tango
Maintainer: declare-lab

21

| Property | Value |
|---|---|
| Run this model | Run on Replicate |
| API spec | View on Replicate |
| Github link | View on Github |
| Paper link | View on Arxiv |
Create account to get full access
Model overview
Tango is a latent diffusion model (LDM) for text-to-audio (TTA) generation, capable of generating realistic audios including human sounds, animal sounds, natural and artificial sounds, and sound effects from textual prompts. It uses the frozen instruction-tuned language model Flan-T5 as the text encoder and trains a UNet-based diffusion model for audio generation. Compared to current state-of-the-art TTA models, Tango performs comparably across both objective and subjective metrics, despite training on a dataset 63 times smaller. The maintainer has released the model, training, and inference code for the research community.
Tango 2 is a follow-up to Tango, built upon the same foundation but with additional alignment training using Direct Preference Optimization (DPO) on the Audio-alpaca dataset, a pairwise text-to-audio preference dataset. This helps Tango 2 generate higher-quality and more aligned audio outputs.
Model inputs and outputs
Inputs
- Prompt: A textual description of the desired audio to be generated.
- Steps: The number of steps to use for the diffusion-based audio generation process, with more steps typically producing higher-quality results at the cost of longer inference time.
- Guidance: The guidance scale, which controls the trade-off between sample quality and sample diversity during the audio generation process.
Outputs
- Audio: The generated audio clip corresponding to the input prompt, in WAV format.
Capabilities
Tango and Tango 2 can generate a wide variety of realistic audio clips, including human sounds, animal sounds, natural and artificial sounds, and sound effects. For example, they can generate sounds of an audience cheering and clapping, rolling thunder with lightning strikes, or a car engine revving.
What can I use it for?
The Tango and Tango 2 models can be used for a variety of applications, such as:
- Audio content creation: Generating audio clips for videos, games, podcasts, and other multimedia projects.
- Sound design: Creating custom sound effects for various applications.
- Music composition: Generating musical elements or accompaniment for songwriting and composition.
- Accessibility: Generating audio descriptions for visually impaired users.
Things to try
You can try generating various types of audio clips by providing different prompts to the Tango and Tango 2 models, such as:
- Everyday sounds (e.g., a dog barking, water flowing, a car engine revving)
- Natural phenomena (e.g., thunderstorms, wind, rain)
- Musical instruments and soundscapes (e.g., a piano playing, a symphony orchestra)
- Human vocalizations (e.g., laughter, cheering, singing)
- Ambient and abstract sounds (e.g., a futuristic machine, alien landscapes)
Experiment with the number of steps and guidance scale to find the right balance between sample quality and generation time for your specific use case.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models

mustango
289
Mustango is an exciting addition to the world of Multimodal Large Language Models designed for controlled music generation. Developed by the declare-lab team, Mustango leverages Latent Diffusion Model (LDM), Flan-T5, and musical features to generate music from text prompts. It builds upon the work of similar models like MusicGen and MusicGen Remixer, but with a focus on more fine-grained control and improved overall music quality. Model inputs and outputs Mustango takes in a text prompt describing the desired music and generates an audio file in response. The model can be used to create a wide range of musical styles, from ambient to pop, by crafting the right prompts. Inputs Prompt**: A text description of the desired music, including details about the instrumentation, genre, tempo, and mood. Outputs Audio file**: A generated audio file containing the music based on the input prompt. Capabilities Mustango demonstrates impressive capabilities in generating music that closely matches the provided text prompt. The model is able to capture details like instrumentation, rhythm, and mood, and translate them into coherent musical compositions. Compared to earlier text-to-music models, Mustango shows significant improvements in terms of overall musical quality and coherence. What can I use it for? Mustango opens up a world of possibilities for content creators, musicians, and hobbyists alike. The model can be used to generate custom background music for videos, podcasts, or video games. Composers could leverage Mustango to quickly prototype musical ideas or explore new creative directions. Advertisers and marketers may find the model useful for generating jingles or soundtracks for their campaigns. Things to try One interesting aspect of Mustango is its ability to generate music in a variety of styles based on the input prompt. Try experimenting with different genres, moods, and levels of detail in your prompts to see the diverse range of musical compositions the model can produce. Additionally, the team has released several pre-trained models, including a Mustango Pretrained version, which may be worth exploring for specific use cases.
Updated Invalid Date

styletts2
4.2K
styletts2 is a text-to-speech (TTS) model developed by Yinghao Aaron Li, Cong Han, Vinay S. Raghavan, Gavin Mischler, and Nima Mesgarani. It leverages style diffusion and adversarial training with large speech language models (SLMs) to achieve human-level TTS synthesis. Unlike its predecessor, styletts2 models styles as a latent random variable through diffusion models, allowing it to generate the most suitable style for the text without requiring reference speech. It also employs large pre-trained SLMs, such as WavLM, as discriminators with a novel differentiable duration modeling for end-to-end training, resulting in improved speech naturalness. Model inputs and outputs styletts2 takes in text and generates high-quality speech audio. The model inputs and outputs are as follows: Inputs Text**: The text to be converted to speech. Beta**: A parameter that determines the prosody of the generated speech, with lower values sampling style based on previous or reference speech and higher values sampling more from the text. Alpha**: A parameter that determines the timbre of the generated speech, with lower values sampling style based on previous or reference speech and higher values sampling more from the text. Reference**: An optional reference speech audio to copy the style from. Diffusion Steps**: The number of diffusion steps to use in the generation process, with higher values resulting in better quality but longer generation time. Embedding Scale**: A scaling factor for the text embedding, which can be used to produce more pronounced emotion in the generated speech. Outputs Audio**: The generated speech audio in the form of a URI. Capabilities styletts2 is capable of generating human-level TTS synthesis on both single-speaker and multi-speaker datasets. It surpasses human recordings on the LJSpeech dataset and matches human performance on the VCTK dataset. When trained on the LibriTTS dataset, styletts2 also outperforms previous publicly available models for zero-shot speaker adaptation. What can I use it for? styletts2 can be used for a variety of applications that require high-quality text-to-speech generation, such as audiobook production, voice assistants, language learning tools, and more. The ability to control the prosody and timbre of the generated speech, as well as the option to use reference audio, makes styletts2 a versatile tool for creating personalized and expressive speech output. Things to try One interesting aspect of styletts2 is its ability to perform zero-shot speaker adaptation on the LibriTTS dataset. This means that the model can generate speech in the style of speakers it has not been explicitly trained on, by leveraging the diverse speech synthesis offered by the diffusion model. Developers could explore the limits of this zero-shot adaptation and experiment with fine-tuning the model on new speakers to further improve the quality and diversity of the generated speech.
Updated Invalid Date
audio-ldm
36
audio-ldm is a text-to-audio generation model created by Haohe Liu, a researcher at CVSSP. It uses latent diffusion models to generate audio based on text prompts. The model is similar to stable-diffusion, a widely-used latent text-to-image diffusion model, but applied to the audio domain. It is also related to models like riffusion, which generates music from text, and whisperx, which transcribes audio. However, audio-ldm is focused specifically on generating a wide range of audio content from text. Model inputs and outputs The audio-ldm model takes in a text prompt as input and generates an audio clip as output. The text prompt can describe the desired sound, such as "a hammer hitting a wooden surface" or "children singing". The model then produces an audio clip that matches the text prompt. Inputs Text**: A text prompt describing the desired audio to generate. Duration**: The duration of the generated audio clip in seconds. Higher durations may lead to out-of-memory errors. Random Seed**: An optional random seed to control the randomness of the generation. N Candidates**: The number of candidate audio clips to generate, with the best one selected. Guidance Scale**: A parameter that controls the balance between audio quality and diversity. Higher values lead to better quality but less diversity. Outputs Audio Clip**: The generated audio clip that matches the input text prompt. Capabilities audio-ldm is capable of generating a wide variety of audio content from text prompts, including speech, sound effects, music, and beyond. It can also perform audio-to-audio generation, where it generates a new audio clip that has similar sound events to a provided input audio. Additionally, the model supports text-guided audio-to-audio style transfer, where it can transfer the sound of an input audio clip to match a text description. What can I use it for? audio-ldm could be useful for various applications, such as: Creative content generation**: Generating audio content for use in videos, games, or other multimedia projects. Audio post-production**: Automating the creation of sound effects or music to complement visual content. Accessibility**: Generating audio descriptions for visually impaired users. Education and research**: Exploring the capabilities of text-to-audio generation models. Things to try When using audio-ldm, try providing more detailed and descriptive text prompts to get better quality results. Experiment with different random seeds to see how they affect the generation. You can also try combining audio-ldm with other audio tools and techniques, such as audio editing or signal processing, to create even more interesting and compelling audio content.
Updated Invalid Date
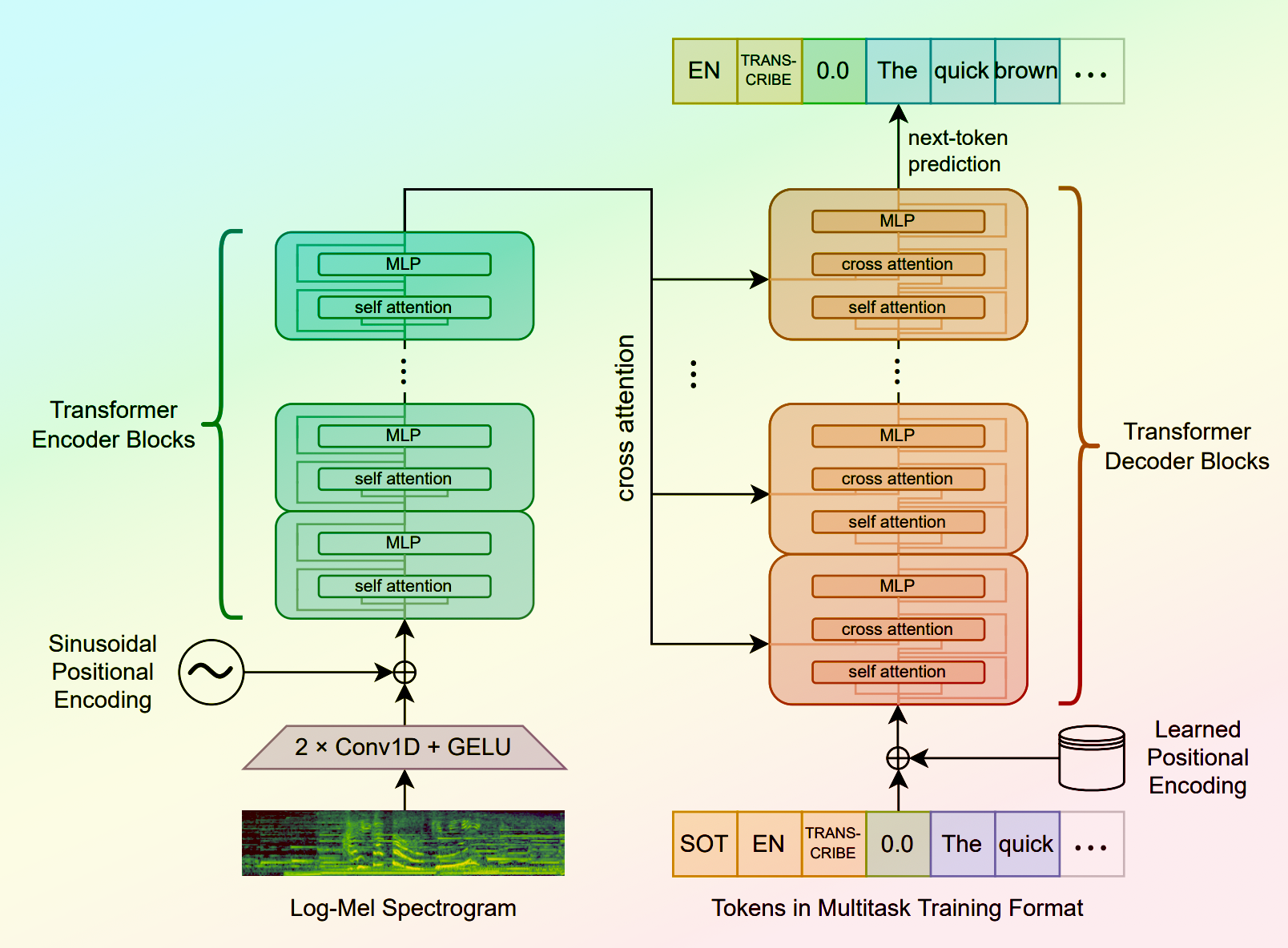
whisper
31.0K
Whisper is a general-purpose speech recognition model developed by OpenAI. It is capable of converting speech in audio to text, with the ability to translate the text to English if desired. Whisper is based on a large Transformer model trained on a diverse dataset of multilingual and multitask speech recognition data. This allows the model to handle a wide range of accents, background noises, and languages. Similar models like whisper-large-v3, incredibly-fast-whisper, and whisper-diarization offer various optimizations and additional features built on top of the core Whisper model. Model inputs and outputs Whisper takes an audio file as input and outputs a text transcription. The model can also translate the transcription to English if desired. The input audio can be in various formats, and the model supports a range of parameters to fine-tune the transcription, such as temperature, patience, and language. Inputs Audio**: The audio file to be transcribed Model**: The specific version of the Whisper model to use, currently only large-v3 is supported Language**: The language spoken in the audio, or None to perform language detection Translate**: A boolean flag to translate the transcription to English Transcription**: The format for the transcription output, such as "plain text" Initial Prompt**: An optional initial text prompt to provide to the model Suppress Tokens**: A list of token IDs to suppress during sampling Logprob Threshold**: The minimum average log probability threshold for a successful transcription No Speech Threshold**: The threshold for considering a segment as silence Condition on Previous Text**: Whether to provide the previous output as a prompt for the next window Compression Ratio Threshold**: The maximum compression ratio threshold for a successful transcription Temperature Increment on Fallback**: The temperature increase when the decoding fails to meet the specified thresholds Outputs Transcription**: The text transcription of the input audio Language**: The detected language of the audio (if language input is None) Tokens**: The token IDs corresponding to the transcription Timestamp**: The start and end timestamps for each word in the transcription Confidence**: The confidence score for each word in the transcription Capabilities Whisper is a powerful speech recognition model that can handle a wide range of accents, background noises, and languages. The model is capable of accurately transcribing audio and optionally translating the transcription to English. This makes Whisper useful for a variety of applications, such as real-time captioning, meeting transcription, and audio-to-text conversion. What can I use it for? Whisper can be used in various applications that require speech-to-text conversion, such as: Captioning and Subtitling**: Automatically generate captions or subtitles for videos, improving accessibility for viewers. Meeting Transcription**: Transcribe audio recordings of meetings, interviews, or conferences for easy review and sharing. Podcast Transcription**: Convert audio podcasts to text, making the content more searchable and accessible. Language Translation**: Transcribe audio in one language and translate the text to another, enabling cross-language communication. Voice Interfaces**: Integrate Whisper into voice-controlled applications, such as virtual assistants or smart home devices. Things to try One interesting aspect of Whisper is its ability to handle a wide range of languages and accents. You can experiment with the model's performance on audio samples in different languages or with various background noises to see how it handles different real-world scenarios. Additionally, you can explore the impact of the different input parameters, such as temperature, patience, and language detection, on the transcription quality and accuracy.
Updated Invalid Date