grounding-dino
Maintainer: adirik

132

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
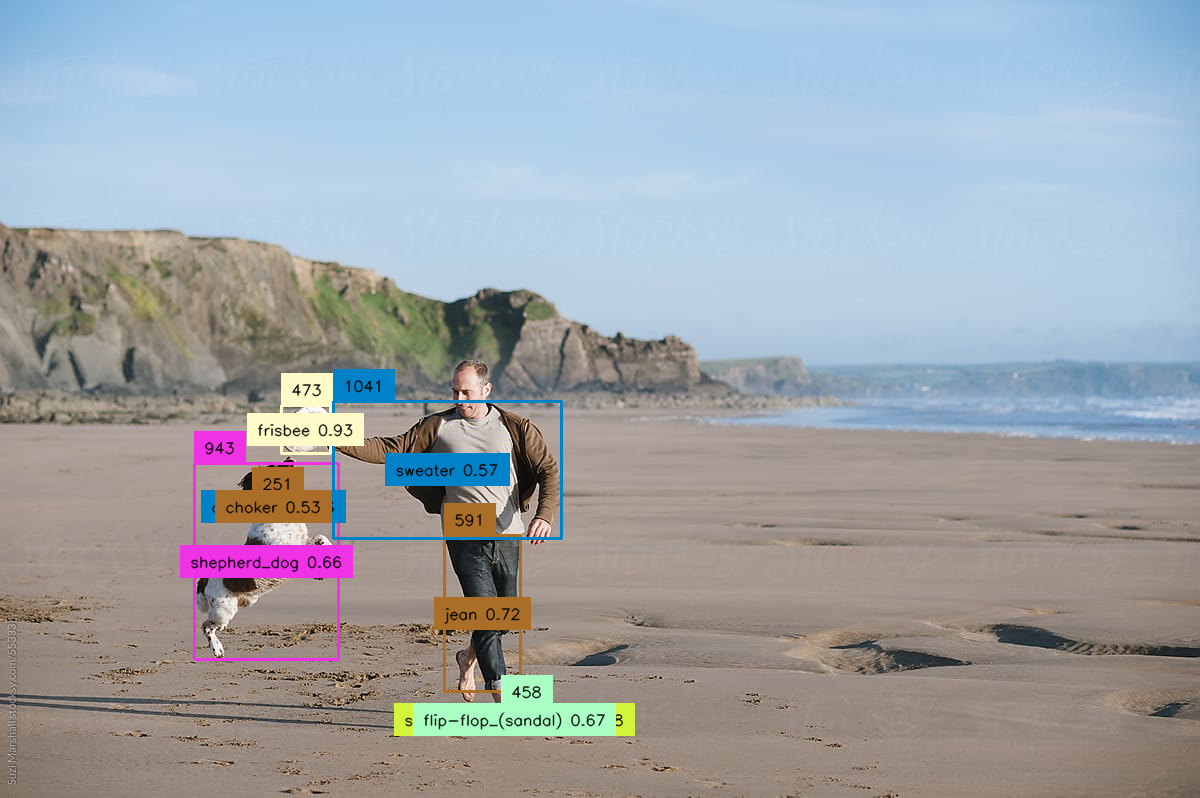
grounding-dino is an AI model that can detect arbitrary objects in images using human text inputs such as category names or referring expressions. It combines a Transformer-based detector called DINO with grounded pre-training to achieve open-vocabulary and text-guided object detection. The model was developed by IDEA Research and is available as a Cog model on Replicate.
Similar models include GroundingDINO, which also uses the Grounding DINO approach, as well as other object detection models like stable-diffusion and text-extract-ocr.
Model inputs and outputs
grounding-dino takes an image and a comma-separated list of text queries describing the objects you want to detect. It then outputs the detected objects with bounding boxes and predicted labels. The model also allows you to adjust the confidence thresholds for the box and text predictions.
Inputs
- image: The input image to query
- query: Comma-separated text queries describing the objects to detect
- box_threshold: Confidence level threshold for object detection
- text_threshold: Confidence level threshold for predicted labels
- show_visualisation: Option to draw and visualize the bounding boxes on the image
Outputs
- Detected objects with bounding boxes and predicted labels
Capabilities
grounding-dino can detect a wide variety of objects in images using just natural language descriptions. This makes it a powerful tool for tasks like content moderation, image retrieval, and visual analysis. The model is particularly adept at handling open-vocabulary detection, allowing you to query for any object, not just a predefined set.
What can I use it for?
You can use grounding-dino for a variety of applications that require object detection, such as:
- Visual search: Quickly find specific objects in large image databases using text queries.
- Automated content moderation: Detect inappropriate or harmful objects in user-generated content.
- Augmented reality: Overlay relevant information on objects in the real world using text-guided object detection.
- Robotic perception: Enable robots to understand and interact with their environment using language-guided object detection.
Things to try
Try experimenting with different types of text queries to see how the model handles various object descriptions. You can also play with the confidence thresholds to balance the precision and recall of the object detections. Additionally, consider integrating grounding-dino into your own applications to add powerful object detection capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
🤷
GroundingDINO
110
GroundingDINO is a novel object detection model developed by Shilong Liu and colleagues. It combines the power of the DINO self-supervised vision transformer with grounded pre-training on image-text pairs, enabling it to perform open-set zero-shot object detection. In contrast to traditional object detectors that require extensive annotated training data, GroundingDINO can detect objects in images using only natural language descriptions, without needing any bounding box labels. The model was trained on a large-scale dataset of image-text pairs, allowing it to ground visual concepts to their linguistic representations. This enables GroundingDINO to recognize a diverse set of object categories beyond the typical closed-set of a standard object detector. The paper demonstrates the model's impressive performance on a variety of benchmarks, outperforming prior zero-shot and few-shot object detectors. Model Inputs and Outputs Inputs Natural language text**: A free-form text description of the objects to be detected in an image. Outputs Bounding boxes**: The model outputs a set of bounding boxes corresponding to the detected objects, along with their class labels. Confidence scores**: Each detected object is associated with a confidence score indicating the model's certainty of the detection. Capabilities GroundingDINO exhibits strong zero-shot object detection capabilities, allowing it to identify a wide variety of objects in images using only text descriptions, without requiring any bounding box annotations. The model achieves state-of-the-art performance on several open-set detection benchmarks, demonstrating its ability to generalize beyond a fixed set of categories. One compelling example showcased in the paper is GroundingDINO's ability to detect unusual objects like "a person riding a unicycle" or "a dog wearing sunglasses." These types of compositional and unconventional object descriptions highlight the model's flexibility and understanding of complex visual concepts. What can I use it for? GroundingDINO has numerous potential applications in computer vision and multimedia understanding. Its zero-shot capabilities make it well-suited for tasks like: Image and video annotation**: Automatically generating detailed textual descriptions of the contents of images and videos, without the need for extensive manual labeling. Robotic perception**: Allowing robots to recognize and interact with a wide range of objects in unstructured environments, using natural language commands. Intelligent assistants**: Powering AI assistants that can understand and respond to queries about the visual world using grounded language understanding. The maintainer, ShilongLiu, has also provided a Colab demo to showcase the model's capabilities. Things to try One interesting aspect of GroundingDINO is its ability to detect objects using complex, compositional language descriptions. Try experimenting with prompts that combine multiple attributes or describe unusual object configurations, such as "a person riding a unicycle" or "a dog wearing sunglasses." Observe how the model's performance compares to more straightforward object descriptions. Additionally, you could explore the model's ability to generalize to new, unseen object categories by trying prompts for objects that are not part of the standard object detection datasets. This can help uncover the model's true open-set capabilities and understanding of visual concepts. Overall, GroundingDINO represents an exciting advancement in the field of object detection, showcasing the potential of language-guided vision models to tackle complex and open-ended visual understanding tasks.
Updated Invalid Date
codet
1
The codet model is an object detection AI model developed by Replicate and maintained by the creator adirik. It is designed to detect objects in images with high accuracy. The codet model shares similarities with other object detection models like Marigold, which focuses on monocular depth estimation, and StyleMC, MaSaCtrl-Anything-v4-0, and MaSaCtrl-Stable-Diffusion-v1-4, which are focused on text-guided image generation and editing. Model inputs and outputs The codet model takes an input image and a confidence threshold, and outputs an array of image URIs. The input image is used for object detection, and the confidence threshold is used to filter the detected objects based on their confidence scores. Inputs Image**: The input image to be processed for object detection. Confidence**: The confidence threshold to filter the detected objects. Show Visualisation**: An optional flag to display the detection results on the input image. Outputs Array of Image URIs**: The output of the model is an array of image URIs, where each URI represents a detected object in the input image. Capabilities The codet model is capable of detecting objects in images with high accuracy. It uses a novel approach called "Co-Occurrence Guided Region-Word Alignment" to improve the model's performance on open-vocabulary object detection tasks. What can I use it for? The codet model can be useful in a variety of applications, such as: Image analysis and understanding**: The model can be used to analyze and understand the contents of images, which can be valuable in fields like e-commerce, security, and robotics. Visual search and retrieval**: The model can be used to build visual search engines or image retrieval systems, where users can search for specific objects within a large collection of images. Augmented reality and computer vision**: The model can be integrated into AR/VR applications or computer vision systems to provide real-time object detection and identification. Things to try Some ideas for things to try with the codet model include: Experiment with different confidence thresholds to see how it affects the accuracy and number of detected objects. Use the model to analyze a variety of images and see how it performs on different types of objects. Integrate the model into a larger system, such as an image-processing pipeline or a computer vision application.
Updated Invalid Date

grounded_sam
606
grounded_sam is an AI model that combines the strengths of Grounding DINO and Segment Anything to provide a powerful pipeline for solving complex masking problems. Grounding DINO is a strong zero-shot object detector that can generate high-quality bounding boxes and labels from free-form text, while Segment Anything is an advanced segmentation model that can generate masks for all objects in an image. This project adds the ability to prompt multiple masks and combine them, as well as to subtract negative masks for fine-grained control. Model inputs and outputs grounded_sam takes an image, a positive mask prompt, a negative mask prompt, and an adjustment factor as inputs. It then generates a set of masks that match the provided prompts. The positive prompt is used to identify the objects or regions of interest, while the negative prompt is used to exclude certain areas from the mask. The adjustment factor can be used to dilate or erode the masks. Inputs Image**: The input image to be masked. Mask Prompt**: The text prompt used to identify the objects or regions of interest. Negative Mask Prompt**: The text prompt used to exclude certain areas from the mask. Adjustment Factor**: An integer value that can be used to dilate (+) or erode (-) the generated masks. Outputs Masks**: An array of image URIs representing the generated masks. Capabilities grounded_sam is a powerful tool for programmed inpainting and selective masking. It can be used to precisely target and mask specific objects or regions in an image based on text prompts, while also excluding unwanted areas. This makes it useful for tasks like image editing, content creation, and data annotation. What can I use it for? grounded_sam can be used for a variety of applications, such as: Image Editing**: Precisely mask and modify specific elements in an image, such as removing objects, replacing backgrounds, or adjusting the appearance of specific regions. Content Creation**: Generate custom masks for use in digital art, compositing, or other creative projects. Data Annotation**: Automate the process of annotating images for tasks like object detection, instance segmentation, and more. Things to try One interesting thing to try with grounded_sam is using it to create masks for programmed inpainting. By combining the positive and negative prompts, you can precisely target the areas you want to keep or remove, and then use the adjustment factor to fine-tune the masks as needed. This can be a powerful tool for tasks like object removal, image restoration, or content-aware fill.
Updated Invalid Date
🗣️
grounding-dino-base
46
The grounding-dino-base model, developed by IDEA-Research, is an extension of the closed-set object detection model DINO (Detecting Objects with Noisy Guidance). Grounding DINO adds a text encoder, enabling the model to perform open-set object detection - the ability to detect objects in an image without any labeled data. This model achieves impressive results, such as 52.5 AP on the COCO zero-shot dataset, as detailed in the original paper. Similar models include the GroundingDINO and grounding-dino models, which also focus on zero-shot object detection, as well as the dino-vitb16 and dinov2-base models, which use self-supervised training approaches like DINO and DINOv2 on Vision Transformers. Model inputs and outputs Inputs Images**: The model takes in an image for which it will perform zero-shot object detection. Text**: The model also takes in a text prompt that specifies the objects to detect in the image, such as "a cat. a remote control." Outputs Bounding boxes**: The model outputs bounding boxes around the detected objects in the image, along with corresponding confidence scores. Object labels**: The model also outputs the object labels that correspond to the detected bounding boxes. Capabilities The grounding-dino-base model excels at zero-shot object detection, which means it can detect objects in images without any labeled training data. This is achieved by the model's ability to ground the text prompt to the visual features in the image. The model can detect a wide variety of objects, from common household items to more obscure objects. What can I use it for? You can use the grounding-dino-base model for a variety of applications that require open-set object detection, such as robotic assistants, autonomous vehicles, and image analysis tools. By providing a simple text prompt, the model can quickly identify and localize objects in an image without the need for labeled training data. Things to try One interesting thing to try with the grounding-dino-base model is to experiment with different text prompts. The model's performance can be influenced by the specific wording and phrasing of the prompt, so you can explore how to craft prompts that elicit the desired object detection results. Additionally, you can try combining the model with other computer vision techniques, such as image segmentation or instance recognition, to create more advanced applications.
Updated Invalid Date