Openai
Models by this creator
whisper

8.6K
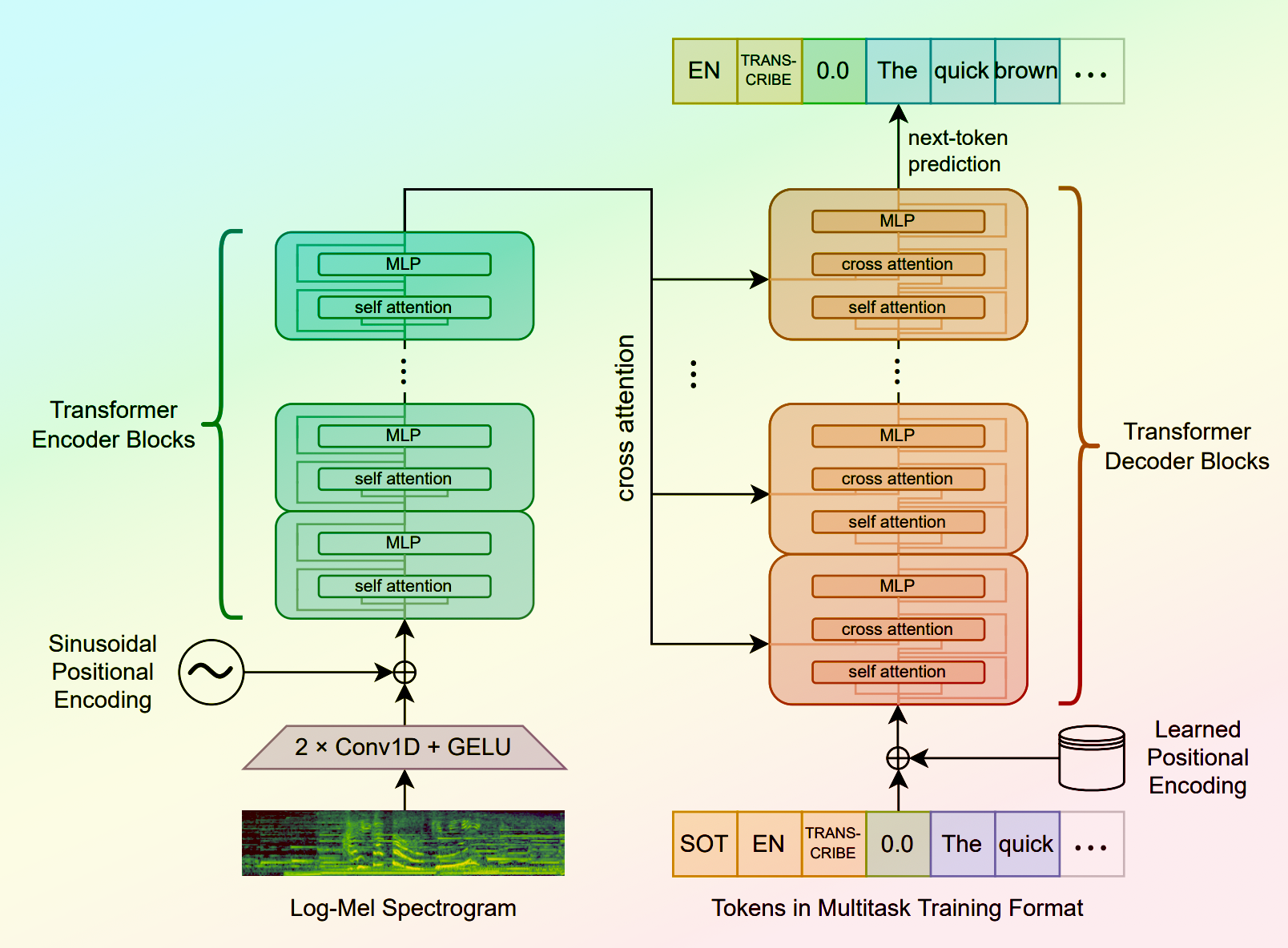
Whisper is a general-purpose speech recognition model developed by OpenAI. It is capable of converting speech in audio to text, with the ability to translate the text to English if desired. Whisper is based on a large Transformer model trained on a diverse dataset of multilingual and multitask speech recognition data. This allows the model to handle a wide range of accents, background noises, and languages. Similar models like whisper-large-v3, incredibly-fast-whisper, and whisper-diarization offer various optimizations and additional features built on top of the core Whisper model. Model inputs and outputs Whisper takes an audio file as input and outputs a text transcription. The model can also translate the transcription to English if desired. The input audio can be in various formats, and the model supports a range of parameters to fine-tune the transcription, such as temperature, patience, and language. Inputs Audio**: The audio file to be transcribed Model**: The specific version of the Whisper model to use, currently only large-v3 is supported Language**: The language spoken in the audio, or None to perform language detection Translate**: A boolean flag to translate the transcription to English Transcription**: The format for the transcription output, such as "plain text" Initial Prompt**: An optional initial text prompt to provide to the model Suppress Tokens**: A list of token IDs to suppress during sampling Logprob Threshold**: The minimum average log probability threshold for a successful transcription No Speech Threshold**: The threshold for considering a segment as silence Condition on Previous Text**: Whether to provide the previous output as a prompt for the next window Compression Ratio Threshold**: The maximum compression ratio threshold for a successful transcription Temperature Increment on Fallback**: The temperature increase when the decoding fails to meet the specified thresholds Outputs Transcription**: The text transcription of the input audio Language**: The detected language of the audio (if language input is None) Tokens**: The token IDs corresponding to the transcription Timestamp**: The start and end timestamps for each word in the transcription Confidence**: The confidence score for each word in the transcription Capabilities Whisper is a powerful speech recognition model that can handle a wide range of accents, background noises, and languages. The model is capable of accurately transcribing audio and optionally translating the transcription to English. This makes Whisper useful for a variety of applications, such as real-time captioning, meeting transcription, and audio-to-text conversion. What can I use it for? Whisper can be used in various applications that require speech-to-text conversion, such as: Captioning and Subtitling**: Automatically generate captions or subtitles for videos, improving accessibility for viewers. Meeting Transcription**: Transcribe audio recordings of meetings, interviews, or conferences for easy review and sharing. Podcast Transcription**: Convert audio podcasts to text, making the content more searchable and accessible. Language Translation**: Transcribe audio in one language and translate the text to another, enabling cross-language communication. Voice Interfaces**: Integrate Whisper into voice-controlled applications, such as virtual assistants or smart home devices. Things to try One interesting aspect of Whisper is its ability to handle a wide range of languages and accents. You can experiment with the model's performance on audio samples in different languages or with various background noises to see how it handles different real-world scenarios. Additionally, you can explore the impact of the different input parameters, such as temperature, patience, and language detection, on the transcription quality and accuracy.
Updated 5/19/2024
🎲
whisper-large-v3
2.5K
The whisper-large-v3 model is a general-purpose speech recognition model developed by OpenAI. It is the latest version of the Whisper model, building on the previous Whisper large models. The whisper-large-v3 model has a few minor architectural differences from the previous large models, including using 128 Mel frequency bins instead of 80 and adding a new language token for Cantonese. The Whisper model was trained on a massive 680,000 hours of audio data, with 65% English data, 18% non-English data with English transcripts, and 17% non-English data with non-English transcripts covering 98 languages. This allows the model to perform well on a diverse range of speech recognition and translation tasks, without needing to fine-tune on specific datasets. Similar Whisper models include the Whisper medium, Whisper tiny, and the whisper-large-v3 model developed by Nate Raw. There is also an incredibly fast version of the Whisper large model by Vaibhav Srivastav. Model inputs and outputs The whisper-large-v3 model takes audio samples as input and generates text transcripts as output. The audio can be in any of the 98 languages covered by the training data. The model can also be used for speech translation, where it generates text in a different language than the audio. Inputs Audio samples in any of the 98 languages the model was trained on Outputs Text transcripts of the audio in the same language Translated text transcripts in a different language Capabilities The whisper-large-v3 model demonstrates strong performance on a variety of speech recognition and translation tasks, with 10-20% lower error rates compared to the previous Whisper large model. It is robust to accents, background noise, and technical language, and can perform zero-shot translation from multiple languages into English. However, the model's performance is uneven across languages, with lower accuracy on low-resource and low-discoverability languages where less training data was available. It also has a tendency to generate repetitive or hallucinated text that is not actually present in the audio input. What can I use it for? The primary intended use of the Whisper models is for AI researchers studying model capabilities, robustness, and limitations. However, the models can also be quite useful as a speech recognition solution for developers, especially for English transcription tasks. The Whisper models could be used to build applications that improve accessibility, such as closed captioning or voice-to-text transcription. While the models cannot be used for real-time transcription out of the box, their speed and size suggest that others may be able to build near-real-time applications on top of them. Things to try One interesting aspect of the Whisper models is their ability to perform speech translation, generating text transcripts in a different language than the audio input. Developers could experiment with using the model for tasks like simultaneous interpretation or multilingual subtitling. Another avenue to explore is fine-tuning the pre-trained Whisper model on specific datasets or domains. The blog post Fine-Tune Whisper with Transformers provides a guide on how to fine-tune the model with as little as 5 hours of labeled data, which can improve performance on particular languages or use cases.
Updated 5/19/2024
🤯
whisper-large-v2
1.6K
The whisper-large-v2 model is a pre-trained Transformer-based encoder-decoder model for automatic speech recognition (ASR) and speech translation. Trained on 680k hours of labeled data by OpenAI, Whisper models demonstrate a strong ability to generalize to many datasets and domains without the need for fine-tuning. Compared to the original Whisper large model, the whisper-large-v2 model has been trained for 2.5x more epochs with added regularization for improved performance. Model inputs and outputs Inputs Audio samples**: The model takes audio samples as input and performs either speech recognition or speech translation. Outputs Text transcription**: The model outputs text transcriptions of the input audio. For speech recognition, the transcription is in the same language as the audio. For speech translation, the transcription is in a different language than the audio. Timestamps (optional)**: The model can optionally output timestamps for the transcribed text. Capabilities The whisper-large-v2 model exhibits improved robustness to accents, background noise, and technical language compared to many existing ASR systems. It also demonstrates strong zero-shot translation capabilities, allowing it to translate speech from multiple languages into English with high accuracy. What can I use it for? The whisper-large-v2 model can be a useful tool for developers building speech recognition and translation applications. Its strong generalization capabilities suggest it may be particularly valuable for tasks like improving accessibility through real-time captioning, language translation, and other speech-to-text use cases. However, the model's performance can vary across languages, accents, and demographics, so users should carefully evaluate its performance in their specific domain before deployment. Things to try One interesting aspect of the whisper-large-v2 model is its ability to perform long-form transcription of audio samples longer than 30 seconds. By using a chunking algorithm, the model can transcribe audio of arbitrary length, making it a useful tool for transcribing podcasts, lectures, and other long-form audio content. Users can also experiment with fine-tuning the model on their own data to further improve its performance for specific use cases.
Updated 5/19/2024
🔄
clip-vit-large-patch14
1.2K
The clip-vit-large-patch14 model is a CLIP (Contrastive Language-Image Pre-training) model developed by researchers at OpenAI. CLIP is a large multimodal model that can learn visual concepts from natural language supervision. The clip-vit-large-patch14 variant uses a Vision Transformer (ViT) with a large patch size of 14x14 as the image encoder, paired with a text encoder. This configuration allows the model to learn powerful visual representations that can be used for a variety of zero-shot computer vision tasks. Similar CLIP models include the clip-vit-base-patch32, which uses a smaller ViT-B/32 architecture, and the clip-vit-base-patch16, which uses a ViT-B/16 architecture. These models offer different trade-offs in terms of model size, speed, and performance. Another related model is the OWL-ViT from Google, which extends CLIP to enable zero-shot object detection by adding bounding box prediction heads. Model Inputs and Outputs The clip-vit-large-patch14 model takes two types of inputs: Inputs Text**: One or more text prompts to condition the model's predictions on. Image**: An image to be classified or retrieved. Outputs Image-Text Similarity**: A score representing the similarity between the image and each of the provided text prompts. This can be used for zero-shot image classification or retrieval. Capabilities The clip-vit-large-patch14 model is a powerful zero-shot computer vision model that can perform a wide variety of tasks, from fine-grained image classification to open-ended visual recognition. By leveraging the rich visual and language representations learned during pre-training, the model can adapt to new tasks and datasets without requiring any task-specific fine-tuning. For example, the model can be used to classify images of food, vehicles, animals, and more by simply providing text prompts like "a photo of a cheeseburger" or "a photo of a red sports car". The model will output similarity scores for each prompt, allowing you to determine the most relevant classification. What Can I Use It For? The clip-vit-large-patch14 model is a powerful research tool that can enable new applications in computer vision and multimodal AI. Some potential use cases include: Zero-shot Image Classification**: Classify images into a wide range of categories by querying the model with text prompts, without the need for labeled training data. Image Retrieval**: Find the most relevant images in a database given a text description, or vice versa. Multimodal Understanding**: Use the model's joint understanding of vision and language to power applications like visual question answering or image captioning. Transfer Learning**: Fine-tune the model's representations on smaller datasets to boost performance on specific computer vision tasks. Researchers and developers can leverage the clip-vit-large-patch14 model and similar CLIP variants to explore the capabilities and limitations of large multimodal AI systems, as well as investigate their potential societal impacts. Things to Try One interesting aspect of the clip-vit-large-patch14 model is its ability to adapt to a wide range of visual concepts, even those not seen during pre-training. By providing creative or unexpected text prompts, you can uncover the model's strengths and weaknesses in terms of generalization and common sense reasoning. For example, try querying the model with prompts like "a photo of a unicorn" or "a photo of a cyborg robot". While the model may not have seen these exact concepts during training, its strong language understanding can allow it to reason about them and provide relevant similarity scores. Additionally, you can explore the model's performance on specific tasks or datasets, and compare it to other CLIP variants or computer vision models. This can help shed light on the trade-offs between model size, architecture, and pretraining data, and guide future research in this area.
Updated 5/19/2024
🔎
whisper-large
436
The whisper-large model is a pre-trained AI model for automatic speech recognition (ASR) and speech translation, developed by OpenAI. Trained on 680k hours of labelled data, the Whisper models demonstrate a strong ability to generalize to many datasets and domains without the need for fine-tuning. The whisper-large-v2 model is a newer version that surpasses the performance of the original whisper-large model, with no architecture changes. The whisper-medium model is a slightly smaller version with 769M parameters, while the whisper-tiny model is the smallest at 39M parameters. All of these Whisper models are available on the Hugging Face Hub. Model inputs and outputs Inputs Audio samples, which the model converts to log-Mel spectrograms Outputs Textual transcriptions of the input audio, either in the same language as the audio (for speech recognition) or in a different language (for speech translation) The model can also output timestamps for the transcriptions Capabilities The Whisper models demonstrate strong performance on a variety of speech recognition and translation tasks, exhibiting improved robustness to accents, background noise, and technical language. They can also perform zero-shot translation from multiple languages into English. However, the models may occasionally produce text that is not actually spoken in the audio input, a phenomenon known as "hallucination". Their performance also varies across languages, with lower accuracy on low-resource and less common languages. What can I use it for? The Whisper models are primarily intended for use by AI researchers studying model robustness, generalization, capabilities, biases, and constraints. However, the models can also be useful for developers looking to build speech recognition or translation applications, especially for English speech. The models' speed and accuracy make them well-suited for applications that require transcription or translation of large volumes of audio data, such as accessibility tools, media production, and language learning. Developers can build applications on top of the models to enable near-real-time speech recognition and translation. Things to try One interesting aspect of the Whisper models is their ability to perform long-form transcription of audio samples longer than 30 seconds. This is achieved through a chunking algorithm that allows the model to process audio of arbitrary length. Another unique feature is the model's ability to automatically detect the language of the input audio and perform the appropriate speech recognition or translation task. Developers can leverage this by providing the model with "context tokens" that inform it of the desired task and language. Finally, the pre-trained Whisper models can be fine-tuned on smaller datasets to further improve their performance on specific languages or domains. The Fine-Tune Whisper with Transformers blog post provides a step-by-step guide on how to do this.
Updated 5/19/2024
📈
clip-vit-base-patch32
380
The clip-vit-base-patch32 model is a powerful text-to-image AI model developed by OpenAI. It uses a Vision Transformer (ViT) architecture as an image encoder and a masked self-attention Transformer as a text encoder. The model is trained to maximize the similarity between image-text pairs, enabling it to perform zero-shot, arbitrary image classification tasks. Similar models include the Vision Transformer (base-sized model), the BLIP image captioning model, and the OWLViT object detection model. These models all leverage transformer architectures to tackle various vision-language tasks. Model inputs and outputs The clip-vit-base-patch32 model takes two main inputs: images and text. The image is passed through the ViT image encoder, while the text is passed through the Transformer text encoder. The model then outputs a similarity score between the image and text, indicating how well they match. Inputs Images**: The model accepts images of various sizes and formats, which are then processed and resized to a fixed resolution. Text**: The model can handle a wide range of text inputs, from single-word prompts to full sentences or paragraphs. Outputs Similarity scores**: The primary output of the model is a similarity score between the input image and text, indicating how well they match. This score can be used for tasks like zero-shot image classification or image-text retrieval. Capabilities The clip-vit-base-patch32 model is particularly adept at zero-shot image classification, where it can classify images into a wide range of categories without any fine-tuning. This makes the model highly versatile and applicable to a variety of tasks, such as identifying objects, scenes, or activities in images. Additionally, the model's ability to understand the relationship between images and text can be leveraged for tasks like image-text retrieval, where the model can find relevant images for a given text prompt, or vice versa. What can I use it for? The clip-vit-base-patch32 model is primarily intended for use by AI researchers and developers. Some potential applications include: Zero-shot image classification**: Leveraging the model's ability to classify images into a wide range of categories without fine-tuning. Image-text retrieval**: Finding relevant images for a given text prompt, or vice versa, using the model's understanding of image-text relationships. Multimodal learning**: Exploring the potential of combining vision and language models for tasks like visual question answering or image captioning. Probing model biases and limitations**: Studying the model's performance and behavior on a variety of tasks and datasets to better understand its strengths and weaknesses. Things to try One interesting aspect of the clip-vit-base-patch32 model is its ability to perform zero-shot image classification. You could try providing the model with a diverse set of images and text prompts, and see how well it can match the images to the appropriate categories. Another interesting experiment could be to explore the model's performance on more complex, compositional tasks, such as generating images that combine multiple objects or scenes. This could help uncover any limitations in the model's understanding of visual relationships and scene composition. Finally, you could investigate how the model's performance varies across different datasets and domains, to better understand its generalization capabilities and potential biases.
Updated 5/19/2024
🖼️
whisper-tiny
195
The whisper-tiny model is a pre-trained artificial intelligence (AI) model for automatic speech recognition (ASR) and speech translation, created by OpenAI. Trained on 680k hours of labelled data, Whisper models demonstrate a strong ability to generalize to many datasets and domains without the need for fine-tuning. The whisper-tiny model is the smallest of the Whisper checkpoints, with only 39 million parameters. It is available in both English-only and multilingual versions. Similar models include the whisper-large-v3, a general-purpose speech recognition model, the whisper model by OpenAI, the incredibly-fast-whisper model, and the whisperspeech-small model, which is an open-source text-to-speech system built by inverting Whisper. Model inputs and outputs Inputs Audio data, such as recordings of speech Outputs Transcribed text in the same language as the input audio (for speech recognition) Transcribed text in a different language than the input audio (for speech translation) Capabilities The whisper-tiny model can transcribe speech and translate speech to text in multiple languages, demonstrating strong generalization abilities without the need for fine-tuning. It can be used for a variety of applications, such as transcribing audio recordings, adding captions to videos, and enabling multilingual communication. What can I use it for? The whisper-tiny model can be used in various applications that require speech recognition or speech translation, such as: Transcribing lectures, interviews, or other audio recordings Adding captions or subtitles to videos Enabling real-time translation in video conferencing or other communication tools Developing voice-controlled interfaces for various devices and applications Things to try You can experiment with the whisper-tiny model by trying it on different types of audio data, such as recordings of speeches, interviews, or conversations in various languages. You can also explore how the model performs on audio with different levels of noise or quality, and compare its results to other speech recognition or translation models.
Updated 5/19/2024
🔮
whisper-medium
176
The whisper-medium model is a pre-trained speech recognition and translation model developed by OpenAI. It is part of the Whisper family of models, which demonstrate a strong ability to generalize to many datasets and domains without the need for fine-tuning. The whisper-medium model has 769 million parameters and is trained on either English-only or multilingual data. It can be used for both speech recognition, where it transcribes audio in the same language, and speech translation, where it transcribes audio to a different language. The Whisper models are available in a range of sizes, from the whisper-tiny with 39 million parameters to the whisper-large and whisper-large-v2 with 1.55 billion parameters. Model inputs and outputs Inputs Audio samples in various formats and sampling rates Outputs Transcriptions of the input audio, either in the same language (speech recognition) or a different language (speech translation) Optionally, the model can also output timestamps for the transcribed text Capabilities The Whisper models demonstrate strong performance on a variety of speech recognition and translation tasks, including handling accents, background noise, and technical language. They can be used in zero-shot translation, taking audio in one language and translating it to English without any fine-tuning. However, the models can also sometimes generate text that is not actually present in the audio input (known as "hallucination"), and their performance can vary across different languages and accents. What can I use it for? The whisper-medium model and the other Whisper models can be useful for developers and researchers working on improving accessibility tools, such as closed captioning or subtitle generation. The models' speed and accuracy suggest they could be used to build near-real-time speech recognition and translation applications. However, users should be aware of the models' limitations, particularly around potential biases and disparate performance across languages and accents. Things to try One interesting aspect of the Whisper models is their ability to handle audio of up to arbitrary length through a chunking algorithm. This allows the models to be used for long-form transcription, where the audio is split into smaller segments and then reassembled. Users can experiment with this functionality to see how it performs on their specific use cases. Additionally, the Whisper models can be fine-tuned on smaller, domain-specific datasets to improve their performance in particular areas. The blog post on fine-tuning Whisper provides a step-by-step guide on how to do this.
Updated 5/19/2024
👀
whisper-base
165
The whisper-base model is a pre-trained model for automatic speech recognition (ASR) and speech translation developed by OpenAI. Trained on 680,000 hours of labelled data, the Whisper models demonstrate a strong ability to generalize to many datasets and domains without the need for fine-tuning. The model was proposed in the paper Robust Speech Recognition via Large-Scale Weak Supervision and is available on the Hugging Face Hub. The whisper-tiny, whisper-medium, and whisper-large models are similar checkpoints of varying model sizes, also from OpenAI. The smaller models are trained on either English-only or multilingual data, while the larger models are multilingual only. All of the pre-trained checkpoints can be accessed on the Hugging Face Hub. Model inputs and outputs Inputs Audio**: The model takes audio samples as input and converts them to log-Mel spectrograms to feed into the Transformer encoder. Task**: The model is informed of the task to perform (transcription or translation) by passing "context tokens" to the decoder. Language**: The model can be configured to transcribe or translate audio in a specific language by providing the corresponding language token. Outputs Transcription or Translation**: The model outputs a text sequence representing the transcription or translation of the input audio. Timestamps**: Optionally, the model can also output timestamps for the generated text. Capabilities The Whisper models exhibit improved robustness to accents, background noise, and technical language compared to many existing ASR systems. They also demonstrate strong zero-shot translation capabilities, allowing users to translate audio from multiple languages into English. The models perform unevenly across languages, with lower accuracy on low-resource or low-discoverability languages. They also tend to hallucinate text that is not actually spoken in the audio input, and can generate repetitive outputs, though these issues can be mitigated to some extent. What can I use it for? The primary intended users of the Whisper models are AI researchers studying model capabilities, biases, and limitations. However, the models can also be useful as an ASR solution for developers, especially for English speech recognition tasks. The models' transcription and translation capabilities may enable the development of accessibility tools, though they cannot currently be used for real-time applications out of the box. Others may be able to build applications on top of Whisper that allow for near-real-time speech recognition and translation. Things to try Users can explore fine-tuning the pre-trained Whisper models on specialized datasets to improve performance for particular languages or domains. The blog post on fine-tuning Whisper provides a step-by-step guide for this process. Experimenting with different chunking and batching strategies can also help unlock the full potential of the Whisper models for long-form transcription and translation tasks. The ASR Chunking blog post goes into more detail on these techniques.
Updated 5/19/2024
👀
whisper-small
154
The whisper-small model is part of the Whisper family of pre-trained models for automatic speech recognition (ASR) and speech translation. Trained on 680k hours of labelled data, Whisper models demonstrate a strong ability to generalise to many datasets and domains without the need for fine-tuning. The whisper-small model is a 244M parameter version of the Whisper model, available in both English-only and multilingual configurations. Compared to the smaller whisper-tiny model, the whisper-small offers improved performance at the cost of increased model size and complexity. Model inputs and outputs The Whisper models are designed to take audio samples as input and generate transcriptions or translations as output. The WhisperProcessor is used to preprocess the audio inputs into log-Mel spectrograms that the model can understand, and to postprocess the model outputs back into readable text. Inputs Audio samples**: The model accepts raw audio data as input, which the WhisperProcessor converts to log-Mel spectrograms. Outputs Transcriptions/Translations**: The model outputs sequences of text, which can represent either transcriptions (in the same language as the input audio) or translations (to a different language). Capabilities The whisper-small model demonstrates strong performance on a variety of speech recognition and translation tasks, particularly for English and a handful of other high-resource languages. It is robust to factors like accents, background noise, and technical vocabulary. The model can also perform zero-shot translation from multiple languages into English. What can I use it for? The whisper-small model could be useful for developers building speech-to-text applications, especially for English transcription. It may also be applicable for improving accessibility tools that require accurate speech recognition. While the model cannot be used for real-time transcription out of the box, its speed and size suggest that others may be able to build applications on top of it that allow for near-real-time speech recognition and translation. Things to try One interesting aspect of the Whisper models is their ability to perform both speech recognition and speech translation. By setting the appropriate "context tokens", you can control whether the model should transcribe the audio in the same language, or translate it to a different language. This allows for a wide range of potential applications, from captioning videos in multiple languages to building multilingual voice assistants.
Updated 5/19/2024