Sabuhigr
Models by this creator
sabuhi-model

25
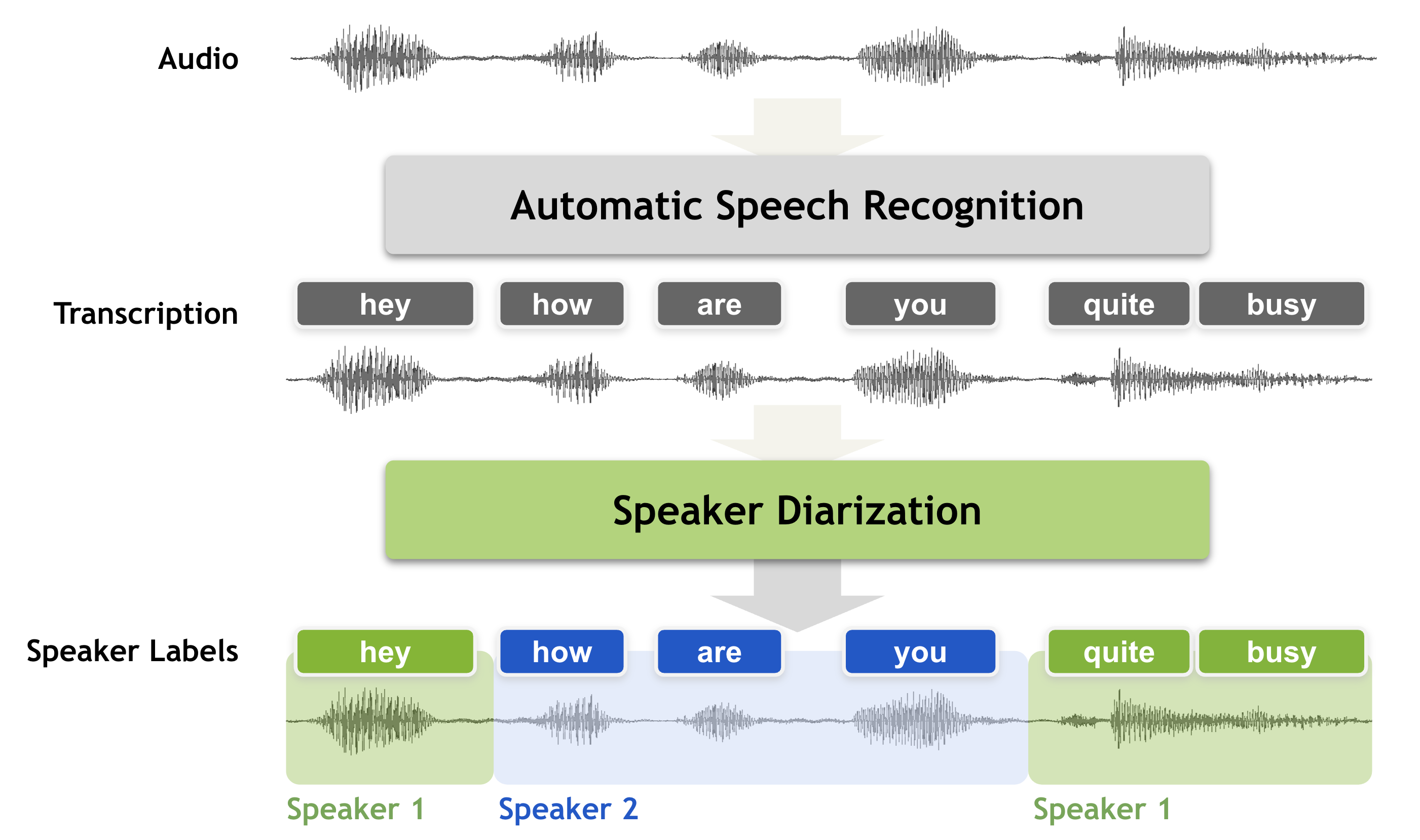
The sabuhi-model is an AI model developed by sabuhigr that builds upon the popular Whisper AI model. This model incorporates channel separation and speaker diarization, allowing it to transcribe audio with multiple speakers and distinguish between them. The sabuhi-model can be seen as an extension of similar Whisper-based models like whisper-large-v3, whisper-subtitles, and the original whisper model. It offers additional capabilities for handling multi-speaker audio, making it a useful tool for transcribing interviews, meetings, and other scenarios with multiple participants. Model inputs and outputs The sabuhi-model takes in an audio file, along with several optional parameters to customize the transcription process. These include the choice of Whisper model, a Hugging Face token for speaker diarization, language settings, and various decoding options. Inputs audio**: The audio file to be transcribed model**: The Whisper model to use, with "large-v2" as the default hf_token**: Your Hugging Face token for speaker diarization language**: The language spoken in the audio (can be left as "None" for language detection) translate**: Whether to translate the transcription to English temperature**: The temperature to use for sampling max_speakers**: The maximum number of speakers to detect (default is 1) min_speakers**: The minimum number of speakers to detect (default is 1) transcription**: The format for the transcription (e.g., "plain text") initial_prompt**: Optional text to provide as a prompt for the first window suppress_tokens**: Comma-separated list of token IDs to suppress during sampling logprob_threshold**: The average log probability threshold for considering the decoding as failed no_speech_threshold**: The probability threshold for considering a segment as silence condition_on_previous_text**: Whether to provide the previous output as a prompt for the next window compression_ratio_threshold**: The gzip compression ratio threshold for considering the decoding as failed temperature_increment_on_fallback**: The temperature increment to use when falling back due to threshold issues Outputs The transcribed text, with speaker diarization and other formatting options as specified in the inputs Capabilities The sabuhi-model inherits the core speech recognition capabilities of the Whisper model, but also adds the ability to separate and identify multiple speakers within the audio. This makes it a useful tool for transcribing meetings, interviews, and other scenarios where multiple people are speaking. What can I use it for? The sabuhi-model can be used for a variety of applications that involve transcribing audio with multiple speakers, such as: Generating transcripts for interviews, meetings, or conference calls Creating subtitles or captions for videos with multiple speakers Improving the accessibility of audio-based content by providing text-based alternatives Enabling better search and indexing of audio-based content by generating transcripts Companies working on voice assistants, video conferencing tools, or media production workflows may find the sabuhi-model particularly useful for their needs. Things to try One interesting aspect of the sabuhi-model is its ability to handle audio with multiple speakers and identify who is speaking at any given time. This could be particularly useful for analyzing the dynamics of a conversation, tracking who speaks the most, or identifying the main speakers in a meeting or interview. Additionally, the model's various decoding options, such as the ability to suppress certain tokens or adjust the temperature, provide opportunities to experiment and fine-tune the transcription output to better suit specific use cases or preferences.
Updated 9/18/2024

sabuhi-model-v2
22
The sabuhi-model-v2 is a Whisper AI model developed by sabuhigr that can be used for adding domain-specific words to improve speech recognition accuracy. It is an extension of the sabuhi-model, which also includes channel separation and speaker diarization capabilities. This model can be compared to other Whisper-based models like whisper-subtitles, whisper-large-v3, the original whisper model, and the incredibly-fast-whisper model. Model inputs and outputs The sabuhi-model-v2 takes in an audio file and various optional parameters to customize the speech recognition process. The model can output the transcribed text in a variety of formats, including plain text, with support for translation to English. It also allows for the inclusion of domain-specific words to improve accuracy. Inputs audio**: The audio file to be transcribed model**: The Whisper model to use, with the default being large-v2 hf_token**: A Hugging Face token for speaker diarization language**: The language spoken in the audio, or None to perform language detection translate**: A boolean flag to translate the text to English temperature**: The temperature to use for sampling max_speakers**: The maximum number of speakers to detect min_speakers**: The minimum number of speakers to detect transcription**: The format for the transcription output suppress_tokens**: A comma-separated list of token IDs to suppress during sampling logprob_threshold**: The minimum average log probability for the decoding to be considered successful no_speech_threshold**: The probability threshold for considering a segment as silence domain_specific_words**: A comma-separated list of domain-specific words to include Outputs The transcribed text in the specified format Capabilities The sabuhi-model-v2 extends the capabilities of the original sabuhi-model by allowing for the inclusion of domain-specific words. This can improve the accuracy of the speech recognition, particularly in specialized domains. The model also supports speaker diarization and channel separation, which can be useful for transcribing multi-speaker audio. What can I use it for? The sabuhi-model-v2 can be used for a variety of applications that require accurate speech recognition, such as transcription, subtitling, or voice-controlled interfaces. By incorporating domain-specific words, the model can be particularly useful in industries or applications that require specialized vocabulary, such as medical, legal, or technical fields. Things to try One interesting thing to try with the sabuhi-model-v2 is to experiment with the domain-specific words feature. By providing a list of domain-specific terms, you can see how the model's accuracy and performance change compared to using the default Whisper model. Additionally, you can try adjusting the various input parameters, such as the temperature, suppressed tokens, and speaker detection thresholds, to see how they impact the transcription results.
Updated 9/18/2024