openvoice
Maintainer: chenxwh

46

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
The openvoice model is a versatile instant voice cloning model developed by the team at MyShell.ai. As detailed in their paper and on the website, the key advantages of openvoice are accurate tone color cloning, flexible voice style control, and zero-shot cross-lingual voice cloning. This model has been powering the instant voice cloning capability on the MyShell platform since May 2023, with tens of millions of uses by global users.
The openvoice model is similar to other voice cloning models like [object Object] and [object Object], which also focus on creating realistic voice clones. However, openvoice stands out with its advanced capabilities in voice style control and cross-lingual cloning. The model is also related to speech recognition models like [object Object] and [object Object], which have different use cases focused on transcription.
Model inputs and outputs
The openvoice model takes three main inputs: the input text, a reference audio file, and the desired language. The text is what will be spoken by the cloned voice, the reference audio provides the tone color to clone, and the language specifies the language of the generated speech.
Inputs
- Text: The input text that will be spoken by the cloned voice
- Audio: A reference audio file that provides the tone color to be cloned
- Language: The desired language of the generated speech
Outputs
- Audio: The generated audio with the cloned voice speaking the input text
Capabilities
The openvoice model excels at accurately cloning the tone color and vocal characteristics of the reference audio, while also enabling flexible control over the voice style, such as emotion and accent. Notably, the model can perform zero-shot cross-lingual voice cloning, meaning it can generate speech in languages not seen during training.
What can I use it for?
The openvoice model can be used for a variety of applications, such as creating personalized voice assistants, dubbing foreign language content, or generating audio for podcasts and audiobooks. By leveraging the model's ability to clone voices and control style, users can create unique and engaging audio content tailored to their needs.
Things to try
One interesting thing to try with the openvoice model is to experiment with different reference audio files and see how the cloned voice changes. You can also try adjusting the style parameters, such as emotion and accent, to create different variations of the cloned voice. Additionally, the model's cross-lingual capabilities allow you to generate speech in languages you may not be familiar with, opening up new creative possibilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
📊
openvoice
9
The openvoice model, developed by the team at MyShell, is a versatile instant voice cloning AI that can accurately clone the tone color and generate speech in multiple languages and accents. It offers flexible control over voice styles, such as emotion and accent, as well as other style parameters like rhythm, pauses, and intonation. The model also supports zero-shot cross-lingual voice cloning, allowing it to generate speech in languages not present in the training dataset. The openvoice model builds upon several excellent open-source projects, including TTS, VITS, and VITS2. It has been powering the instant voice cloning capability of myshell.ai since May 2023 and has been used tens of millions of times by users worldwide, witnessing explosive growth on the platform. Model inputs and outputs Inputs Audio**: The reference audio used to clone the tone color. Text**: The text to be spoken by the cloned voice. Speed**: The speed scale of the output audio. Language**: The language of the audio to be generated. Outputs Output**: The generated audio in the cloned voice. Capabilities The openvoice model excels at accurate tone color cloning, flexible voice style control, and zero-shot cross-lingual voice cloning. It can generate speech in multiple languages and accents, while allowing for granular control over voice styles, including emotion and accent, as well as other parameters like rhythm, pauses, and intonation. What can I use it for? The openvoice model can be used for a variety of applications, such as: Instant voice cloning for audio, video, or gaming content Customized text-to-speech for assistants, chatbots, or audiobooks Multilingual voice acting and dubbing Voice conversion and style transfer Things to try With the openvoice model, you can experiment with different input reference audios to clone a wide range of voices and accents. You can also play with the style parameters to create unique and expressive speech outputs. Additionally, you can explore the model's cross-lingual capabilities by generating speech in languages not present in the training data.
Updated Invalid Date

video-retalking
71
The video-retalking model, created by maintainer chenxwh, is an AI system that can edit the faces of a real-world talking head video according to input audio, producing a high-quality and lip-synced output video even with a different emotion. This model builds upon previous work like VideoReTalking, Wav2Lip, and GANimation, disentangling the task into three sequential steps: face video generation with a canonical expression, audio-driven lip-sync, and face enhancement for improving photorealism. Model inputs and outputs The video-retalking model takes two inputs: a talking-head video file and an audio file. It then outputs a new video file where the face in the original video is lip-synced to the input audio. Inputs Face**: Input video file of a talking-head Input Audio**: Input audio file to drive the lip-sync Outputs Output Video**: New video file with the face lip-synced to the input audio Capabilities The video-retalking model is capable of editing the faces in a video to match input audio, even if the original video and audio do not align. It can generate new facial animations with different expressions and emotions compared to the original video. The model is designed to work on "in the wild" videos without requiring manual alignment or preprocessing. What can I use it for? The video-retalking model can be used for a variety of video editing and content creation tasks. For example, you could use it to dub foreign language videos into your native language, or to animate a character's face to match pre-recorded dialogue. It could also be used to create custom talking-head videos for presentations, tutorials, or other multimedia content. Companies could leverage this technology to easily create personalized marketing or training videos. Things to try One interesting aspect of the video-retalking model is its ability to modify the expression of the face in the original video. By providing different expression templates, you can experiment with creating talking-head videos that convey different emotional states, like surprise or anger, even if the original video had a neutral expression. This could enable new creative possibilities for video storytelling and content personalization.
Updated Invalid Date
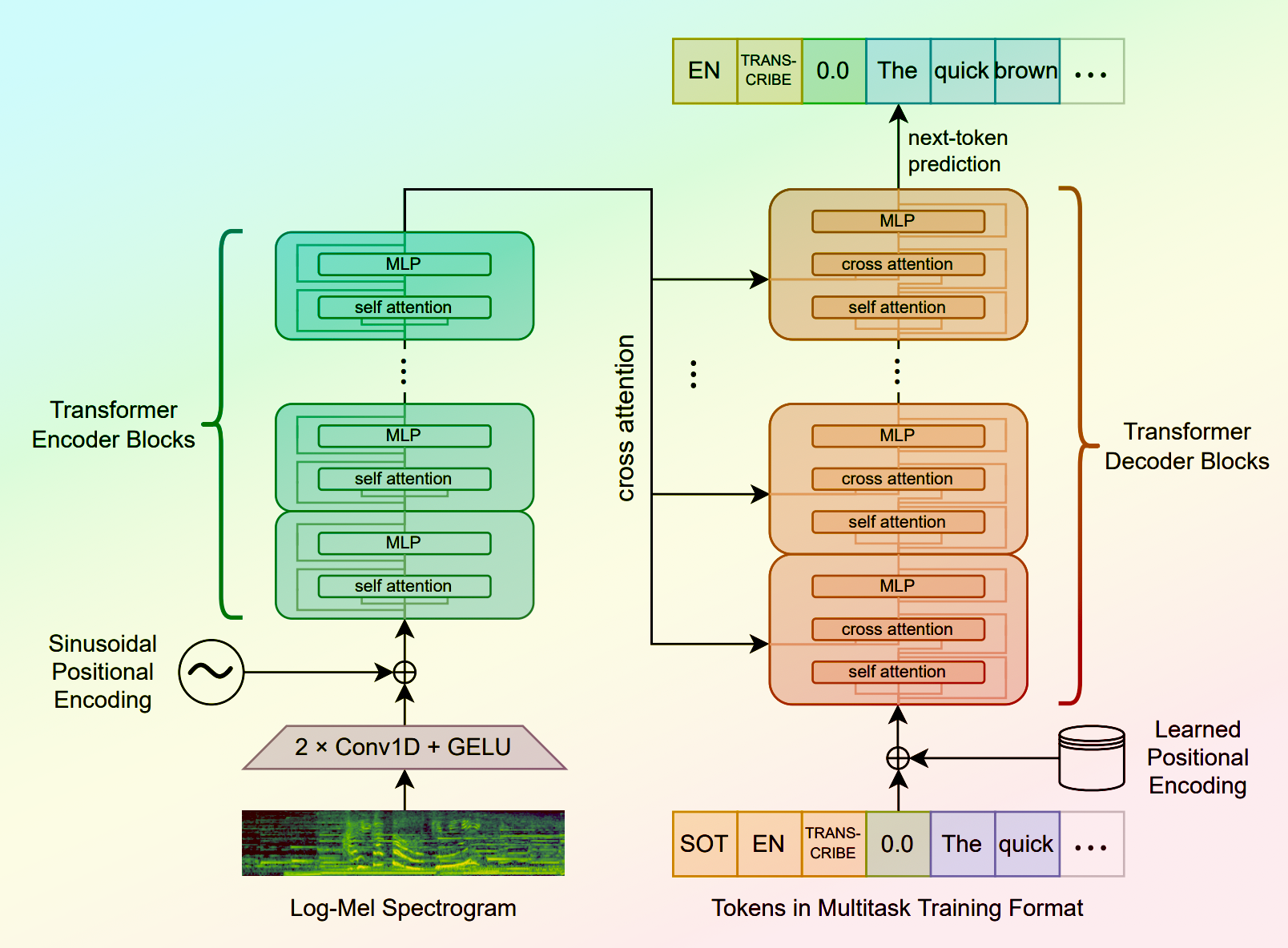
whisper
30.8K
Whisper is a general-purpose speech recognition model developed by OpenAI. It is capable of converting speech in audio to text, with the ability to translate the text to English if desired. Whisper is based on a large Transformer model trained on a diverse dataset of multilingual and multitask speech recognition data. This allows the model to handle a wide range of accents, background noises, and languages. Similar models like whisper-large-v3, incredibly-fast-whisper, and whisper-diarization offer various optimizations and additional features built on top of the core Whisper model. Model inputs and outputs Whisper takes an audio file as input and outputs a text transcription. The model can also translate the transcription to English if desired. The input audio can be in various formats, and the model supports a range of parameters to fine-tune the transcription, such as temperature, patience, and language. Inputs Audio**: The audio file to be transcribed Model**: The specific version of the Whisper model to use, currently only large-v3 is supported Language**: The language spoken in the audio, or None to perform language detection Translate**: A boolean flag to translate the transcription to English Transcription**: The format for the transcription output, such as "plain text" Initial Prompt**: An optional initial text prompt to provide to the model Suppress Tokens**: A list of token IDs to suppress during sampling Logprob Threshold**: The minimum average log probability threshold for a successful transcription No Speech Threshold**: The threshold for considering a segment as silence Condition on Previous Text**: Whether to provide the previous output as a prompt for the next window Compression Ratio Threshold**: The maximum compression ratio threshold for a successful transcription Temperature Increment on Fallback**: The temperature increase when the decoding fails to meet the specified thresholds Outputs Transcription**: The text transcription of the input audio Language**: The detected language of the audio (if language input is None) Tokens**: The token IDs corresponding to the transcription Timestamp**: The start and end timestamps for each word in the transcription Confidence**: The confidence score for each word in the transcription Capabilities Whisper is a powerful speech recognition model that can handle a wide range of accents, background noises, and languages. The model is capable of accurately transcribing audio and optionally translating the transcription to English. This makes Whisper useful for a variety of applications, such as real-time captioning, meeting transcription, and audio-to-text conversion. What can I use it for? Whisper can be used in various applications that require speech-to-text conversion, such as: Captioning and Subtitling**: Automatically generate captions or subtitles for videos, improving accessibility for viewers. Meeting Transcription**: Transcribe audio recordings of meetings, interviews, or conferences for easy review and sharing. Podcast Transcription**: Convert audio podcasts to text, making the content more searchable and accessible. Language Translation**: Transcribe audio in one language and translate the text to another, enabling cross-language communication. Voice Interfaces**: Integrate Whisper into voice-controlled applications, such as virtual assistants or smart home devices. Things to try One interesting aspect of Whisper is its ability to handle a wide range of languages and accents. You can experiment with the model's performance on audio samples in different languages or with various background noises to see how it handles different real-world scenarios. Additionally, you can explore the impact of the different input parameters, such as temperature, patience, and language detection, on the transcription quality and accuracy.
Updated Invalid Date
↗️
whisper
52
whisper is a large, general-purpose speech recognition model developed by OpenAI. It is trained on a diverse dataset of audio and can perform a variety of speech-related tasks, including multilingual speech recognition, speech translation, and spoken language identification. The whisper model is available in different sizes, with the larger models offering better accuracy at the cost of increased memory and compute requirements. The maintainer, cjwbw, has also created several similar models, such as stable-diffusion-2-1-unclip, anything-v3-better-vae, and dreamshaper, that explore different approaches to image generation and manipulation. Model inputs and outputs The whisper model is a sequence-to-sequence model that takes audio as input and produces a text transcript as output. It can handle a variety of audio formats, including FLAC, MP3, and WAV files. The model can also be used to perform speech translation, where the input audio is in one language and the output text is in another language. Inputs audio**: The audio file to be transcribed, in a supported format such as FLAC, MP3, or WAV. model**: The size of the whisper model to use, with options ranging from tiny to large. language**: The language spoken in the audio, or None to perform language detection. translate**: A boolean flag to indicate whether the output should be translated to English. Outputs transcription**: The text transcript of the input audio, in the specified format (e.g., plain text). Capabilities The whisper model is capable of performing high-quality speech recognition across a wide range of languages, including less common languages. It can also handle various accents and speaking styles, making it a versatile tool for transcribing diverse audio content. The model's ability to perform speech translation is particularly useful for applications where users need to consume content in a language they don't understand. What can I use it for? The whisper model can be used in a variety of applications, such as: Transcribing audio recordings for content creation, research, or accessibility purposes. Translating speech-based content, such as videos or podcasts, into multiple languages. Integrating speech recognition and translation capabilities into chatbots, virtual assistants, or other conversational interfaces. Automating the captioning or subtitling of video content. Things to try One interesting aspect of the whisper model is its ability to detect the language spoken in the audio, even if it's not provided as an input. This can be useful for applications where the language is unknown or variable, such as transcribing multilingual conversations. Additionally, the model's performance can be fine-tuned by adjusting parameters like temperature, patience, and suppressed tokens, which can help improve accuracy for specific use cases.
Updated Invalid Date