clip-embeddings
Maintainer: krthr

155
| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
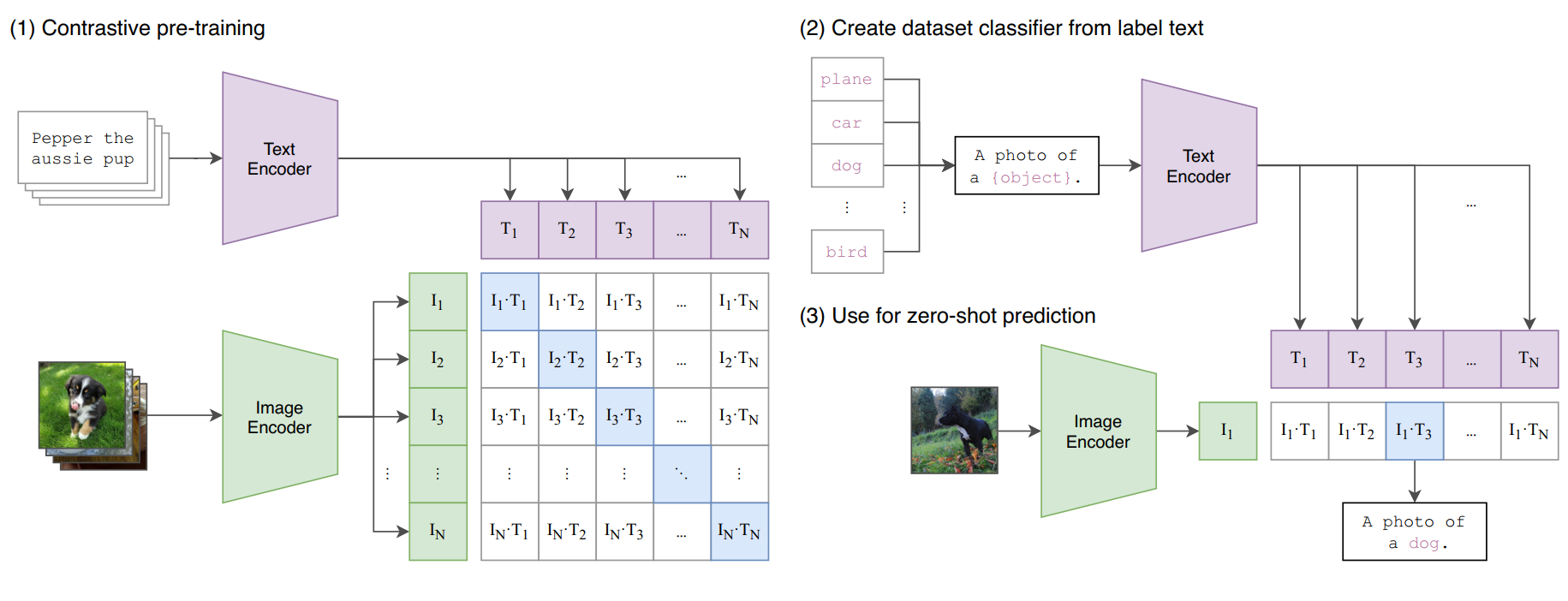
The clip-embeddings model, developed by krthr, generates CLIP text and image embeddings using the clip-vit-large-patch14 model. CLIP (Contrastive Language-Image Pre-Training) is a computer vision model developed by researchers at OpenAI to learn about robustness and generalization in zero-shot image classification tasks. The clip-embeddings model allows users to generate CLIP embeddings for both text and image inputs, which can be useful for tasks like image-text similarity matching, retrieval, and multimodal analysis.
This model is similar to other CLIP-based models like clip-vit-large-patch14, clip-vit-base-patch16, clip-vit-base-patch32, and clip-interrogator, all of which use different CLIP model variants and configurations.
Model inputs and outputs
The clip-embeddings model takes two inputs: text and image. The text input is a string of text, while the image input is a URI pointing to an image. The model outputs a single object with an "embedding" field, which is an array of numbers representing the CLIP embedding for the input text and image.
Inputs
- text: Input text as a string
- image: Input image as a URI
Outputs
- embedding: An array of numbers representing the CLIP embedding for the input text and image
Capabilities
The clip-embeddings model can be used to generate CLIP embeddings for text and image inputs, which can be useful for a variety of computer vision and multimodal tasks. For example, the embeddings can be used to measure the similarity between text and images, perform image retrieval based on text queries, or build multimodal machine learning models.
What can I use it for?
The clip-embeddings model can be used for a variety of research and experimentation purposes, such as:
- Image-text similarity: Using the model's embeddings to measure the similarity between text and images, which can be useful for tasks like image retrieval, captioning, and visual question answering.
- Multimodal analysis: Combining the text and image embeddings to build multimodal machine learning models for tasks like sentiment analysis, content moderation, or product recommendation.
- Zero-shot learning: Leveraging the model's ability to generalize to new tasks and classes, as demonstrated in the original CLIP research, to explore novel computer vision applications.
Things to try
One interesting thing to try with the clip-embeddings model is to explore how the model's performance and outputs vary across different types of text and image inputs. For example, you could try using the model to generate embeddings for a variety of text prompts and images, and then analyze the similarities and differences between the embeddings. This could provide insights into the model's strengths, limitations, and potential biases.
Another thing to try is to use the model's embeddings as features in downstream machine learning tasks, such as image classification or retrieval. By combining the CLIP embeddings with other data sources or models, you may be able to create more powerful and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

clip-features
61.0K
The clip-features model, developed by Replicate creator andreasjansson, is a Cog model that outputs CLIP features for text and images. This model builds on the powerful CLIP architecture, which was developed by researchers at OpenAI to learn about robustness in computer vision tasks and test the ability of models to generalize to arbitrary image classification in a zero-shot manner. Similar models like blip-2 and clip-embeddings also leverage CLIP capabilities for tasks like answering questions about images and generating text and image embeddings. Model inputs and outputs The clip-features model takes a set of newline-separated inputs, which can either be strings of text or image URIs starting with http[s]://. The model then outputs an array of named embeddings, where each embedding corresponds to one of the input entries. Inputs Inputs**: Newline-separated inputs, which can be strings of text or image URIs starting with http[s]://. Outputs Output**: An array of named embeddings, where each embedding corresponds to one of the input entries. Capabilities The clip-features model can be used to generate CLIP features for text and images, which can be useful for a variety of downstream tasks like image classification, retrieval, and visual question answering. By leveraging the powerful CLIP architecture, this model can enable researchers and developers to explore zero-shot and few-shot learning approaches for their computer vision applications. What can I use it for? The clip-features model can be used in a variety of applications that involve understanding the relationship between images and text. For example, you could use it to: Perform image-text similarity search, where you can find the most relevant images for a given text query, or vice versa. Implement zero-shot image classification, where you can classify images into categories without any labeled training data. Develop multimodal applications that combine vision and language, such as visual question answering or image captioning. Things to try One interesting aspect of the clip-features model is its ability to generate embeddings that capture the semantic relationship between text and images. You could try using these embeddings to explore the similarities and differences between various text and image pairs, or to build applications that leverage this cross-modal understanding. For example, you could calculate the cosine similarity between the embeddings of different text inputs and the embedding of a given image, as demonstrated in the provided example code. This could be useful for tasks like image-text retrieval or for understanding the model's perception of the relationship between visual and textual concepts.
Updated Invalid Date

clip-vit-large-patch14
5.7K
The clip-vit-large-patch14 model is a powerful computer vision AI developed by OpenAI using the CLIP architecture. CLIP is a groundbreaking model that can perform zero-shot image classification, meaning it can recognize and classify images without being explicitly trained on those exact classes. This model builds on the successes of CLIP by using a large Vision Transformer (ViT) image encoder with a patch size of 14x14. Similar models like the CLIP features model and the clip-vit-large-patch14 model from OpenAI allow you to leverage the powerful capabilities of CLIP for your own computer vision projects. The clip-vit-base-patch32 model from OpenAI uses a smaller Vision Transformer architecture, providing a trade-off between performance and efficiency. Model inputs and outputs The clip-vit-large-patch14 model takes two main inputs: text descriptions and images. The text input allows you to provide a description of the image you want the model to analyze, while the image input is the actual image you want the model to process. Inputs text**: A string containing a description of the image, with different descriptions separated by "|". image**: A URI pointing to the input image. Outputs Output**: An array of numbers representing the model's output. Capabilities The clip-vit-large-patch14 model is capable of powerful zero-shot image classification, meaning it can recognize and classify images without being explicitly trained on those exact classes. This allows the model to generalize to a wide range of image recognition tasks, from identifying objects and scenes to recognizing text and logos. What can I use it for? The clip-vit-large-patch14 model is a versatile tool that can be used for a variety of computer vision and image recognition tasks. Some potential use cases include: Image search and retrieval**: Use the model to find similar images based on text descriptions, or to retrieve relevant images from a large database. Visual question answering**: Ask the model questions about the contents of an image and get relevant responses. Image classification and recognition**: Leverage the model's zero-shot capabilities to classify images into a wide range of categories, even ones the model wasn't explicitly trained on. Things to try One interesting thing to try with the clip-vit-large-patch14 model is to experiment with different text descriptions to see how the model's output changes. You can try describing the same image in multiple ways and see how the model's perceptions and classifications shift. This can provide insights into the model's underlying understanding of visual concepts and how it relates them to language. Another interesting experiment is to try the model on a wide range of image types, from simple line drawings to complex real-world scenes. This can help you understand the model's strengths and limitations, and identify areas where it performs particularly well or struggles.
Updated Invalid Date

stylegan3-clip
6
The stylegan3-clip model is a combination of the StyleGAN3 generative adversarial network and the CLIP multimodal model. It allows for text-based guided image generation, where a textual prompt can be used to guide the generation process and create images that match the specified description. This model builds upon the work of StyleGAN3 and CLIP, aiming to provide an easy-to-use interface for experimenting with these powerful AI technologies. The stylegan3-clip model is similar to other text-to-image generation models like styleclip, stable-diffusion, and gfpgan, which leverage pre-trained models and techniques to create visuals from textual prompts. However, the unique combination of StyleGAN3 and CLIP in this model offers different capabilities and potential use cases. Model inputs and outputs The stylegan3-clip model takes in several inputs to guide the image generation process: Inputs Texts**: The textual prompt(s) that will be used to guide the image generation. Multiple prompts can be entered, separated by |, which will cause the guidance to focus on the different prompts simultaneously. Model_name**: The pre-trained model to use, which can be FFHQ (human faces), MetFaces (human faces from works of art), or AFHGv2 (animal faces). Steps**: The number of sampling steps to perform, with a recommended value of 100 or less to avoid timeouts. Seed**: An optional seed value to use for reproducibility, or -1 for a random seed. Output_type**: The desired output format, either a single image or a video. Video_length**: The length of the video output, if that option is selected. Learning_rate**: The learning rate to use during the image generation process. Outputs The model outputs either a single generated image or a video sequence of the generation process, depending on the selected output_type. Capabilities The stylegan3-clip model allows for flexible and expressive text-guided image generation. By combining the power of StyleGAN3's high-fidelity image synthesis with CLIP's ability to understand and match textual prompts, the model can create visuals that closely align with the user's descriptions. This can be particularly useful for creative applications, such as generating concept art, product designs, or visualizations based on textual ideas. What can I use it for? The stylegan3-clip model can be a valuable tool for various creative and artistic endeavors. Some potential use cases include: Concept art and visualization**: Generate visuals to illustrate ideas, stories, or product concepts based on textual descriptions. Generative art and design**: Experiment with text-guided image generation to create unique, expressive artworks. Educational and research applications**: Use the model to explore the intersection of language and visual representation, or to study the capabilities of multimodal AI systems. Prototyping and mockups**: Quickly generate images to test ideas or explore design possibilities before investing in more time-consuming production. Things to try With the stylegan3-clip model, users can experiment with a wide range of textual prompts to see how the generated images respond. Try mixing and matching different prompts, or explore prompts that combine multiple concepts or styles. Additionally, adjusting the model parameters, such as the learning rate or number of sampling steps, can lead to interesting variations in the output.
Updated Invalid Date

diffusionclip
5
DiffusionCLIP is a novel method that performs text-driven image manipulation using diffusion models. It was proposed by Gwanghyun Kim, Taesung Kwon, and Jong Chul Ye in their CVPR 2022 paper. Unlike prior GAN-based approaches, DiffusionCLIP leverages the full inversion capability and high-quality image generation power of recent diffusion models to enable zero-shot image manipulation, even between unseen domains. This allows for robust and faithful manipulation of real images, going beyond the limited capabilities of GAN inversion methods. DiffusionCLIP is similar in spirit to other text-guided image manipulation models like StyleCLIP and StyleGAN-NADA, but with key technical differences enabled by its diffusion-based approach. Model inputs and outputs Inputs Image**: An input image to be manipulated. Edit type**: The desired attribute or style to apply to the input image (e.g. "ImageNet style transfer - Watercolor art"). Manipulation**: The type of manipulation to perform (e.g. "ImageNet style transfer"). Degree of change**: The intensity or amount of the desired edit, from 0 (no change) to 1 (maximum change). N test step**: The number of steps to use in the image generation process, between 5 and 100. Outputs Output image**: The manipulated image, with the desired attribute or style applied. Capabilities DiffusionCLIP enables high-quality, zero-shot image manipulation even on real-world images from diverse datasets like ImageNet. It can accurately edit images while preserving the original identity and content, unlike prior GAN-based approaches. The model also supports multi-attribute manipulation by blending noise from multiple fine-tuned models. Additionally, DiffusionCLIP can translate images between unseen domains, generating new images from scratch based on text prompts. What can I use it for? DiffusionCLIP can be a powerful tool for a variety of image editing and generation tasks. Its ability to manipulate real-world images in diverse domains makes it suitable for applications like photo editing, digital art creation, and even product visualization. Businesses could leverage DiffusionCLIP to quickly generate product mockups or visualizations based on textual descriptions. Creators could use it to explore creative possibilities by manipulating images in unexpected ways guided by text prompts. Things to try One interesting aspect of DiffusionCLIP is its ability to translate images between unseen domains, such as generating a "watercolor art" version of an input image. Try experimenting with different text prompts to see how the model can transform images in surprising ways, going beyond simple attribute edits. You could also explore the model's multi-attribute manipulation capabilities, blending different text-guided changes to create unique hybrid outputs.
Updated Invalid Date