A 1024 RV-Cores Shared-L1 Cluster with High Bandwidth Memory Link for Low-Latency 6G-SDR

0

Sign in to get full access
Overview
- Presents a 1024 RISC-V core cluster with shared L1 cache and high-bandwidth memory link for low-latency 6G software-defined radio (6G-SDR)
- Aims to provide high compute power and low latency for 6G wireless applications
- Leverages a many-core architecture and high-bandwidth memory interface to achieve these goals
Plain English Explanation
This research paper describes a new computer architecture designed to power the next generation of wireless communication systems, known as 6G. The key idea is to create a many-core cluster of 1,024 energy-efficient RISC-V processor cores, all sharing a common high-speed L1 cache memory. This allows the system to provide massive parallel processing power for the complex signal processing tasks required in 6G software-defined radio (6G-SDR) applications.
To ensure low latency communication, the system also features a high-bandwidth memory interface that can rapidly move data between the processors and memory. This is crucial for 6G, which needs to support real-time, low-latency wireless services like remote surgery and autonomous vehicle control.
The researchers believe this architecture can deliver the massive computing power and low latency required for emerging 6G wireless applications.
Technical Explanation
The paper proposes a 1,024 RISC-V core cluster with a shared L1 cache architecture and a high-bandwidth memory interface to enable low-latency 6G-SDR. The key components include:
- 1,024 RISC-V Cores: The system features a massive array of 1,024 energy-efficient RISC-V processor cores, allowing for tremendous parallel processing power.
- Shared L1 Cache: All 1,024 cores share a common L1 cache, enabling fast data access and communication between the cores.
- High-Bandwidth Memory Interface: The system connects the processor cores to high-bandwidth memory via a dedicated interface, enabling rapid data movement required for low-latency 6G applications.
The researchers evaluate the proposed architecture through simulations and argue it can deliver the compute performance and low latency necessary for 6G-SDR use cases, outperforming alternative many-core designs.
Critical Analysis
The paper provides a compelling architectural design for powering 6G wireless applications, but some potential limitations and areas for further research are worth considering:
- Power Efficiency: While the RISC-V cores are energy-efficient, managing the power consumption of a 1,024 core system may still be challenging, especially for mobile/edge 6G deployments. Further power optimization techniques could be explored.
- Memory Scalability: The high-bandwidth memory interface is crucial, but as 6G data rates continue to increase, the memory system may need to scale even further to keep up with throughput requirements.
- Programming Model: Efficiently programming and managing a 1,024 core system with a shared cache is non-trivial. The paper does not delve into the software stack and programming model, which will be an important area for future research.
- Hardware Complexity: Building a 1,024 core cluster with a coherent shared cache is an engineering feat. The paper does not discuss the practical challenges of implementing such a complex hardware design.
Overall, the proposed architecture presents an innovative approach to powering 6G wireless systems, but additional research is needed to address potential scalability, efficiency, and programmability concerns.
Conclusion
This research paper outlines an ambitious 1,024 RISC-V core cluster design with a shared L1 cache and high-bandwidth memory interface to enable low-latency 6G software-defined radio. The massive parallel processing power, combined with the low-latency memory subsystem, aims to deliver the compute performance and real-time capabilities required for emerging 6G wireless applications like remote surgery and autonomous vehicles. While the design shows promise, further research is needed to address potential challenges around power efficiency, memory scalability, programming model, and hardware complexity. Overall, this work represents an important step towards realizing the compute infrastructure needed to support the next generation of wireless communication technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A 1024 RV-Cores Shared-L1 Cluster with High Bandwidth Memory Link for Low-Latency 6G-SDR
Yichao Zhang, Marco Bertuletti, Chi Zhang, Samuel Riedel, Alessandro Vanelli-Coralli, Luca Benini
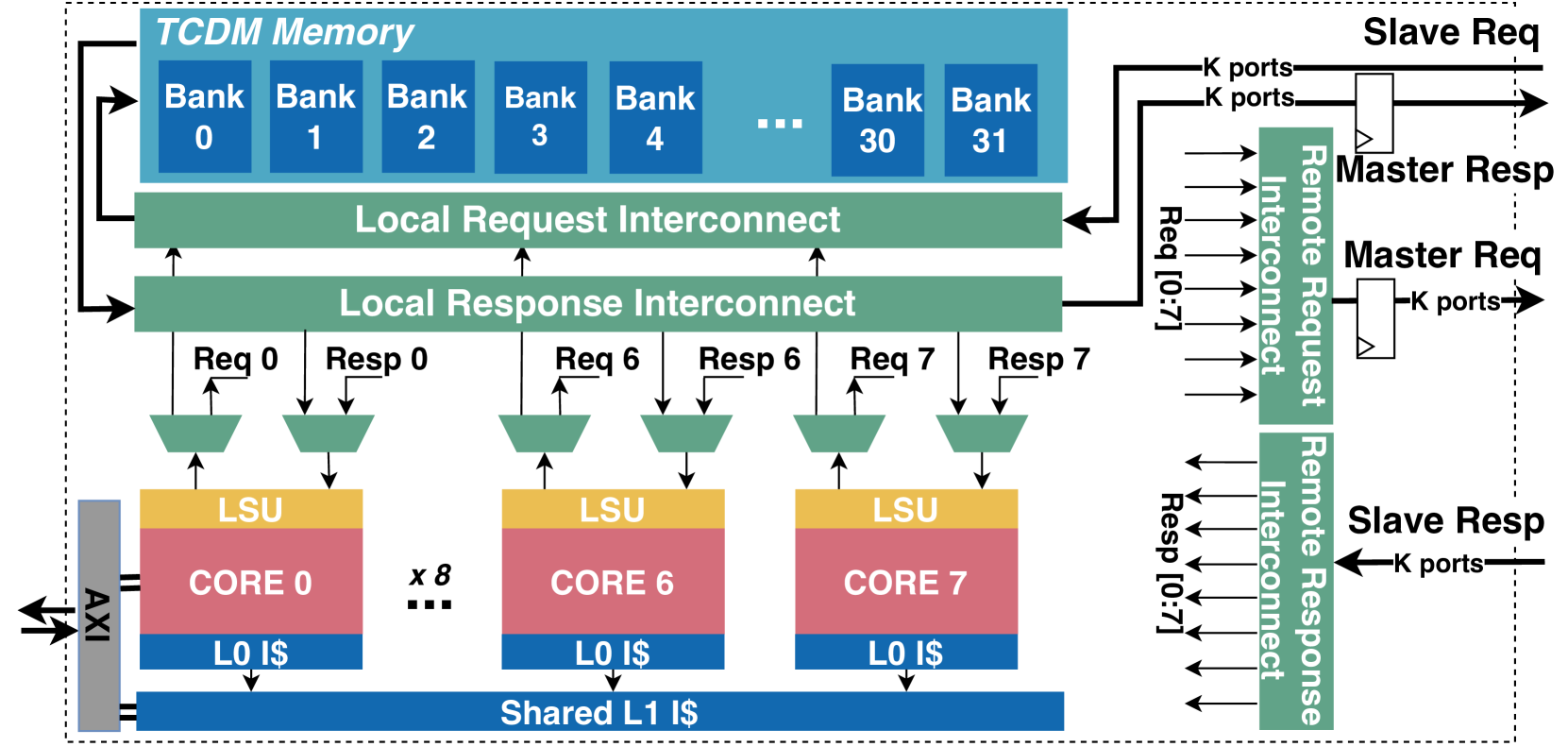
We introduce an open-source architecture for next-generation Radio-Access Network baseband processing: 1024 latency-tolerant 32-bit RISC-V cores share 4 MiB of L1 memory via an ultra-low latency interconnect (7-11 cycles), a modular Direct Memory Access engine provides an efficient link to a high bandwidth memory, such as HBM2E (98% peak bandwidth at 910GBps). The system achieves leading-edge energy efficiency at sub-ms latency in key 6G baseband processing kernels: Fast Fourier Transform (93 GOPS/W), Beamforming (125 GOPS/W), Channel Estimation (96 GOPS/W), and Linear System Inversion (61 GOPS/W), with only 9% data movement overhead.
Read more8/20/2024
0
TeraPool-SDR: An 1.89TOPS 1024 RV-Cores 4MiB Shared-L1 Cluster for Next-Generation Open-Source Software-Defined Radios
Yichao Zhang, Marco Bertuletti, Samuel Riedel, Matheus Cavalcante, Alessandro Vanelli-Coralli, Luca Benini
Radio Access Networks (RAN) workloads are rapidly scaling up in data processing intensity and throughput as the 5G (and beyond) standards grow in number of antennas and sub-carriers. Offering flexible Processing Elements (PEs), efficient memory access, and a productive parallel programming model, many-core clusters are a well-matched architecture for next-generation software-defined RANs, but staggering performance requirements demand a high number of PEs coupled with extreme Power, Performance and Area (PPA) efficiency. We present the architecture, design, and full physical implementation of Terapool-SDR, a cluster for Software Defined Radio (SDR) with 1024 latency-tolerant, compact RV32 PEs, sharing a global view of a 4MiB, 4096-banked, L1 memory. We report various feasible configurations of TeraPool-SDR featuring an ultra-high bandwidth PE-to-L1-memory interconnect, clocked at 730MHz, 880MHz, and 924MHz (TT/0.80 V/25 {deg}C) in 12nm FinFET technology. The TeraPool-SDR cluster achieves high energy efficiency on all SDR key kernels for 5G RANs: Fast Fourier Transform (93GOPS/W), Matrix-Multiplication (125GOPS/W), Channel Estimation (96GOPS/W), and Linear System Inversion (61GOPS/W). For all the kernels, it consumes less than 10W, in compliance with industry standards.
Read more5/9/2024

0
Optimizing 5G-Advanced Networks for Time-critical Applications: The Role of L4S
Guangjin Pan, Shugong Xu, Pin Jiang
As 5G networks strive to support advanced time-critical applications, such as immersive Extended Reality (XR), cloud gaming, and autonomous driving, the demand for Real-time Broadband Communication (RTBC) grows. In this article, we present the main mechanisms of Low Latency, Low Loss, and Scalable Throughput (L4S). Subsequently, we investigate the support and challenges of L4S technology in the latest 3GPP 5G-Advanced Release 18 (R18) standard. Our case study, using a prototype system for a real-time communication (RTC) application, demonstrates the superiority of L4S technology. The experimental results show that, compared with the GCC algorithm, the proposed L4S-GCC algorithm can reduce the stalling rate by 1.51%-2.80% and increase the bandwidth utilization by 11.4%-31.4%. The results emphasize the immense potential of L4S technology in enhancing transmission performance in time-critical applications.
Read more7/31/2024

0
MemorAI: Energy-Efficient Last-Level Cache Memory Optimization for Virtualized RANs
Ethan Sanchez Hidalgo, J. Xavier Salvat Lozano, Jose A. Ayala-Romero, Andres Garcia-Saavedra, Xi Li, Xavier Costa-Perez
The virtualization of Radio Access Networks (vRAN) is well on its way to become a reality, driven by its advantages such as flexibility and cost-effectiveness. However, virtualization comes at a high price - virtual Base Stations (vBSs) sharing the same computing platform incur a significant computing overhead due to in extremis consumption of shared cache memory resources. Consequently, vRAN suffers from increased energy consumption, which fuels the already high operational costs in 5G networks. This paper investigates cache memory allocation mechanisms' effectiveness in reducing total energy consumption. Using an experimental vRAN platform, we profile the energy consumption and CPU utilization of vBS as a function of the network state (e.g., traffic demand, modulation scheme). Then, we address the high dimensionality of the problem by decomposing it per vBS, which is possible thanks to the Last-Level Cache (LLC) isolation implemented in our system. Based on this, we train a vBS digital twin, which allows us to train offline a classifier, avoiding the performance degradation of the system during training. Our results show that our approach performs very closely to an offline optimal oracle, outperforming standard approaches used in today's deployments.
Read more5/6/2024