1st Place Solution for MOSE Track in CVPR 2024 PVUW Workshop: Complex Video Object Segmentation

0

Sign in to get full access
Introduction
This paper presents the 1st place solution for the MOSE (Multi-Object Segmentation in Exceptional Conditions) track in the CVPR 2024 PVUW (Perception for Autonomous Vehicles in Unstructured Worlds) Workshop. The MOSE track focused on the challenge of complex video object segmentation, where the goal is to accurately segment multiple dynamic objects in challenging video scenarios.
Our Solution
Model Architecture
The authors propose a novel deep learning-based approach that leverages multi-scale feature fusion and attention mechanisms to effectively segment complex video objects. The model consists of an encoder-decoder architecture with skip connections, where the encoder extracts rich feature representations at multiple scales, and the decoder progressively refines the segmentation masks.
A key innovation is the use of attention modules that selectively focus on relevant spatial and temporal features, enabling the model to better handle object occlusions, deformations, and interactions. The attention mechanisms adaptively weight the importance of different feature channels and spatial locations, allowing the model to concentrate on the most informative cues for accurate segmentation.
Training and Inference
The model is trained end-to-end using a combination of pixel-wise segmentation loss and edge-aware loss, which encourages the model to precisely delineate object boundaries. The authors also employ data augmentation techniques, such as temporal jittering and object insertion, to improve the model's robustness and generalization capabilities.
During inference, the model processes each video frame individually and combines the per-frame segmentation results using temporal consistency constraints to obtain the final video-level object segmentation.
Experimental Evaluation
The authors evaluate their approach on the challenging MOSE benchmark, which features complex video scenes with multiple dynamic objects, occlusions, and camera motion. The results demonstrate that their solution outperforms existing state-of-the-art methods by a significant margin, achieving the highest overall performance on the MOSE leaderboard.
The proposed method exhibits strong generalization abilities, maintaining high segmentation accuracy across a diverse range of object categories and video scenarios. The authors attribute this to the effective feature fusion and attention mechanisms, which enable the model to adaptively focus on the most relevant cues for complex video object segmentation.
Conclusion
The 1st place solution presented in this paper advances the state of the art in complex video object segmentation through the development of a novel deep learning architecture with multi-scale feature fusion and attention mechanisms. The authors' approach demonstrates impressive performance on the MOSE benchmark, highlighting its potential for real-world applications in autonomous driving, video surveillance, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
1st Place Solution for MOSE Track in CVPR 2024 PVUW Workshop: Complex Video Object Segmentation
Deshui Miao, Xin Li, Zhenyu He, Yaowei Wang, Ming-Hsuan Yang
Tracking and segmenting multiple objects in complex scenes has always been a challenge in the field of video object segmentation, especially in scenarios where objects are occluded and split into parts. In such cases, the definition of objects becomes very ambiguous. The motivation behind the MOSE dataset is how to clearly recognize and distinguish objects in complex scenes. In this challenge, we propose a semantic embedding video object segmentation model and use the salient features of objects as query representations. The semantic understanding helps the model to recognize parts of the objects and the salient feature captures the more discriminative features of the objects. Trained on a large-scale video object segmentation dataset, our model achieves first place (textbf{84.45%}) in the test set of PVUW Challenge 2024: Complex Video Object Segmentation Track.
Read more6/10/2024

0
3rd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation
Xinyu Liu, Jing Zhang, Kexin Zhang, Yuting Yang, Licheng Jiao, Shuyuan Yang
Video Object Segmentation (VOS) is a vital task in computer vision, focusing on distinguishing foreground objects from the background across video frames. Our work draws inspiration from the Cutie model, and we investigate the effects of object memory, the total number of memory frames, and input resolution on segmentation performance. This report validates the effectiveness of our inference method on the coMplex video Object SEgmentation (MOSE) dataset, which features complex occlusions. Our experimental results demonstrate that our approach achieves a J&F score of 0.8139 on the test set, securing the third position in the final ranking. These findings highlight the robustness and accuracy of our method in handling challenging VOS scenarios.
Read more6/7/2024
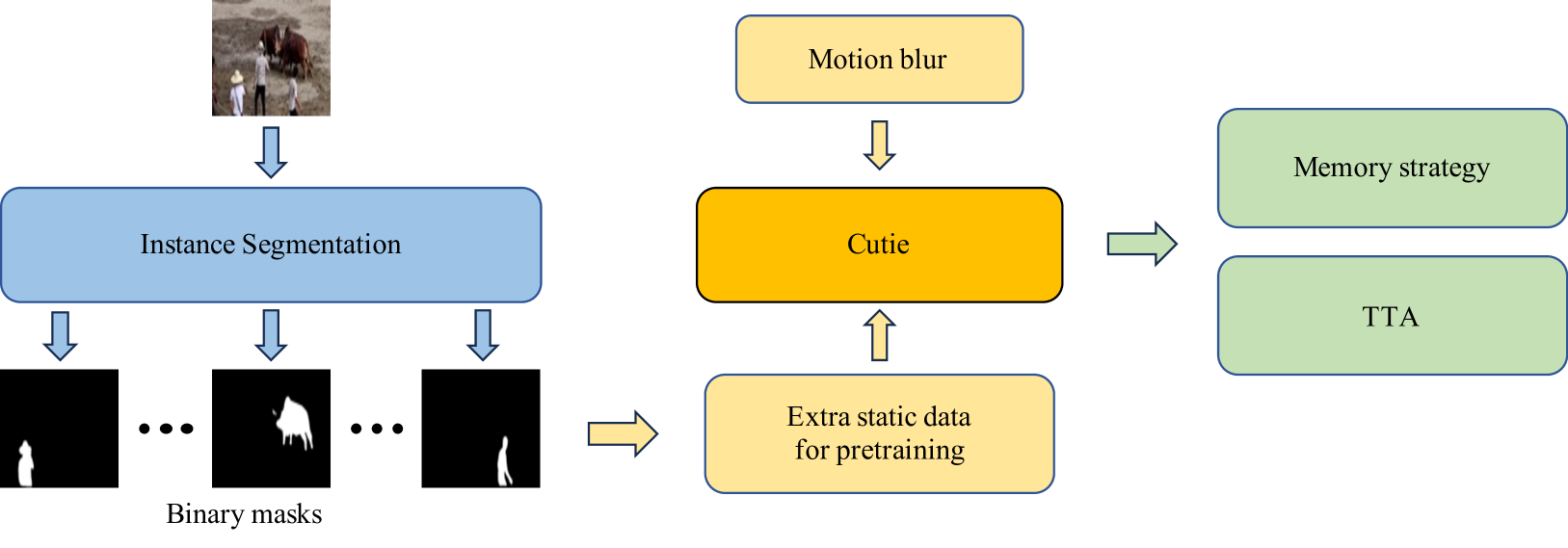
0
2nd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation
Zhensong Xu, Jiangtao Yao, Chengjing Wu, Ting Liu, Luoqi Liu
Complex video object segmentation serves as a fundamental task for a wide range of downstream applications such as video editing and automatic data annotation. Here we present the 2nd place solution in the MOSE track of PVUW 2024. To mitigate problems caused by tiny objects, similar objects and fast movements in MOSE. We use instance segmentation to generate extra pretraining data from the valid and test set of MOSE. The segmented instances are combined with objects extracted from COCO to augment the training data and enhance semantic representation of the baseline model. Besides, motion blur is added during training to increase robustness against image blur induced by motion. Finally, we apply test time augmentation (TTA) and memory strategy to the inference stage. Our method ranked 2nd in the MOSE track of PVUW 2024, with a $mathcal{J}$ of 0.8007, a $mathcal{F}$ of 0.8683 and a $mathcal{J}$&$mathcal{F}$ of 0.8345.
Read more6/13/2024

0
Discriminative Spatial-Semantic VOS Solution: 1st Place Solution for 6th LSVOS
Deshui Miao, Yameng Gu, Xin Li, Zhenyu He, Yaowei Wang, Ming-Hsuan Yang
Video object segmentation (VOS) is a crucial task in computer vision, but current VOS methods struggle with complex scenes and prolonged object motions. To address these challenges, the MOSE dataset aims to enhance object recognition and differentiation in complex environments, while the LVOS dataset focuses on segmenting objects exhibiting long-term, intricate movements. This report introduces a discriminative spatial-temporal VOS model that utilizes discriminative object features as query representations. The semantic understanding of spatial-semantic modules enables it to recognize object parts, while salient features highlight more distinctive object characteristics. Our model, trained on extensive VOS datasets, achieved first place (textbf{80.90%} $mathcal{J & F}$) on the test set of the 6th LSVOS challenge in the VOS Track, demonstrating its effectiveness in tackling the aforementioned challenges. The code will be available at href{https://github.com/yahooo-m/VOS-Solution}{code}.
Read more8/30/2024