img-and-audio2video
Maintainer: lucataco

7

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | No paper link provided |
Create account to get full access
Model overview
The img-and-audio2video model is a custom AI model that allows you to combine an image and an audio file to create a video clip. This model, created by the maintainer lucataco, is packaged as a Cog model, which makes it easy to run as a standard container.
This model is similar to other models like ms-img2vid, video-crafter, and vid2densepose, all of which are also created by lucataco and focused on generating or manipulating video content.
Model inputs and outputs
The img-and-audio2video model takes two inputs: an image file and an audio file. The image file is expected to be in a grayscale format, while the audio file can be in any standard format. The model then generates a video clip that combines the image and audio.
Inputs
- Image: A grayscale input image
- Audio: An audio file
Outputs
- Output: A generated video clip
Capabilities
The img-and-audio2video model can be used to create unique and creative video content by combining an image and audio file. This could be useful for applications such as music videos, animated shorts, or creative social media content.
What can I use it for?
The img-and-audio2video model could be used by content creators, artists, or businesses to generate custom video content for a variety of purposes. For example, a musician could use the model to create a music video for a new song by providing an image and the audio file. A social media influencer could use the model to create engaging, visually-interesting content to share with their followers.
Things to try
One interesting thing to try with the img-and-audio2video model is to experiment with different types of images and audio files to see how the model combines them. You could try using abstract or surreal images, or pairing the audio with unexpected visuals. You could also try adjusting the prompts to see how they affect the output.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

ms-img2vid
1.3K
The ms-img2vid model, created by Replicate user lucataco, is a powerful AI tool that can transform any image into a video. This model is an implementation of the fffilono/ms-image2video (aka camenduru/damo-image-to-video) model, packaged as a Cog model for easy deployment and use. Similar models created by lucataco include vid2densepose, which converts videos to DensePose, vid2openpose, which generates OpenPose from videos, magic-animate, a model for human image animation, and realvisxl-v1-img2img, an implementation of the SDXL RealVisXL_V1.0 img2img model. Model inputs and outputs The ms-img2vid model takes a single input - an image - and generates a video as output. The input image can be in any standard format, and the output video will be in a standard video format. Inputs Image**: The input image that will be transformed into a video. Outputs Video**: The output video generated from the input image. Capabilities The ms-img2vid model can transform any image into a dynamic, animated video. This can be useful for creating video content from static images, such as for social media posts, presentations, or artistic projects. What can I use it for? The ms-img2vid model can be used in a variety of creative and practical applications. For example, you could use it to generate animated videos from your personal photos, create dynamic presentations, or even produce short films or animations from a single image. Additionally, the model's capabilities could be leveraged by businesses or content creators to enhance their visual content and engage their audience more effectively. Things to try One interesting thing to try with the ms-img2vid model is experimenting with different types of input images, such as abstract art, landscapes, or portraits. Observe how the model translates the visual elements of the image into the resulting video, and how the animation and movement can bring new life to the original image.
Updated Invalid Date

video-crafter
16
video-crafter is an open diffusion model for high-quality video generation developed by lucataco. It is similar to other diffusion-based text-to-image models like stable-diffusion but with the added capability of generating videos from text prompts. video-crafter can produce cinematic videos with dynamic scenes and movement, such as an astronaut running away from a dust storm on the moon. Model inputs and outputs video-crafter takes in a text prompt that describes the desired video and outputs a GIF file containing the generated video. The model allows users to customize various parameters like the frame rate, video dimensions, and number of steps in the diffusion process. Inputs Prompt**: The text description of the video to generate Fps**: The frames per second of the output video Seed**: The random seed to use for generation (leave blank to randomize) Steps**: The number of steps to take in the video generation process Width**: The width of the output video Height**: The height of the output video Outputs Output**: A GIF file containing the generated video Capabilities video-crafter is capable of generating highly realistic and dynamic videos from text prompts. It can produce a wide range of scenes and scenarios, from fantastical to everyday, with impressive visual quality and smooth movement. The model's versatility is evident in its ability to create videos across diverse genres, from cinematic sci-fi to slice-of-life vignettes. What can I use it for? video-crafter could be useful for a variety of applications, such as creating visual assets for films, games, or marketing campaigns. Its ability to generate unique video content from simple text prompts makes it a powerful tool for content creators and animators. Additionally, the model could be leveraged for educational or research purposes, allowing users to explore the intersection of language, visuals, and motion. Things to try One interesting aspect of video-crafter is its capacity to capture dynamic, cinematic scenes. Users could experiment with prompts that evoke a sense of movement, action, or emotional resonance, such as "a lone explorer navigating a lush, alien landscape" or "a family gathered around a crackling fireplace on a snowy evening." The model's versatility also lends itself to more abstract or surreal prompts, allowing users to push the boundaries of what is possible in the realm of generative video.
Updated Invalid Date

resemble-enhance
9
The resemble-enhance model is an AI-driven audio enhancement tool powered by Resemble AI. It aims to improve the overall quality of speech by performing denoising and enhancement. The model consists of two modules: a denoiser that separates speech from noisy audio, and an enhancer that further boosts the perceptual audio quality by restoring distortions and extending the audio bandwidth. The models are trained on high-quality 44.1kHz speech data to ensure the enhancement of speech with high quality. Model inputs and outputs The resemble-enhance model takes an input audio file and several configurable parameters to control the enhancement process. The output is an enhanced version of the input audio file. Inputs input_audio**: Input audio file solver**: Solver to use (default is Midpoint) denoise_flag**: Flag to denoise the audio (default is false) prior_temperature**: CFM Prior temperature to use (default is 0.5) number_function_evaluations**: CFM Number of function evaluations to use (default is 64) Outputs Output**: Enhanced audio file(s) Capabilities The resemble-enhance model can improve the overall quality of speech by removing noise and enhancing the audio. It can be used to enhance audio recordings with background noise, such as street noise or music, as well as improve the quality of archived speech recordings. What can I use it for? The resemble-enhance model can be used in a variety of applications where high-quality audio is required, such as podcasting, voice-over work, or video production. It can also be used to enhance the audio quality of remote meetings or video calls, or to improve the listening experience for people with hearing impairments. Additionally, the model can be used to enhance the audio quality of archived recordings, such as old interviews or lectures. Things to try One interesting thing to try with the resemble-enhance model is to experiment with the different configuration parameters, such as the solver, the prior temperature, and the number of function evaluations. By adjusting these parameters, you can fine-tune the enhancement process to achieve the best results for your specific use case.
Updated Invalid Date
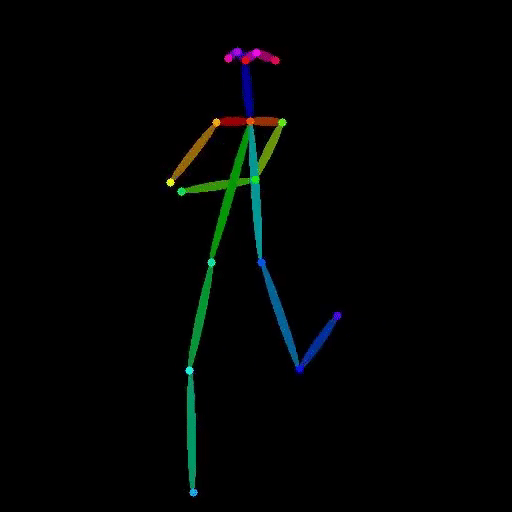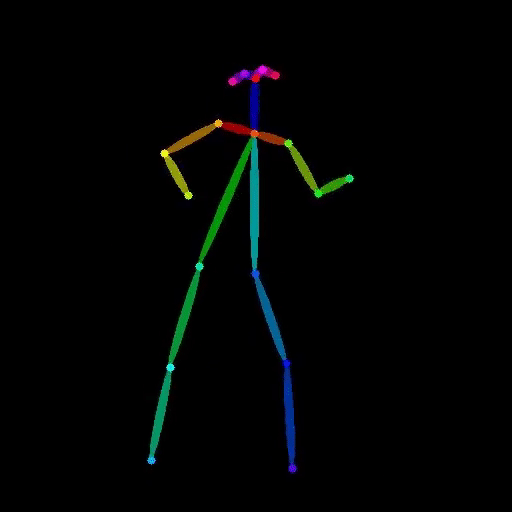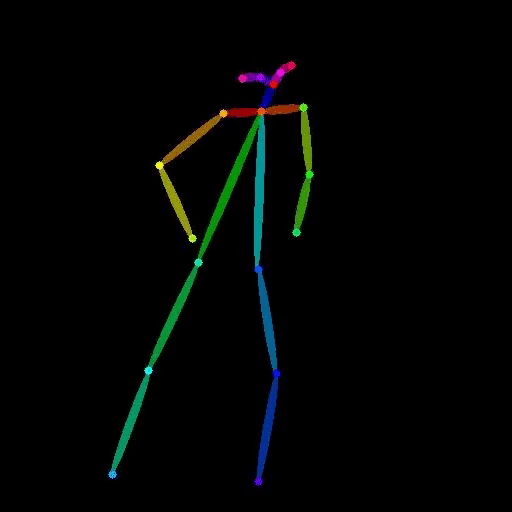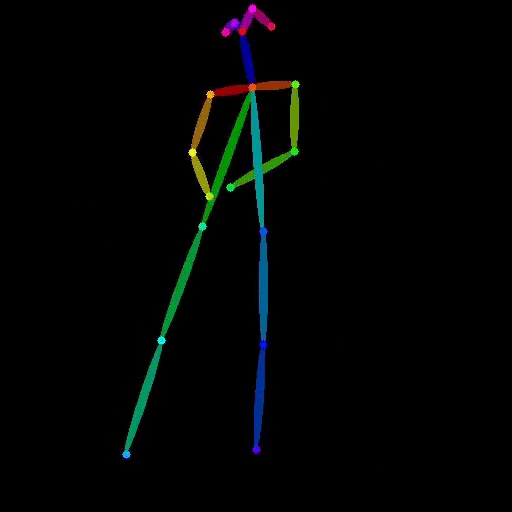
vid2openpose
1
vid2openpose is a Cog model developed by lucataco that can take a video as input and generate an output video with OpenPose-style skeletal pose estimation overlaid on the original frames. This model is similar to other AI models like DeepSeek-VL, open-dalle-v1.1, and ProteusV0.1 created by lucataco, which focus on various computer vision and language understanding capabilities. Model inputs and outputs The vid2openpose model takes a single input of a video file. The output is a new video file with the OpenPose-style skeletal pose estimation overlaid on the original frames. Inputs Video**: The input video file to be processed. Outputs Output Video**: The resulting video with the OpenPose-style skeletal pose estimation overlaid. Capabilities The vid2openpose model is capable of taking an input video and generating a new video with real-time skeletal pose estimation using the OpenPose algorithm. This can be useful for a variety of applications, such as motion capture, animation, and human pose analysis. What can I use it for? The vid2openpose model can be used for a variety of applications, such as: Motion capture**: The skeletal pose estimation can be used to capture the motion of actors or athletes for use in animation or video games. Human pose analysis**: The skeletal pose estimation can be used to analyze the movements and posture of people in various situations, such as fitness or rehabilitation. Animation**: The skeletal pose estimation can be used as a starting point for animating characters in videos or films. Things to try One interesting thing to try with the vid2openpose model is to use it to analyze the movements of athletes or dancers, and then use that data to create new animations or visualizations. Another idea is to use the model to create interactive experiences where users can control a virtual character by moving in front of a camera.
Updated Invalid Date