yolox
Maintainer: daanelson

16

| Property | Value |
|---|---|
| Model Link | View on Replicate |
| API Spec | View on Replicate |
| Github Link | View on Github |
| Paper Link | View on Arxiv |
Create account to get full access
Model overview
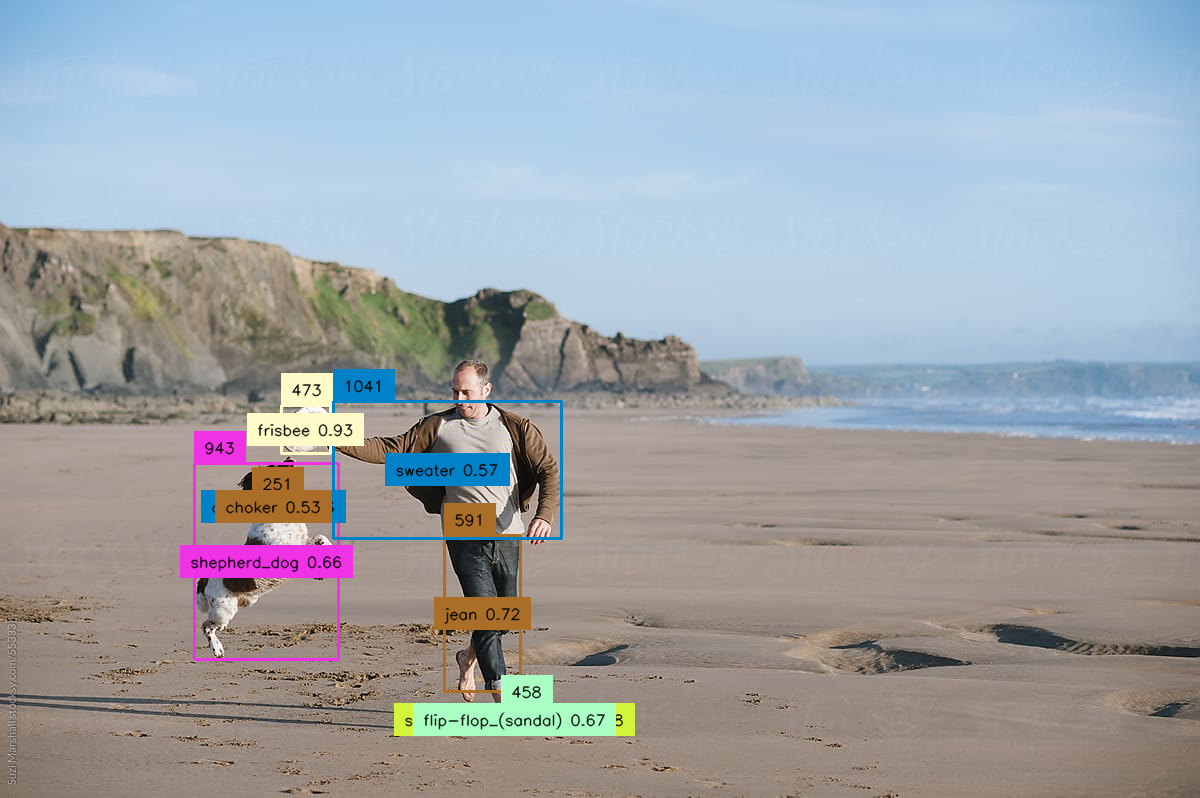
The yolox model is a high-performance and lightweight object detection model developed by Megvii-BaseDetection. It is an anchor-free version of YOLO (You Only Look Once), with a simpler design but better performance. According to the maintainer daanelson, the goal of yolox is to bridge the gap between research and industrial communities.
The yolox model is available in several different sizes, including yolox-s, yolox-m, yolox-l, and yolox-x, which offer a trade-off between performance and model size. For example, the yolox-s model achieves 40.5 mAP on the COCO dataset, while the larger yolox-x model achieves 51.5 mAP but has more parameters and FLOPS.
Other similar object detection models include yolos-tiny and yolo-world. These models take different approaches to object detection, such as using Vision Transformers (yolos-tiny) or focusing on real-time open-vocabulary detection (yolo-world).
Model inputs and outputs
Inputs
- input_image: The path to an image file that the model will perform object detection on.
- model_name: The name of the
yoloxmodel to use, such asyolox-s,yolox-m,yolox-l, oryolox-x. - conf: The confidence threshold for object detections. Only detections with confidence higher than this value will be kept.
- nms: The non-maximum suppression (NMS) threshold. NMS removes redundant detections, and detections with overlap percentage (IOU) above this threshold are considered redundant.
- tsize: The size that the input image will be resized to before being fed into the model.
Outputs
- img: The input image with the detected objects and bounding boxes drawn on it.
- json_str: The object detection results in JSON format, including the bounding boxes, labels, and confidence scores for each detected object.
Capabilities
The yolox model is capable of performing real-time object detection on images. It can detect a wide range of objects, such as people, vehicles, animals, and more. The model's accuracy and speed can be tuned by selecting the appropriate model size, with the larger yolox-x model offering the best performance but requiring more compute resources.
What can I use it for?
The yolox model can be used in a variety of computer vision applications, such as:
- Surveillance and security: The real-time object detection capabilities of
yoloxcan be used to monitor and track objects in surveillance footage. - Autonomous vehicles:
yoloxcan be used for object detection and obstacle avoidance in self-driving car applications. - Robotics: The model can be used to enable robots to perceive and interact with their environment.
- Retail and logistics:
yoloxcan be used for inventory management, shelf monitoring, and package tracking.
Things to try
One interesting aspect of the yolox model is its anchor-free design, which simplifies the object detection architecture compared to traditional YOLO models. This can make the model easier to understand and potentially faster to train and deploy.
Another thing to explore is the different model sizes provided, which offer a trade-off between performance and model complexity. Experimenting with the various yolox models can help you find the right balance for your specific use case.
Additionally, the yolox model supports a variety of deployment options, including MegEngine, ONNX, TensorRT, ncnn, and OpenVINO. Trying out different deployment scenarios can help you optimize the model's performance for your target hardware and application.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Models
yolo-world
2
yolo-world is a cutting-edge real-time open-vocabulary object detector developed by Tencent AI Lab, ARC Lab, and Huazhong University of Science and Technology. It enhances the well-known YOLO series of detectors by incorporating vision-language modeling and pre-training on large-scale datasets, allowing it to detect a wide range of objects in a zero-shot manner with high efficiency. This sets it apart from similar models like instant-id, which focuses on realistic image generation, and llava-13b, which is a large language and vision model. Model inputs and outputs yolo-world takes in an image or video as input and outputs bounding boxes and class labels for the detected objects. The model is designed to work with a wide range of object categories, going beyond the predefined classes found in traditional object detectors. Inputs Input media**: Path to the input image or video Class names**: Comma-separated list of object classes to be detected Outputs JSON string**: The detection results in JSON format Media path**: The path to the input media with the detection results visualized Capabilities yolo-world is capable of real-time open-vocabulary object detection, allowing users to detect a wide range of objects without being limited to a predefined set of categories. This makes it a versatile tool for a variety of applications, such as autonomous vehicles, surveillance systems, and image analysis. What can I use it for? The open-vocabulary detection capabilities of yolo-world make it a powerful tool for developers and researchers working on a wide range of computer vision tasks. For example, it could be used in autonomous vehicles to detect and track a diverse set of objects on the road, or in surveillance systems to monitor a broad range of activities and events. Additionally, the model could be leveraged for image analysis and content understanding tasks, such as visual search or image captioning. Things to try One interesting aspect of yolo-world is its "prompt-then-detect" paradigm, which allows users to specify the object categories they want to detect at inference time. This provides a level of flexibility and customization that is not found in traditional object detectors. You could try experimenting with different sets of object categories to see how the model performs on various detection tasks. Additionally, the model's ability to detect objects in a zero-shot manner is quite impressive. You could try testing the model's performance on novel object categories that were not included in the pre-training data to see how it generalizes.
Updated Invalid Date

sdxl-lightning-4step
166.0K
sdxl-lightning-4step is a fast text-to-image model developed by ByteDance that can generate high-quality images in just 4 steps. It is similar to other fast diffusion models like AnimateDiff-Lightning and Instant-ID MultiControlNet, which also aim to speed up the image generation process. Unlike the original Stable Diffusion model, these fast models sacrifice some flexibility and control to achieve faster generation times. Model inputs and outputs The sdxl-lightning-4step model takes in a text prompt and various parameters to control the output image, such as the width, height, number of images, and guidance scale. The model can output up to 4 images at a time, with a recommended image size of 1024x1024 or 1280x1280 pixels. Inputs Prompt**: The text prompt describing the desired image Negative prompt**: A prompt that describes what the model should not generate Width**: The width of the output image Height**: The height of the output image Num outputs**: The number of images to generate (up to 4) Scheduler**: The algorithm used to sample the latent space Guidance scale**: The scale for classifier-free guidance, which controls the trade-off between fidelity to the prompt and sample diversity Num inference steps**: The number of denoising steps, with 4 recommended for best results Seed**: A random seed to control the output image Outputs Image(s)**: One or more images generated based on the input prompt and parameters Capabilities The sdxl-lightning-4step model is capable of generating a wide variety of images based on text prompts, from realistic scenes to imaginative and creative compositions. The model's 4-step generation process allows it to produce high-quality results quickly, making it suitable for applications that require fast image generation. What can I use it for? The sdxl-lightning-4step model could be useful for applications that need to generate images in real-time, such as video game asset generation, interactive storytelling, or augmented reality experiences. Businesses could also use the model to quickly generate product visualization, marketing imagery, or custom artwork based on client prompts. Creatives may find the model helpful for ideation, concept development, or rapid prototyping. Things to try One interesting thing to try with the sdxl-lightning-4step model is to experiment with the guidance scale parameter. By adjusting the guidance scale, you can control the balance between fidelity to the prompt and diversity of the output. Lower guidance scales may result in more unexpected and imaginative images, while higher scales will produce outputs that are closer to the specified prompt.
Updated Invalid Date

real-esrgan-a100
10.2K
real-esrgan-a100 is an image upscaling model developed by daanelson that aims to provide practical algorithms for general image restoration. It extends the powerful ESRGAN model to a practical restoration application, trained with pure synthetic data. The model performs well on a variety of images, including general scenes and anime-style artwork. It can be compared to similar models like real-esrgan and real-esrgan-xxl-images, which also offer advanced image upscaling capabilities. Model inputs and outputs real-esrgan-a100 takes a low-resolution image as input and outputs a high-resolution version of the same image. The model is optimized to handle a wide range of image types, including standard photos, illustrations, and anime-style artwork. Inputs Image**: The low-resolution input image to be upscaled. Scale**: The factor by which the image should be scaled up, from 0 to 10. The default is 4x. Face Enhance**: An optional flag to run GFPGAN face enhancement along with the upscaling. Outputs Output Image**: The high-resolution version of the input image, upscaled by the specified factor and optionally with face enhancement applied. Capabilities real-esrgan-a100 is capable of producing high-quality upscaled images with impressive detail and clarity. The model is particularly adept at preserving fine textures and details, making it well-suited for upscaling a variety of image types. It can handle both natural photographs and stylized artwork, producing impressive results in both cases. What can I use it for? real-esrgan-a100 can be used for a variety of image-related tasks, such as: Enhancing low-resolution images**: Upscale and sharpen low-quality images to create high-resolution versions suitable for printing, digital display, or further processing. Improving image quality for creative projects**: Use the model to upscale and enhance illustrations, concept art, and other types of digital artwork. Preparing images for online use**: Upscale images while preserving quality to create assets for websites, social media, and other digital platforms. Things to try When using real-esrgan-a100, you can experiment with different scale factors to find the optimal balance between image quality and file size. Additionally, the face enhancement feature can be a useful tool for improving the appearance of portraits and other images with prominent facial features.
Updated Invalid Date
codet
1
The codet model is an object detection AI model developed by Replicate and maintained by the creator adirik. It is designed to detect objects in images with high accuracy. The codet model shares similarities with other object detection models like Marigold, which focuses on monocular depth estimation, and StyleMC, MaSaCtrl-Anything-v4-0, and MaSaCtrl-Stable-Diffusion-v1-4, which are focused on text-guided image generation and editing. Model inputs and outputs The codet model takes an input image and a confidence threshold, and outputs an array of image URIs. The input image is used for object detection, and the confidence threshold is used to filter the detected objects based on their confidence scores. Inputs Image**: The input image to be processed for object detection. Confidence**: The confidence threshold to filter the detected objects. Show Visualisation**: An optional flag to display the detection results on the input image. Outputs Array of Image URIs**: The output of the model is an array of image URIs, where each URI represents a detected object in the input image. Capabilities The codet model is capable of detecting objects in images with high accuracy. It uses a novel approach called "Co-Occurrence Guided Region-Word Alignment" to improve the model's performance on open-vocabulary object detection tasks. What can I use it for? The codet model can be useful in a variety of applications, such as: Image analysis and understanding**: The model can be used to analyze and understand the contents of images, which can be valuable in fields like e-commerce, security, and robotics. Visual search and retrieval**: The model can be used to build visual search engines or image retrieval systems, where users can search for specific objects within a large collection of images. Augmented reality and computer vision**: The model can be integrated into AR/VR applications or computer vision systems to provide real-time object detection and identification. Things to try Some ideas for things to try with the codet model include: Experiment with different confidence thresholds to see how it affects the accuracy and number of detected objects. Use the model to analyze a variety of images and see how it performs on different types of objects. Integrate the model into a larger system, such as an image-processing pipeline or a computer vision application.
Updated Invalid Date