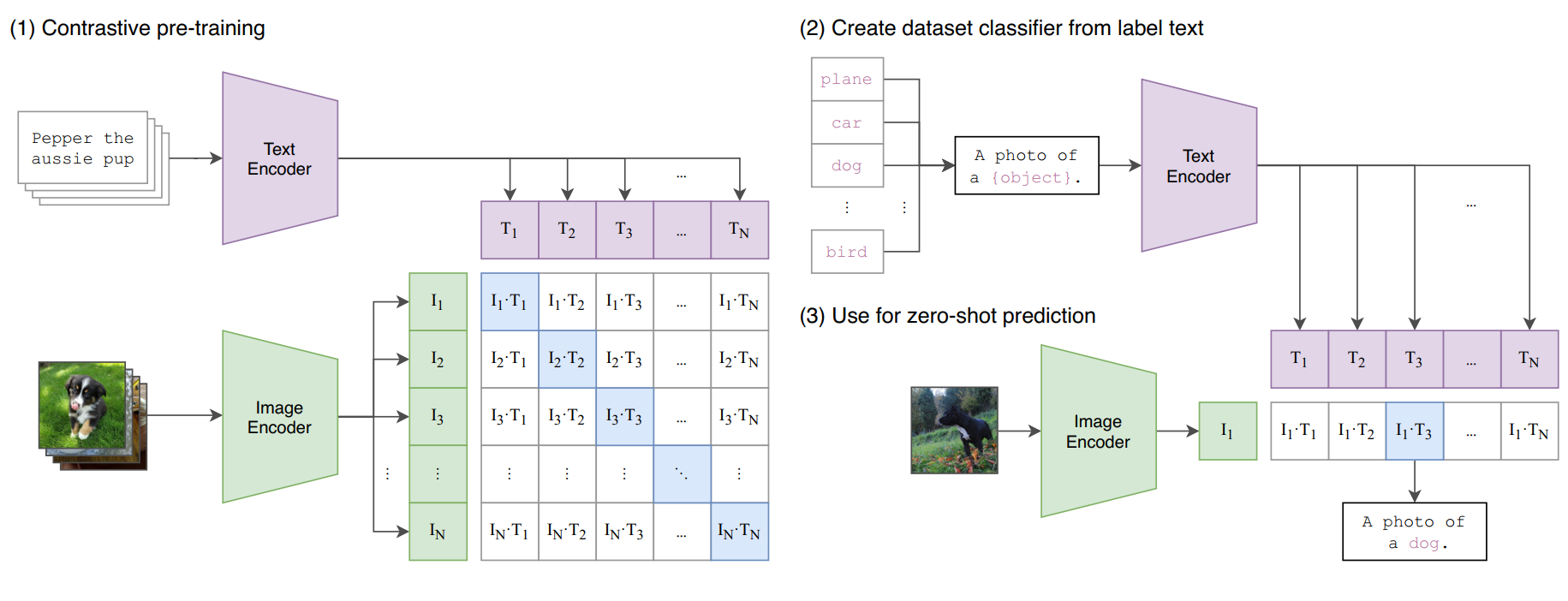
The clip-embeddings model, developed by krthr, generates CLIP text and image embeddings using the clip-vit-large-patch14 model. CLIP (Contrastive Language-Image Pre-Training) is a computer vision model developed by researchers at OpenAI to learn about robustness and generalization in zero-shot image classification tasks. The clip-embeddings model allows users to generate CLIP embeddings for both text and image inputs, which can be useful for tasks like image-text similarity matching, retrieval, and multimodal analysis. This model is similar to other CLIP-based models like clip-vit-large-patch14, clip-vit-base-patch16, clip-vit-base-patch32, and clip-interrogator, all of which use different CLIP model variants and configurations. Model inputs and outputs The clip-embeddings model takes two inputs: text and image. The text input is a string of text, while the image input is a URI pointing to an image. The model outputs a single object with an "embedding" field, which is an array of numbers representing the CLIP embedding for the input text and image. Inputs text**: Input text as a string image**: Input image as a URI Outputs embedding**: An array of numbers representing the CLIP embedding for the input text and image Capabilities The clip-embeddings model can be used to generate CLIP embeddings for text and image inputs, which can be useful for a variety of computer vision and multimodal tasks. For example, the embeddings can be used to measure the similarity between text and images, perform image retrieval based on text queries, or build multimodal machine learning models. What can I use it for? The clip-embeddings model can be used for a variety of research and experimentation purposes, such as: Image-text similarity**: Using the model's embeddings to measure the similarity between text and images, which can be useful for tasks like image retrieval, captioning, and visual question answering. Multimodal analysis**: Combining the text and image embeddings to build multimodal machine learning models for tasks like sentiment analysis, content moderation, or product recommendation. Zero-shot learning**: Leveraging the model's ability to generalize to new tasks and classes, as demonstrated in the original CLIP research, to explore novel computer vision applications. Things to try One interesting thing to try with the clip-embeddings model is to explore how the model's performance and outputs vary across different types of text and image inputs. For example, you could try using the model to generate embeddings for a variety of text prompts and images, and then analyze the similarities and differences between the embeddings. This could provide insights into the model's strengths, limitations, and potential biases. Another thing to try is to use the model's embeddings as features in downstream machine learning tasks, such as image classification or retrieval. By combining the CLIP embeddings with other data sources or models, you may be able to create more powerful and versatile AI systems.
Updated 9/16/2024