Daanelson
Models by this creator

real-esrgan-a100

10.2K
real-esrgan-a100 is an image upscaling model developed by daanelson that aims to provide practical algorithms for general image restoration. It extends the powerful ESRGAN model to a practical restoration application, trained with pure synthetic data. The model performs well on a variety of images, including general scenes and anime-style artwork. It can be compared to similar models like real-esrgan and real-esrgan-xxl-images, which also offer advanced image upscaling capabilities. Model inputs and outputs real-esrgan-a100 takes a low-resolution image as input and outputs a high-resolution version of the same image. The model is optimized to handle a wide range of image types, including standard photos, illustrations, and anime-style artwork. Inputs Image**: The low-resolution input image to be upscaled. Scale**: The factor by which the image should be scaled up, from 0 to 10. The default is 4x. Face Enhance**: An optional flag to run GFPGAN face enhancement along with the upscaling. Outputs Output Image**: The high-resolution version of the input image, upscaled by the specified factor and optionally with face enhancement applied. Capabilities real-esrgan-a100 is capable of producing high-quality upscaled images with impressive detail and clarity. The model is particularly adept at preserving fine textures and details, making it well-suited for upscaling a variety of image types. It can handle both natural photographs and stylized artwork, producing impressive results in both cases. What can I use it for? real-esrgan-a100 can be used for a variety of image-related tasks, such as: Enhancing low-resolution images**: Upscale and sharpen low-quality images to create high-resolution versions suitable for printing, digital display, or further processing. Improving image quality for creative projects**: Use the model to upscale and enhance illustrations, concept art, and other types of digital artwork. Preparing images for online use**: Upscale images while preserving quality to create assets for websites, social media, and other digital platforms. Things to try When using real-esrgan-a100, you can experiment with different scale factors to find the optimal balance between image quality and file size. Additionally, the face enhancement feature can be a useful tool for improving the appearance of portraits and other images with prominent facial features.
Updated 7/2/2024
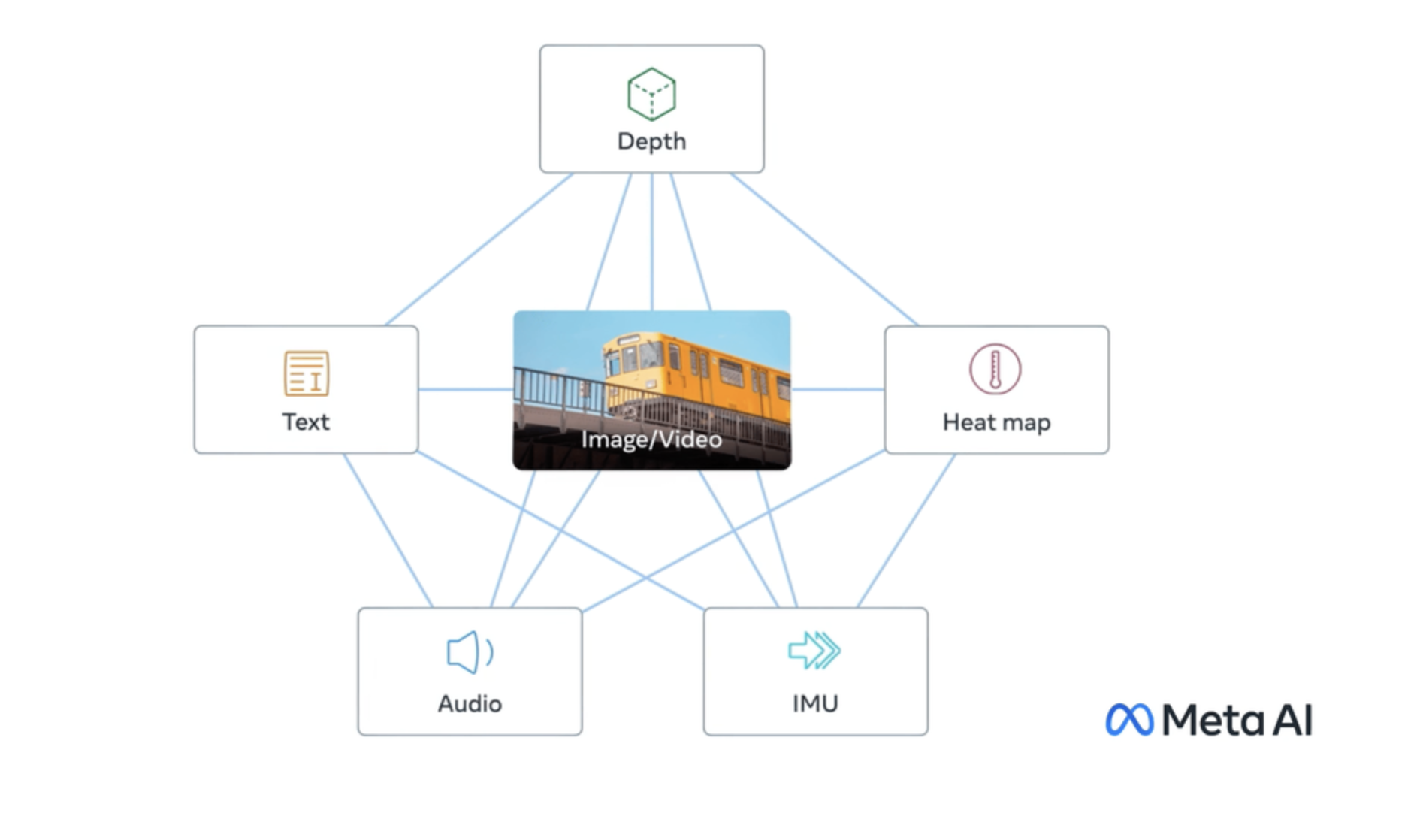
imagebind
2.0K
ImageBind is a model developed by researchers at FAIR, Meta AI that learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. This allows it to perform novel "emergent" applications like cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation. The model outperforms many existing single-modality models on zero-shot classification tasks across a range of datasets, demonstrating its ability to effectively represent and relate information from diverse inputs. Model inputs and outputs ImageBind takes in data from various modalities - text, images, audio, depth, thermal, and IMU sensors. The inputs are preprocessed and transformed before being fed into the model. The model then outputs a single, unified embedding that captures the semantic relationships between the different modalities. Inputs Text**: Text input in the form of a string Vision**: Image data in the form of image file paths Audio**: Audio data in the form of audio file paths Outputs Embedding**: A high-dimensional vector representing the input data in a shared embedding space Capabilities ImageBind demonstrates impressive zero-shot classification performance on a range of datasets, including ImageNet, Kinetics-400, NYU-D, ESC, and LLVIP. This indicates that the model is able to effectively represent and relate information from diverse inputs, and can generalize to new tasks and datasets without extensive fine-tuning. What can I use it for? The cross-modal capabilities of ImageBind enable novel applications like cross-modal retrieval, where you can search for images using text queries or vice versa. The model can also be used to compose modalities with arithmetic, allowing you to generate new content by combining text, images, and audio in interesting ways. Additionally, ImageBind can be used for cross-modal detection and generation tasks, expanding the possibilities for multimodal AI systems. Things to try One interesting aspect of ImageBind is its ability to learn a shared embedding space across diverse modalities. This allows you to explore the relationships between different types of data, such as how textual descriptions relate to visual and audio representations of the same concepts. You could experiment with tasks like zero-shot classification, cross-modal retrieval, or even generating new content by combining modalities in novel ways.
Updated 7/2/2024

minigpt-4
1.3K
minigpt-4 is a model that generates text in response to an input image and prompt. It was developed by Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny at King Abdullah University of Science and Technology. minigpt-4 aligns a frozen visual encoder from BLIP-2 with a frozen large language model, Vicuna, using just one projection layer. This allows the model to understand images and generate coherent, user-friendly text in response. The model's capabilities are similar to those demonstrated in GPT-4, with the ability to perform a variety of vision-language tasks like image captioning, visual question answering, and story generation. It is a compact and efficient model that can run on a single A100 GPU, making it accessible for a wide range of users. Model inputs and outputs Inputs image**: The image to discuss, provided as a URL. prompt**: The text prompt to guide the model's generation. num_beams**: The number of beams to use for beam search decoding. max_length**: The maximum length of the prompt and output combined, in tokens. temperature**: The temperature for generating tokens, where lower values result in more predictable outputs. max_new_tokens**: The maximum number of new tokens to generate. repetition_penalty**: The penalty for repeated words in the generated text, where values greater than 1 discourage repetition. Outputs Output**: The text generated by the model in response to the input image and prompt. Capabilities minigpt-4 demonstrates a range of vision-language capabilities, including image captioning, visual question answering, and story generation. For example, when provided an image of a wild animal and the prompt "Describe what you see in the image", the model can generate a detailed description of the animal's features and behavior. Similarly, when given an image and a prompt asking to "Write a short story about this image", the model can produce a coherent, imaginative narrative. What can I use it for? minigpt-4 could be useful for a variety of applications that involve generating text based on visual input, such as: Automated image captioning for social media or e-commerce Visual question answering for educational or assistive applications Story generation for creative writing or game development Generating text-based descriptions of product images The model's compact size and efficient performance make it a potentially accessible option for developers and researchers looking to incorporate vision-language capabilities into their projects. Things to try One interesting aspect of minigpt-4 is its ability to generate text that is closely tied to the input image, rather than just producing generic responses. For example, if you provide an image of a cityscape and ask the model to "Describe what you see", it will generate a response that is specific to the details and features of that particular scene, rather than giving a generic description of a cityscape. You can also experiment with providing the model with more open-ended prompts, like "Write a short story inspired by this image" or "Discuss the emotions conveyed in this image". This can lead to more creative and imaginative outputs that go beyond simple descriptive tasks.
Updated 7/2/2024

whisperx
40
whisperx is a Cog implementation of the WhisperX library, which adds batch processing on top of the popular Whisper speech recognition model. This allows for very fast audio transcription compared to the original Whisper model. whisperx is developed and maintained by daanelson. Similar models include whisperx-victor-upmeet, which provides accelerated transcription, word-level timestamps, and diarization with the Whisper large-v3 model, and whisper-diarization-thomasmol, which offers fast audio transcription, speaker diarization, and word-level timestamps. Model inputs and outputs whisperx takes an audio file as input, along with optional parameters to control the batch size, whether to output only the transcribed text or include segment metadata, and whether to print out memory usage information for debugging purposes. Inputs audio**: The audio file to be transcribed batch_size**: The number of audio segments to process in parallel for faster transcription only_text**: A boolean flag to return only the transcribed text, without segment metadata align_output**: A boolean flag to generate word-level timestamps (currently only works for English) debug**: A boolean flag to print out memory usage information Outputs The transcribed text, optionally with segment-level metadata Capabilities whisperx builds on the strong speech recognition capabilities of the Whisper model, providing accelerated transcription through batch processing. This can be particularly useful for transcribing long audio files or processing multiple audio files in parallel. What can I use it for? whisperx can be used for a variety of applications that require fast and accurate speech-to-text transcription, such as podcast production, video captioning, or meeting minutes generation. The ability to process audio in batches and the option to output only the transcribed text can make the model well-suited for high-volume or real-time transcription scenarios. Things to try One interesting aspect of whisperx is the ability to generate word-level timestamps, which can be useful for applications like video editing or language learning. You can experiment with the align_output parameter to see how this feature performs on your audio files. Another thing to try is leveraging the batch processing capabilities of whisperx to transcribe multiple audio files in parallel, which can significantly reduce the overall processing time for large-scale transcription tasks.
Updated 7/2/2024

some-upscalers
21
The some-upscalers model is a collection of 4x ESRGAN upscalers, which are deep learning models designed to enhance the resolution and quality of images. These upscalers were pulled from the Upscale.wiki Model Database and implemented using Cog, a platform for deploying machine learning models as APIs. The model was created by daanelson, who has also developed other AI models like real-esrgan-a100 and real-esrgan-video. Model inputs and outputs The some-upscalers model takes an input image and an optional choice of the specific upscaler model to use. The available models include 4x_UniversalUpscalerV2-Neutral_115000_swaG, which is the default. The model outputs an upscaled version of the input image. Inputs image**: The input image to be upscaled, provided as a URI. model_name**: The specific upscaler model to use for the upscaling, with the default being 4x_UniversalUpscalerV2-Neutral_115000_swaG. Outputs Output**: The upscaled version of the input image, provided as a URI. Capabilities The some-upscalers model can effectively enhance the resolution and quality of input images by a factor of 4x. It can be used to improve the visual clarity and detail of various types of images, such as photographs, illustrations, and digital art. What can I use it for? The some-upscalers model can be useful for a variety of applications, such as: Enhancing the quality of low-resolution images for use in presentations, publications, or social media. Improving the visual clarity of images used in graphic design, web design, or video production. Upscaling and enhancing the resolution of historical or archival images for preservation and digital archiving purposes. Things to try Experiment with the different upscaler models available in the some-upscalers collection to see which one works best for your specific needs. Try upscaling images with varying levels of complexity, such as detailed landscapes, portraits, or digital art, to see how the model performs. You can also try combining the some-upscalers model with other image processing techniques, such as style transfer or color correction, to achieve unique and compelling visual effects.
Updated 7/2/2024

yolox
16
The yolox model is a high-performance and lightweight object detection model developed by Megvii-BaseDetection. It is an anchor-free version of YOLO (You Only Look Once), with a simpler design but better performance. According to the maintainer daanelson, the goal of yolox is to bridge the gap between research and industrial communities. The yolox model is available in several different sizes, including yolox-s, yolox-m, yolox-l, and yolox-x, which offer a trade-off between performance and model size. For example, the yolox-s model achieves 40.5 mAP on the COCO dataset, while the larger yolox-x model achieves 51.5 mAP but has more parameters and FLOPS. Other similar object detection models include yolos-tiny and yolo-world. These models take different approaches to object detection, such as using Vision Transformers (yolos-tiny) or focusing on real-time open-vocabulary detection (yolo-world). Model inputs and outputs Inputs input_image**: The path to an image file that the model will perform object detection on. model_name**: The name of the yolox model to use, such as yolox-s, yolox-m, yolox-l, or yolox-x. conf**: The confidence threshold for object detections. Only detections with confidence higher than this value will be kept. nms**: The non-maximum suppression (NMS) threshold. NMS removes redundant detections, and detections with overlap percentage (IOU) above this threshold are considered redundant. tsize**: The size that the input image will be resized to before being fed into the model. Outputs img**: The input image with the detected objects and bounding boxes drawn on it. json_str**: The object detection results in JSON format, including the bounding boxes, labels, and confidence scores for each detected object. Capabilities The yolox model is capable of performing real-time object detection on images. It can detect a wide range of objects, such as people, vehicles, animals, and more. The model's accuracy and speed can be tuned by selecting the appropriate model size, with the larger yolox-x model offering the best performance but requiring more compute resources. What can I use it for? The yolox model can be used in a variety of computer vision applications, such as: Surveillance and security**: The real-time object detection capabilities of yolox can be used to monitor and track objects in surveillance footage. Autonomous vehicles**: yolox can be used for object detection and obstacle avoidance in self-driving car applications. Robotics**: The model can be used to enable robots to perceive and interact with their environment. Retail and logistics**: yolox can be used for inventory management, shelf monitoring, and package tracking. Things to try One interesting aspect of the yolox model is its anchor-free design, which simplifies the object detection architecture compared to traditional YOLO models. This can make the model easier to understand and potentially faster to train and deploy. Another thing to explore is the different model sizes provided, which offer a trade-off between performance and model complexity. Experimenting with the various yolox models can help you find the right balance for your specific use case. Additionally, the yolox model supports a variety of deployment options, including MegEngine, ONNX, TensorRT, ncnn, and OpenVINO. Trying out different deployment scenarios can help you optimize the model's performance for your target hardware and application.
Updated 7/2/2024

motion_diffusion_model
14
motion_diffusion_model is a diffusion model developed by Replicate creator daanelson for generating human motion video from text prompts. It is an implementation of the paper "Human Motion Diffusion Model" and is designed to produce realistic human motion animations based on natural language descriptions. The model can be used to create animations of people performing various actions and activities, such as walking, picking up objects, or interacting with the environment. Similar models include stable-diffusion, a latent text-to-image diffusion model that can generate photorealistic images, stable-diffusion-animation, which can animate Stable Diffusion by interpolating between prompts, and animate-diff, which can animate personalized Stable Diffusion models without specific tuning. While these models focus on generating images and videos from text, motion_diffusion_model is specifically designed for generating human motion. Model inputs and outputs motion_diffusion_model takes a text prompt as input and generates a corresponding animation of human motion. The text prompt can describe various actions, activities, or scenes involving people, and the model will attempt to create a realistic animation depicting that motion. Inputs Prompt**: A natural language description of the desired human motion, such as "the person walked forward and is picking up his toolbox." Outputs Animation**: A video sequence of a 3D stick figure animation depicting the human motion described in the input prompt. SMPL parameters**: The model also outputs the SMPL parameters (joint rotations, root translations, and vertex locations) for each frame of the animation, which can be used to render the motion as a 3D mesh. Capabilities motion_diffusion_model is capable of generating a wide variety of human motions based on text descriptions, including walking, running, picking up objects, and interacting with the environment. The model produces realistic-looking animations that capture the nuances of human movement, such as the timing and coordination of different body parts. One key capability of the model is its ability to generate motion that is semantically consistent with the input prompt. For example, if the prompt describes a person picking up a toolbox, the generated animation will show the person bending down, grasping the toolbox, and lifting it up in a natural and believable way. What can I use it for? motion_diffusion_model can be used for a variety of applications that require generating realistic human motion, such as: Animation and visual effects**: The model can be used to create animations for films, TV shows, or video games, where realistic human motion is important for creating immersive and believable scenes. Virtual reality and augmented reality**: The model's ability to generate 3D human motion can be used to create interactive experiences in VR and AR applications, where users can interact with virtual characters and avatars. Robotics and human-machine interaction**: The model's understanding of human motion can be used to improve the way robots and other autonomous systems interact with and understand human behavior. Things to try One interesting thing to try with motion_diffusion_model is to experiment with different types of prompts and see how the model responds. For example, you could try generating motion for more abstract or imaginative prompts, such as "a person dancing with a robot" or "a person performing acrobatic stunts in the air." This can help you understand the model's capabilities and limitations in terms of the types of motion it can generate. Another interesting thing to try is to use the model's SMPL parameters to render the generated motion as a 3D mesh, rather than just a stick figure animation. This can allow you to create more visually compelling and realistic-looking animations that can be integrated into other applications or used for more advanced rendering and animation tasks.
Updated 7/2/2024

plug_and_play_image_translation
6
plug_and_play_image_translation is a model developed by daanelson that enables editing an image using features from diffusion models. It builds upon the capabilities of models like stable-diffusion and stable-diffusion-inpainting by allowing users to selectively apply diffusion features to an input image to achieve specific edits. Model inputs and outputs Inputs Input Image**: The image to edit. Generation Prompt**: A text prompt that can be used to generate an image instead of providing an input image. Translation Prompts**: A set of text prompts that will be used to guide the image translation process. Negative Prompt**: Text to control the level of deviation from the source image. Scale**: The unconditional guidance scale, which determines how much the model should deviate from the source image. Negative Prompt Alpha**: The strength of the negative prompt's effect, with lower values being stronger. Feature Injection Threshold**: The timestep at which to stop injecting the saved features into the translation diffusion process, controlling the level of structure preservation. Outputs A set of translated images, one for each of the provided translation prompts. Capabilities plug_and_play_image_translation allows users to selectively apply diffusion features from pre-trained models like stable-diffusion to an input image, enabling a range of editing capabilities. This can be used to make targeted changes to an image while preserving the overall structure and composition. What can I use it for? plug_and_play_image_translation can be used for a variety of image editing tasks, such as generating variations of an existing image, combining elements from different images, or making specific changes to an image while maintaining its overall appearance. The ability to control the level of structure preservation and deviation from the source image makes it a versatile tool for creative workflows. Things to try One interesting aspect of plug_and_play_image_translation is the ability to control the level of structure preservation through the feature_injection_threshold parameter. By adjusting this value, you can find a balance between preserving the original image's composition and introducing new elements from the diffusion features. Additionally, experimenting with different translation prompts and negative prompts can help you achieve a wide range of creative effects.
Updated 7/2/2024

stable-diffusion-speed-lab
3
stable-diffusion-speed-lab is an AI model developed by daanelson that accelerates the performance of the popular Stable Diffusion text-to-image generation model. Unlike the original Stable Diffusion model, stable-diffusion-speed-lab aims to generate images more quickly without sacrificing quality. This model can be particularly useful for projects or applications that require real-time image generation or processing. Model inputs and outputs stable-diffusion-speed-lab takes a text prompt as input and generates one or more corresponding images as output. The specific input parameters include the text prompt, a seed value for randomization, the number of images to generate, guidance scale for the model, and the number of inference steps to perform. The model outputs a list of image URLs representing the generated images. Inputs Prompt**: The text prompt describing the desired image Seed**: A random seed value to control the randomness of the generated images Scheduler**: The algorithm used to schedule the diffusion process Num Outputs**: The number of images to generate Guidance Scale**: The scale for classifier-free guidance Negative Prompt**: Text describing things the model should not include in the output Outputs Output**: A list of URLs representing the generated images Capabilities stable-diffusion-speed-lab shares many of the same capabilities as the original Stable Diffusion model, including the ability to generate a wide variety of photorealistic images from text prompts. However, the key difference is the focus on faster image generation, which can be particularly useful for applications that require real-time or near-real-time image processing. What can I use it for? stable-diffusion-speed-lab can be used for a variety of applications that require fast, high-quality image generation, such as interactive art installations, real-time virtual environments, or rapid prototyping of visual designs. The model could also be incorporated into applications that generate images on-the-fly, such as chatbots, game engines, or media production tools. Things to try One interesting aspect of stable-diffusion-speed-lab is the ability to fine-tune the model for specific use cases or domains. By adjusting the model's parameters, such as the number of inference steps or the guidance scale, users can potentially optimize the model's performance for their particular needs. Additionally, exploring different text prompts and combinations of input parameters can yield a wide range of creative and unexpected results.
Updated 7/2/2024

speedy-sdxl-test
2
speedy-sdxl-test is a text-to-image model created by daanelson that is intended to be faster than the original SDXL model. It shares similarities with other SDXL-based models like SDXL-Lightning by ByteDance, SDXL v1.0 by lucataco, and SDXL Custom Model by alexgenovese. However, the maintainer's focus with this model is on improving generation speed. Model Inputs and Outputs speedy-sdxl-test takes a text prompt as the main input, along with various optional parameters to control things like the image size, number of outputs, guidance scale, and more. The model then generates one or more images based on the provided prompt. Inputs Prompt**: The text prompt describing the desired image Negative Prompt**: An optional text prompt describing what should not be included in the image Width**: The desired width of the output image, in pixels Height**: The desired height of the output image, in pixels Num Outputs**: The number of images to generate (up to 4) Scheduler**: The algorithm used for the diffusion process Guidance Scale**: The scale for classifier-free guidance Num Inference Steps**: The number of denoising steps to perform Seed**: An optional random seed to use for reproducibility Outputs Output Images**: One or more generated images, returned as a list of image URLs Capabilities speedy-sdxl-test is capable of generating high-quality images from text prompts, similar to other SDXL-based models. The focus on speed improvements may make it a good choice when you need to generate images quickly, such as for prototyping or demos. What Can I Use It For? With speedy-sdxl-test, you can create a variety of visuals to support your projects or ideas, such as product mockups, illustrations, and more. The model's speed could be especially useful in scenarios where you need to generate images rapidly, like for social media content or design workflows. As with other text-to-image models, the results will depend on the quality and specificity of your prompts. Things to Try Try experimenting with different prompts and parameter settings to see how they affect the generated images. You could also compare the speed and quality of speedy-sdxl-test to other SDXL-based models to see how it performs. Additionally, you might explore ways to integrate the model into your existing workflows or applications to streamline your image generation processes.
Updated 7/2/2024