omni-zero
Maintainer: okaris

458
| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | No paper link provided |
Create account to get full access
Model overview
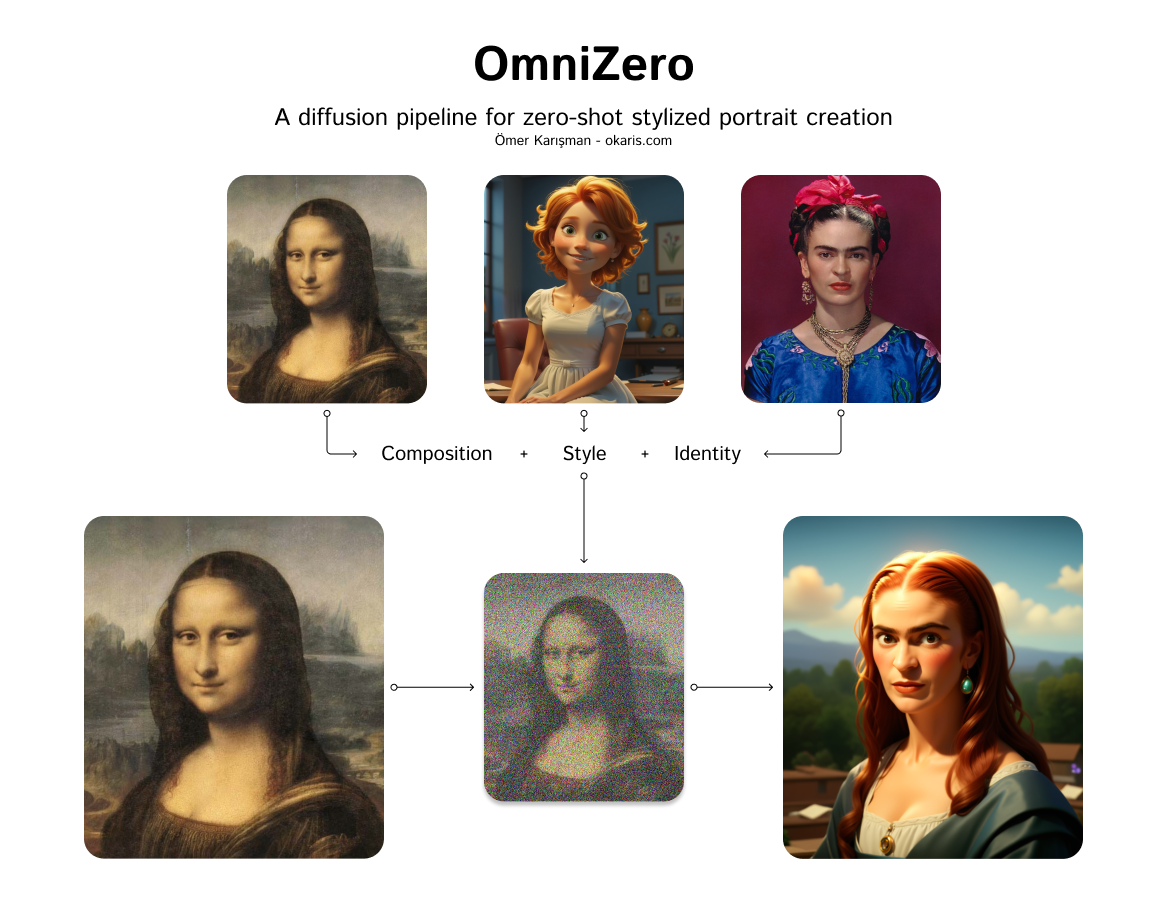
Omni-Zero is a diffusion pipeline model created by okaris that enables zero-shot stylized portrait creation. It leverages the power of diffusion models, similar to Stable Diffusion, to generate photo-realistic images from text prompts. However, Omni-Zero adds the ability to apply various styles and effects to the generated portraits, allowing for a high degree of customization and creativity.
Model inputs and outputs
Omni-Zero takes in a variety of inputs that allow for fine-tuned control over the generated portraits. These include a text prompt, a seed value for reproducibility, a guidance scale, and the number of steps and images to generate. Users can also provide optional input images, such as a base image, style image, identity image, and composition image, to further influence the output.
Inputs
- Seed: A random seed value for reproducibility
- Prompt: The text prompt describing the desired portrait
- Negative Prompt: Optional text to exclude from the generated image
- Number of Images: The number of images to generate
- Number of Steps: The number of steps to use in the diffusion process
- Guidance Scale: The strength of the text guidance during the diffusion process
- Base Image: An optional base image to use as a starting point
- Style Image: An optional image to use as a style reference
- Identity Image: An optional image to use as an identity reference
- Composition Image: An optional image to use as a composition reference
- Depth Image: An optional depth image to use for depth-aware generation
Outputs
- An array of generated portrait images in the form of image URLs
Capabilities
Omni-Zero excels at generating highly stylized and personalized portraits from text prompts. It can capture a wide range of artistic styles, from photorealistic to more abstract and impressionistic renderings. The model's ability to incorporate various input images, such as style and identity references, allows for a high degree of customization and creative expression.
What can I use it for?
Omni-Zero can be a powerful tool for artists, designers, and content creators who want to quickly generate unique and visually striking portrait images. It could be used to create custom avatars, character designs, or even personalized art pieces. The model's versatility also makes it suitable for various applications, such as social media content, illustrations, and even product design.
Things to try
One interesting aspect of Omni-Zero is its ability to blend multiple styles and identities in a single generated portrait. By providing a diverse set of input images, users can explore the interplay of different visual elements and create truly unique and captivating portraits. Additionally, experimenting with the depth image and composition inputs can lead to some fascinating depth-aware and spatially-aware generations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

text2video-zero-openjourney
13
The text2video-zero-openjourney model, developed by Picsart AI Research, is a groundbreaking AI model that enables zero-shot video generation using text prompts. It leverages the power of existing text-to-image synthesis methods, such as Stable Diffusion, and adapts them for the video domain. This innovative approach allows users to generate dynamic, temporally consistent videos directly from textual descriptions, without the need for additional training on video data. Model inputs and outputs The text2video-zero-openjourney model takes in a text prompt as input and generates a video as output. The model can also be conditioned on additional inputs, such as poses or edges, to guide the video generation process. Inputs Prompt**: A textual description of the desired video content, such as "A panda is playing guitar on Times Square". Pose Guidance**: An optional input in the form of a video containing poses that can be used to guide the video generation. Edge Guidance**: An optional input in the form of a video containing edge information that can be used to guide the video generation. Dreambooth Specialization**: An optional input in the form of a Dreambooth-trained model, which can be used to generate videos with a specific style or character. Outputs Video**: The generated video, which follows the provided textual prompt and any additional guidance inputs. Capabilities The text2video-zero-openjourney model is capable of generating a wide variety of dynamic video content, ranging from animals performing actions to fantastical scenes with anthropomorphized characters. For example, the model can generate videos of "A horse galloping on a street", "An astronaut dancing in outer space", or "A panda surfing on a wakeboard". What can I use it for? The text2video-zero-openjourney model opens up exciting possibilities for content creation and storytelling. Creators and artists can use this model to quickly generate unique video content for various applications, such as social media, animation, and filmmaking. Businesses can leverage the model to create dynamic, personalized video advertisements or product demonstrations. Educators and researchers can explore the model's capabilities for educational content and data visualization. Things to try One interesting aspect of the text2video-zero-openjourney model is its ability to incorporate additional guidance inputs, such as poses and edges. By providing these inputs, users can further influence the generated videos and achieve specific visual styles or narratives. For example, users can generate videos of "An alien dancing under a flying saucer" by providing a video of dancing poses as guidance. Another fascinating capability of the model is its integration with Dreambooth specialization. By fine-tuning the model with a Dreambooth-trained model, users can generate videos with a distinct visual style or character, such as "A GTA-5 man" or "An Arcane-style character".
Updated Invalid Date

zero-shot-image-to-text
6
The zero-shot-image-to-text model is a cutting-edge AI model designed for the task of generating text descriptions from input images. Developed by researcher yoadtew, this model leverages a unique "zero-shot" approach to enable image-to-text generation without the need for task-specific fine-tuning. This sets it apart from similar models like stable-diffusion, uform-gen, and turbo-enigma which often require extensive fine-tuning for specific image-to-text tasks. Model inputs and outputs The zero-shot-image-to-text model takes in an image and produces a text description of that image. The model can handle a wide range of image types and subjects, from natural scenes to abstract concepts. Additionally, the model supports "visual-semantic arithmetic" - the ability to perform arithmetic operations on visual concepts to generate new images. Inputs Image**: The input image to be described Outputs Text Description**: A textual description of the input image Capabilities The zero-shot-image-to-text model has demonstrated impressive capabilities in generating detailed and coherent image descriptions across a diverse set of visual inputs. It can handle not only common objects and scenes, but also more complex visual reasoning tasks like understanding visual relationships and analogies. What can I use it for? The zero-shot-image-to-text model can be a valuable tool for a variety of applications, such as: Automated Image Captioning**: Generating descriptive captions for large image datasets, which can be useful for tasks like visual search, content moderation, and accessibility. Visual Question Answering**: Answering questions about the contents of an image, which can be helpful for building intelligent assistants or educational applications. Visual-Semantic Arithmetic**: Exploring and manipulating visual concepts in novel ways, which can inspire new creative applications or research directions. Things to try One interesting aspect of the zero-shot-image-to-text model is its ability to handle "visual-semantic arithmetic" - the ability to combine visual concepts in arithmetic-like operations to generate new, semantically meaningful images. For example, the model can take in images of a "woman", a "king", and a "man", and then generate a new image that represents the visual concept of "woman - king + man". This opens up fascinating possibilities for exploring the relationships between visual and semantic representations.
Updated Invalid Date

text2video-zero
2
text2video-zero is a novel AI model developed by researchers at Picsart AI Research that leverages the power of existing text-to-image synthesis methods, like Stable Diffusion, to generate high-quality video content from text prompts. Unlike previous video generation models that relied on complex frameworks, text2video-zero can produce temporally consistent videos in a zero-shot manner, without the need for any video-specific training. The model also supports various conditional inputs, such as poses, edges, and Dreambooth specialization, to further guide the video generation process. Model inputs and outputs text2video-zero takes a textual prompt as input and generates a video as output. The model can also leverage additional inputs like poses, edges, and Dreambooth specialization to provide more fine-grained control over the generated videos. Inputs Prompt**: A textual description of the desired video content. Pose/Edge guidance**: Optional input video that provides pose or edge information to guide the video generation. Dreambooth specialization**: Optional input that specifies a Dreambooth model to apply specialized visual styles to the generated video. Outputs Video**: The generated video that matches the input prompt and any additional guidance provided. Capabilities text2video-zero can generate a wide range of video content, from simple scenes like "a cat running on the grass" to more complex and dynamic ones like "an astronaut dancing in outer space." The model is capable of producing temporally consistent videos that closely follow the provided textual prompts and guidance. What can I use it for? text2video-zero can be used to create a variety of video content for various applications, such as: Content creation**: Generate unique and customized video content for social media, marketing, or entertainment purposes. Prototyping and storyboarding**: Quickly generate video previews to explore ideas and concepts before investing in more costly production. Educational and informational videos**: Generate explanatory or instructional videos on a wide range of topics. Video editing and manipulation**: Use the model's conditional inputs to edit or manipulate existing video footage. Things to try Some interesting things to try with text2video-zero include: Experiment with different textual prompts to see the range of video content the model can generate. Explore the use of pose, edge, and Dreambooth guidance to refine and personalize the generated videos. Try using the model's low-memory setup to generate videos on hardware with limited GPU memory. Integrate text2video-zero into your own projects or workflows to enhance your video creation capabilities.
Updated Invalid Date

sdxl-lightning-4step
417.0K
sdxl-lightning-4step is a fast text-to-image model developed by ByteDance that can generate high-quality images in just 4 steps. It is similar to other fast diffusion models like AnimateDiff-Lightning and Instant-ID MultiControlNet, which also aim to speed up the image generation process. Unlike the original Stable Diffusion model, these fast models sacrifice some flexibility and control to achieve faster generation times. Model inputs and outputs The sdxl-lightning-4step model takes in a text prompt and various parameters to control the output image, such as the width, height, number of images, and guidance scale. The model can output up to 4 images at a time, with a recommended image size of 1024x1024 or 1280x1280 pixels. Inputs Prompt**: The text prompt describing the desired image Negative prompt**: A prompt that describes what the model should not generate Width**: The width of the output image Height**: The height of the output image Num outputs**: The number of images to generate (up to 4) Scheduler**: The algorithm used to sample the latent space Guidance scale**: The scale for classifier-free guidance, which controls the trade-off between fidelity to the prompt and sample diversity Num inference steps**: The number of denoising steps, with 4 recommended for best results Seed**: A random seed to control the output image Outputs Image(s)**: One or more images generated based on the input prompt and parameters Capabilities The sdxl-lightning-4step model is capable of generating a wide variety of images based on text prompts, from realistic scenes to imaginative and creative compositions. The model's 4-step generation process allows it to produce high-quality results quickly, making it suitable for applications that require fast image generation. What can I use it for? The sdxl-lightning-4step model could be useful for applications that need to generate images in real-time, such as video game asset generation, interactive storytelling, or augmented reality experiences. Businesses could also use the model to quickly generate product visualization, marketing imagery, or custom artwork based on client prompts. Creatives may find the model helpful for ideation, concept development, or rapid prototyping. Things to try One interesting thing to try with the sdxl-lightning-4step model is to experiment with the guidance scale parameter. By adjusting the guidance scale, you can control the balance between fidelity to the prompt and diversity of the output. Lower guidance scales may result in more unexpected and imaginative images, while higher scales will produce outputs that are closer to the specified prompt.
Updated Invalid Date