kosmos-2.5
Maintainer: microsoft

136
🏋️
| Property | Value |
|---|---|
| Run this model | Run on HuggingFace |
| API spec | View on HuggingFace |
| Github link | No Github link provided |
| Paper link | No paper link provided |
Create account to get full access
Model overview
Kosmos-2.5 is a multimodal literate model from Microsoft Document AI that excels at text-intensive image understanding tasks. Trained on a large-scale dataset of text-rich images, it can generate spatially-aware text blocks and structured markdown output, making it a versatile tool for real-world applications involving text-rich visuals. The model's unified multimodal architecture and flexible prompt-based approach allow it to adapt to various text-intensive image understanding tasks through fine-tuning, setting it apart from similar models like Kosmos-G and Kosmos-2.
Model inputs and outputs
Kosmos-2.5 takes text prompts and images as inputs, and generates spatially-aware text blocks and structured markdown output. The model can be used for a variety of text-intensive image understanding tasks, including phrase grounding, referring expression generation, grounded VQA, and image captioning.
Inputs
- Text prompt: A task-specific prompt that guides the model's generation, such as "<grounding><phrase>a snowman</phrase>" for phrase grounding or "<grounding>Question: What is special about this image? Answer:" for grounded VQA.
- Image: The text-rich image to be processed by the model.
Outputs
- Spatially-aware text blocks: The model generates text blocks with their corresponding spatial coordinates within the input image.
- Structured markdown output: The model can produce structured text output in markdown format, capturing the styles and structures of the text in the image.
Capabilities
Kosmos-2.5 excels at understanding and generating text from text-intensive images. It can perform a variety of tasks, such as locating and describing specific elements in an image, answering questions about the content of an image, and generating captions that capture the key information in an image. The model's unified multimodal architecture and flexible prompt-based approach make it a powerful tool for real-world applications involving text-rich visuals.
What can I use it for?
Kosmos-2.5 can be used for a wide range of applications that involve text-intensive images, such as:
- Document understanding: Extracting structured information from scanned documents, forms, or other text-rich visuals.
- Image-to-markdown conversion: Generating markdown-formatted text output from images of text, preserving the layout and formatting.
- Multimodal search and retrieval: Enabling users to search for and retrieve relevant text-rich images using natural language queries.
- Automated report generation: Generating summaries or annotations for images of technical diagrams, scientific figures, or other data visualizations.
By leveraging the model's versatility and adaptability through fine-tuning, developers can tailor Kosmos-2.5 to their specific needs and create innovative solutions for a variety of text-intensive image processing tasks.
Things to try
One interesting aspect of Kosmos-2.5 is its ability to generate spatially-aware text blocks and structured markdown output. This can be particularly useful for tasks like document understanding, where preserving the layout and formatting of the original text is crucial. You could try using the model to extract key information from scanned forms or invoices, or to generate markdown-formatted summaries of technical diagrams or data visualizations.
Another interesting avenue to explore is the model's potential for multimodal search and retrieval. You could experiment with using Kosmos-2.5 to enable users to search for relevant text-rich images using natural language queries, and then have the model generate informative summaries or annotations to help users understand the content of the retrieved images.
Overall, the versatility and adaptability of Kosmos-2.5 make it a powerful tool for a wide range of text-intensive image processing tasks. By exploring the model's capabilities and experimenting with different applications, you can unlock its full potential and create innovative solutions that leverage the power of multimodal AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
kosmos-2
1
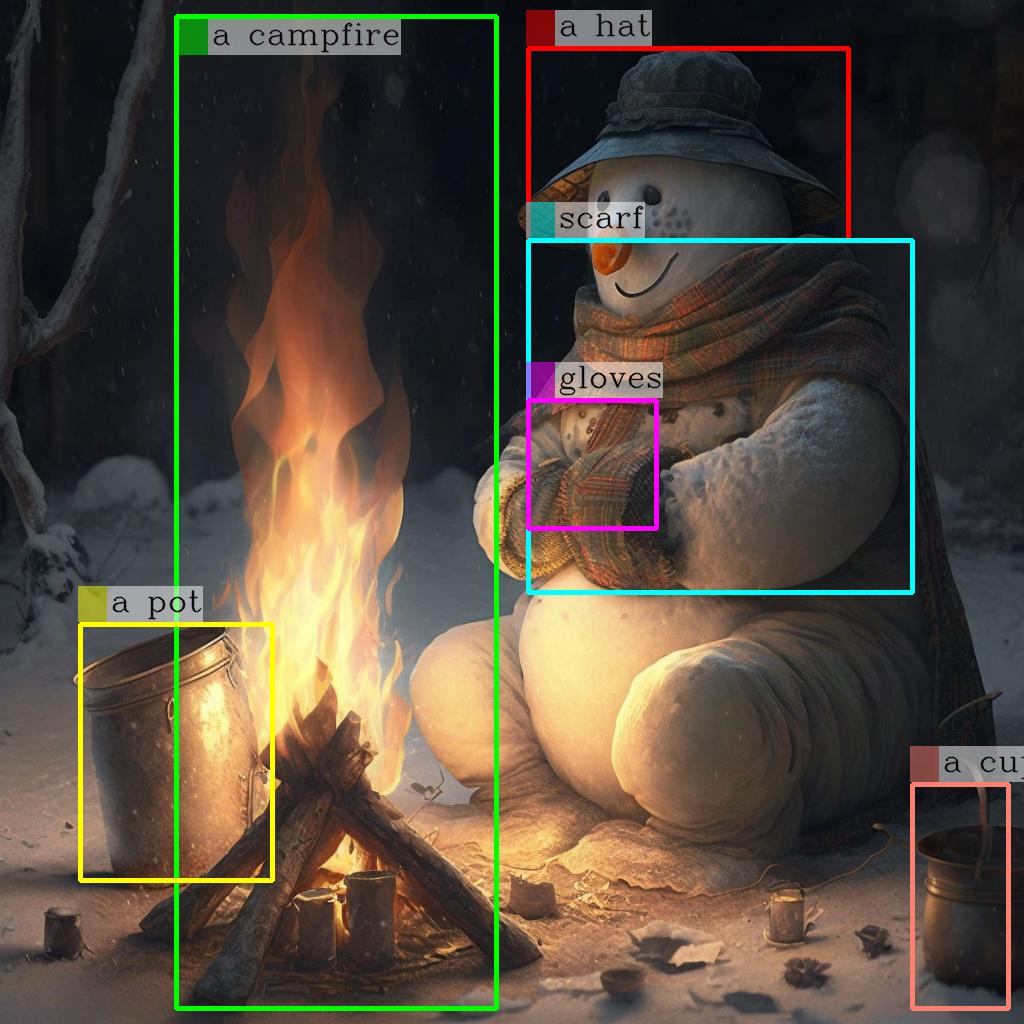
kosmos-2 is a large language model developed by Microsoft that aims to ground multimodal language models to the real world. It is similar to other models created by the same maintainer, such as Kosmos-G, Moondream1, and DeepSeek-VL, which focus on generating images, performing vision-language tasks, and understanding real-world applications. Model inputs and outputs kosmos-2 takes an image as input and outputs a text description of the contents of the image, including bounding boxes around detected objects. The model can also provide a more detailed description if requested. Inputs Image**: An input image to be analyzed Outputs Text**: A description of the contents of the input image Image**: The input image with bounding boxes around detected objects Capabilities kosmos-2 is capable of detecting and describing various objects, scenes, and activities in an input image. It can identify and localize multiple objects within an image and provide a textual summary of its contents. What can I use it for? kosmos-2 can be useful for a variety of applications that require image understanding, such as visual search, image captioning, and scene understanding. It could be used to enhance user experiences in e-commerce, social media, or other image-driven applications. The model's ability to ground language to the real world also makes it potentially useful for tasks like image-based question answering or visual reasoning. Things to try One interesting aspect of kosmos-2 is its potential to be used in conjunction with other models like Kosmos-G to enable multimodal applications that combine image generation and understanding. Developers could explore ways to leverage kosmos-2's capabilities to build novel applications that seamlessly integrate visual and language processing.
Updated Invalid Date
🌀
kosmos-2-patch14-224
128
The kosmos-2-patch14-224 model is a HuggingFace implementation of the original Kosmos-2 model from Microsoft. Kosmos-2 is a multimodal large language model designed to ground language understanding to the real world. It was developed by researchers at Microsoft to improve upon the capabilities of earlier multimodal models. The Kosmos-2 model is similar to other recent multimodal models like Kosmos-2 from lucataco and Animagine XL 2.0 from Linaqruf. These models aim to combine language understanding with vision understanding to enable more grounded, contextual language generation and reasoning. Model Inputs and Outputs Inputs Text prompt**: A natural language description or instruction to guide the model's output Image**: An image that the model can use to ground its language understanding and generation Outputs Generated text**: The model's response to the provided text prompt, grounded in the input image Capabilities The kosmos-2-patch14-224 model excels at generating text that is strongly grounded in visual information. For example, when given an image of a snowman warming himself by a fire and the prompt "An image of", the model generates a detailed description that references the key elements of the scene. This grounding of language to visual context makes the Kosmos-2 model well-suited for tasks like image captioning, visual question answering, and multimodal dialogue. The model can leverage its understanding of both language and vision to provide informative and coherent responses. What Can I Use It For? The kosmos-2-patch14-224 model's multimodal capabilities make it a versatile tool for a variety of applications: Content Creation**: The model can be used to generate descriptive captions, stories, or narratives based on input images, enhancing the creation of visually-engaging content. Assistive Technology**: By understanding both language and visual information, the model can be leveraged to build more intelligent and contextual assistants for tasks like image search, visual question answering, and image-guided instruction following. Research and Exploration**: Academics and researchers can use the Kosmos-2 model to explore the frontiers of multimodal AI, studying how language and vision can be effectively combined to enable more human-like understanding and reasoning. Things to Try One interesting aspect of the kosmos-2-patch14-224 model is its ability to generate text that is tailored to the specific visual context provided. By experimenting with different input images, you can observe how the model's language output changes to reflect the details and nuances of the visual information. For example, try providing the model with a variety of images depicting different scenes, characters, or objects, and observe how the generated text adapts to accurately describe the visual elements. This can help you better understand the model's strengths in grounding language to the real world. Additionally, you can explore the limits of the model's multimodal capabilities by providing unusual or challenging input combinations, such as abstract or low-quality images, to see how it handles such cases. This can provide valuable insights into the model's robustness and potential areas for improvement.
Updated Invalid Date

kosmos-g
3
Kosmos-G is a multimodal large language model developed by adirik that can generate images based on text prompts. It builds upon previous work in text-to-image generation, such as the stylemc model, to enable more contextual and versatile image creation. Kosmos-G can take multiple input images and a text prompt to generate new images that blend the visual and semantic information. This allows for more nuanced and compelling image generation compared to models that only use text prompts. Model inputs and outputs Kosmos-G takes a variety of inputs to generate new images, including one or two starting images, a text prompt, and various configuration settings. The model outputs a set of generated images that match the provided prompt and visual context. Inputs image1**: The first input image, used as a starting point for the generation image2**: An optional second input image, which can provide additional visual context prompt**: The text prompt describing the desired output image negative_prompt**: An optional text prompt specifying elements to avoid in the generated image num_images**: The number of images to generate num_inference_steps**: The number of steps to use during the image generation process text_guidance_scale**: A parameter controlling the influence of the text prompt on the generated images Outputs Output**: An array of generated image URLs Capabilities Kosmos-G can generate unique and contextual images based on a combination of input images and text prompts. It is able to blend the visual information from the starting images with the semantic information in the text prompt to create new compositions that maintain the essence of the original visuals while incorporating the desired conceptual elements. This allows for more flexible and expressive image generation compared to models that only use text prompts. What can I use it for? Kosmos-G can be used for a variety of creative and practical applications, such as: Generating concept art or illustrations for creative projects Producing visuals for marketing and advertising campaigns Enhancing existing images by blending them with new text-based elements Aiding in the ideation and visualization process for product design or other visual projects The model's ability to leverage both visual and textual inputs makes it a powerful tool for users looking to create unique and expressive imagery. Things to try One interesting aspect of Kosmos-G is its ability to generate images that seamlessly integrate multiple visual and conceptual elements. Try providing the model with a starting image and a prompt that describes a specific scene or environment, then observe how it blends the visual elements from the input image with the new conceptual elements to create a cohesive and compelling result. You can also experiment with different combinations of input images and text prompts to see the range of outputs the model can produce.
Updated Invalid Date
⚙️
Phi-3.5-vision-instruct
465
The Phi-3.5-vision-instruct is a lightweight, state-of-the-art open multimodal model built upon datasets which include synthetic data and filtered publicly available websites, with a focus on very high-quality, reasoning-dense data both on text and vision. It belongs to the Phi-3 model family, and the multimodal version can support a 128K context length. The model underwent a rigorous enhancement process, incorporating both supervised fine-tuning and direct preference optimization to ensure precise instruction adherence and robust safety measures. Model inputs and outputs Inputs Text**: The model can take text input using a chat format. Images**: The model can process single images or multiple images/video frames for tasks like image comparison and multi-image/video summarization. Outputs Generated text**: The model generates relevant text in response to the input prompt. Capabilities The Phi-3.5-vision-instruct model provides capabilities for general purpose AI systems and applications with visual and text input requirements. Key use cases include memory/compute constrained environments, latency-bound scenarios, general image understanding, optical character recognition, chart and table understanding, multiple image comparison, and multi-image or video clip summarization. What can I use it for? The Phi-3.5-vision-instruct model is intended for broad commercial and research use in English. It can be used as a building block for generative AI powered features, accelerating research on language and multimodal models. Some potential use cases include: Developing AI assistants with visual understanding capabilities Automating document processing tasks like extracting insights from charts and tables Enabling multi-modal interfaces for product search and recommendation systems Things to try The Phi-3.5-vision-instruct model's multi-frame image understanding and reasoning capabilities allow for interesting applications like detailed image comparison, multi-image summarization, and optical character recognition. Developers could explore leveraging these abilities to build novel AI-powered features for their products and services.
Updated Invalid Date