vid2densepose
Maintainer: lucataco

4

| Property | Value |
|---|---|
| Model Link | View on Replicate |
| API Spec | View on Replicate |
| Github Link | View on Github |
| Paper Link | No paper link provided |
Create account to get full access
Model overview
The vid2densepose model is a powerful tool designed for applying the DensePose model to videos, generating detailed "Part Index" visualizations for each frame. This tool is particularly useful for enhancing animations, especially when used in conjunction with MagicAnimate, a model for temporally consistent human image animation. The vid2densepose model was created by lucataco, a developer known for creating various AI-powered video processing tools.
Model inputs and outputs
The vid2densepose model takes a video as input and outputs a new video file with the DensePose information overlaid in a vivid, color-coded format. This output can then be used as input to other models, such as MagicAnimate, to create advanced human animation projects.
Inputs
- Input Video: The input video file that you want to process with the DensePose model.
Outputs
- Output Video: The processed video file with the DensePose information overlaid in a color-coded format.
Capabilities
The vid2densepose model can take a video input and generate a new video output that displays detailed "Part Index" visualizations for each frame. This information can be used to enhance animations, create novel visual effects, or provide a rich dataset for further computer vision research.
What can I use it for?
The vid2densepose model is particularly useful for creators and animators who want to incorporate detailed human pose information into their projects. By using the output of vid2densepose as input to MagicAnimate, you can create temporally consistent and visually stunning human animations. Additionally, the DensePose data could be used for various computer vision tasks, such as human motion analysis, body part segmentation, or virtual clothing applications.
Things to try
One interesting thing to try with the vid2densepose model is to combine it with other video processing tools, such as Real-ESRGAN Video Upscaler or AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation. By stacking these models together, you can create highly detailed and visually compelling animated sequences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
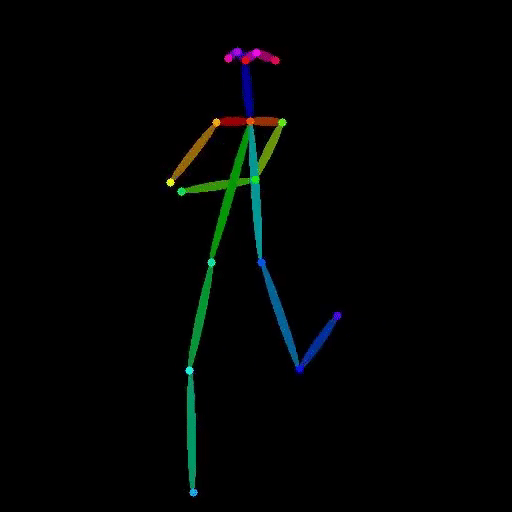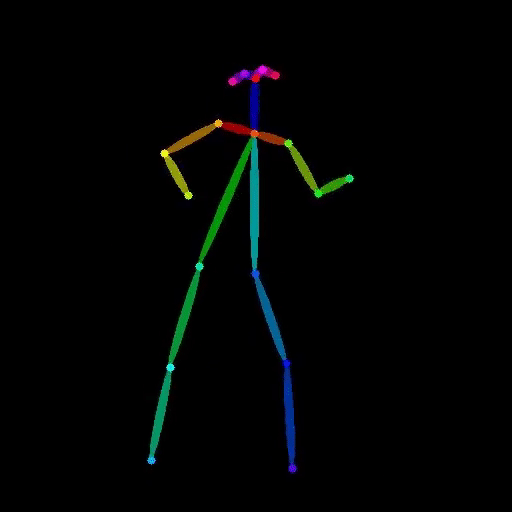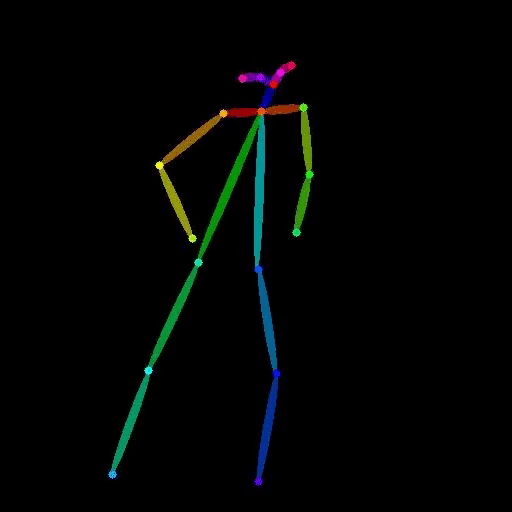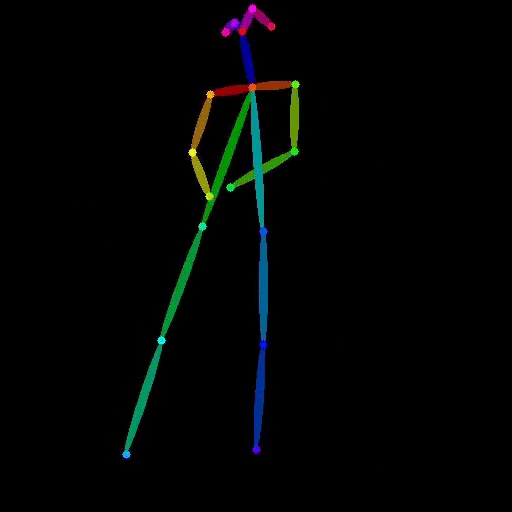
vid2openpose
1
vid2openpose is a Cog model developed by lucataco that can take a video as input and generate an output video with OpenPose-style skeletal pose estimation overlaid on the original frames. This model is similar to other AI models like DeepSeek-VL, open-dalle-v1.1, and ProteusV0.1 created by lucataco, which focus on various computer vision and language understanding capabilities. Model inputs and outputs The vid2openpose model takes a single input of a video file. The output is a new video file with the OpenPose-style skeletal pose estimation overlaid on the original frames. Inputs Video**: The input video file to be processed. Outputs Output Video**: The resulting video with the OpenPose-style skeletal pose estimation overlaid. Capabilities The vid2openpose model is capable of taking an input video and generating a new video with real-time skeletal pose estimation using the OpenPose algorithm. This can be useful for a variety of applications, such as motion capture, animation, and human pose analysis. What can I use it for? The vid2openpose model can be used for a variety of applications, such as: Motion capture**: The skeletal pose estimation can be used to capture the motion of actors or athletes for use in animation or video games. Human pose analysis**: The skeletal pose estimation can be used to analyze the movements and posture of people in various situations, such as fitness or rehabilitation. Animation**: The skeletal pose estimation can be used as a starting point for animating characters in videos or films. Things to try One interesting thing to try with the vid2openpose model is to use it to analyze the movements of athletes or dancers, and then use that data to create new animations or visualizations. Another idea is to use the model to create interactive experiences where users can control a virtual character by moving in front of a camera.
Updated Invalid Date

magic-animate-openpose
8
The magic-animate-openpose model is an implementation of the magic-animate model that uses OpenPose input instead of DensePose. Developed by Luca Taco, this model allows you to animate human figures in images using an input video. It is similar to other models like vid2openpose, vid2densepose, and the original magic-animate model. Model inputs and outputs The magic-animate-openpose model takes in an image and a video as inputs. The image is the base image that will be animated, and the video provides the motion information to drive the animation. The model outputs an animated version of the input image. Inputs Image**: The input image to be animated Video**: The motion video that will drive the animation Outputs Animated Image**: The input image with the motion from the video applied to it Capabilities The magic-animate-openpose model can take an image of a human figure and animate it using the motion from an input video. This allows you to create dynamic, animated versions of static images. The model uses OpenPose to extract the pose information from the input video, which it then applies to the target image. What can I use it for? You can use the magic-animate-openpose model to create fun and engaging animated content. This could be useful for social media, video production, or even creative projects. By combining a static image with motion from a video, you can bring characters and figures to life in new and interesting ways. Things to try One interesting thing to try with the magic-animate-openpose model is to use it in combination with other models like real-esrgan-video to upscale and enhance the quality of the animated output. You could also experiment with using different types of input videos to see how the animation is affected, or try animating various types of figures beyond just humans.
Updated Invalid Date

magic-animate
48
magic-animate is a AI model for temporally consistent human image animation, developed by Replicate creator lucataco. It builds upon the magic-research / magic-animate project, which uses a diffusion model to animate human images in a consistent manner over time. This model can be compared to other human animation models like vid2openpose, AnimateDiff-Lightning, Champ, and AnimateLCM developed by Replicate creators like lucataco and camenduru. Model inputs and outputs The magic-animate model takes two inputs: an image and a video. The image is the static input frame that will be animated, and the video provides the motion guidance. The model outputs an animated video of the input image. Inputs Image**: The static input image to be animated Video**: The motion video that provides the guidance for animating the input image Outputs Animated Video**: The output video of the input image animated based on the provided motion guidance Capabilities The magic-animate model can take a static image of a person and animate it in a temporally consistent way using a reference video of human motion. This allows for creating seamless and natural-looking animations from a single input image. What can I use it for? The magic-animate model can be useful for various applications where you need to animate human images, such as in video production, virtual avatars, or augmented reality experiences. By providing a simple image and a motion reference, you can quickly generate animated content without the need for complex 3D modeling or animation tools. Things to try One interesting thing to try with magic-animate is to experiment with different types of input videos to see how they affect the final animation. You could try using videos of different human activities, such as dancing, walking, or gesturing, and observe how the model translates the motion to the static image. Additionally, you could try using abstract or stylized motion videos to see how the model handles more unconventional input.
Updated Invalid Date

ms-img2vid
1.3K
The ms-img2vid model, created by Replicate user lucataco, is a powerful AI tool that can transform any image into a video. This model is an implementation of the fffilono/ms-image2video (aka camenduru/damo-image-to-video) model, packaged as a Cog model for easy deployment and use. Similar models created by lucataco include vid2densepose, which converts videos to DensePose, vid2openpose, which generates OpenPose from videos, magic-animate, a model for human image animation, and realvisxl-v1-img2img, an implementation of the SDXL RealVisXL_V1.0 img2img model. Model inputs and outputs The ms-img2vid model takes a single input - an image - and generates a video as output. The input image can be in any standard format, and the output video will be in a standard video format. Inputs Image**: The input image that will be transformed into a video. Outputs Video**: The output video generated from the input image. Capabilities The ms-img2vid model can transform any image into a dynamic, animated video. This can be useful for creating video content from static images, such as for social media posts, presentations, or artistic projects. What can I use it for? The ms-img2vid model can be used in a variety of creative and practical applications. For example, you could use it to generate animated videos from your personal photos, create dynamic presentations, or even produce short films or animations from a single image. Additionally, the model's capabilities could be leveraged by businesses or content creators to enhance their visual content and engage their audience more effectively. Things to try One interesting thing to try with the ms-img2vid model is experimenting with different types of input images, such as abstract art, landscapes, or portraits. Observe how the model translates the visual elements of the image into the resulting video, and how the animation and movement can bring new life to the original image.
Updated Invalid Date