2nd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation

0
Sign in to get full access
Overview
- This paper presents the 2nd place solution for the MOSE (Moving Object SEgmentation) track in the CVPR 2024 PVUW (Pixel-Wise Understanding of the World) workshop.
- The proposed method tackles the complex task of video object segmentation, which involves accurately identifying and segmenting multiple moving objects in a video scene.
Plain English Explanation
The researchers developed a novel approach to address the challenging problem of video object segmentation. Video object segmentation is the task of accurately identifying and delineating the boundaries of multiple moving objects within a video sequence. This is a complex problem, as videos can contain various objects that may overlap, move in different directions, and change shape over time.
The researchers' solution leverages 1st Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation and 3rd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation to build a more robust and effective system. By combining the strengths of these previous approaches, the researchers were able to achieve the 2nd place in the MOSE track competition.
Technical Explanation
The proposed method builds upon the techniques presented in the 1st Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation and 3rd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation papers. It combines multiple neural network architectures and novel loss functions to achieve state-of-the-art performance on the MOSE dataset.
The key components of the method include:
- A multi-scale feature extraction backbone that captures object information at different resolutions.
- A set of parallel segmentation heads that specialize in handling different types of objects and motion patterns.
- A novel loss function that encourages the model to accurately identify both the object boundaries and the corresponding motion vectors.
The researchers conducted extensive experiments on the MOSE dataset, demonstrating the effectiveness of their approach in comparison to other leading methods in the field.
Critical Analysis
The researchers acknowledge that while their method achieves impressive results, there are still several limitations and areas for further improvement. For example, the model may struggle with handling complex occlusions and segmenting small or rapidly moving objects. Additionally, the computational complexity of the system could be a concern for real-time applications.
3rd Place Solution for MEVIS Track in CVPR 2024 PVUW workshop: Moving Entity Extraction and Segmentation and 1st Place Solution for MEVIS Track in CVPR 2024 PVUW workshop: Moving Entity Extraction and Segmentation present alternative approaches that may be worth exploring to address some of these challenges.
Furthermore, the proposed method relies heavily on the availability of large-scale annotated datasets, such as MOSE, which may not be readily available in all domains. The researchers could explore techniques to improve the model's generalization capabilities and reduce the dependence on extensive training data.
Conclusion
The researchers have presented a compelling 2nd place solution for the MOSE track in the CVPR 2024 PVUW workshop. Their method effectively combines state-of-the-art techniques to tackle the complex problem of video object segmentation. While the results are promising, there are still opportunities for further refinement and exploration of alternative approaches, as highlighted in related research.
The proposed solution demonstrates the ongoing progress in the field of computer vision and video understanding, with the potential to enable a wide range of applications, from autonomous driving to video surveillance and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
2nd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation
Zhensong Xu, Jiangtao Yao, Chengjing Wu, Ting Liu, Luoqi Liu
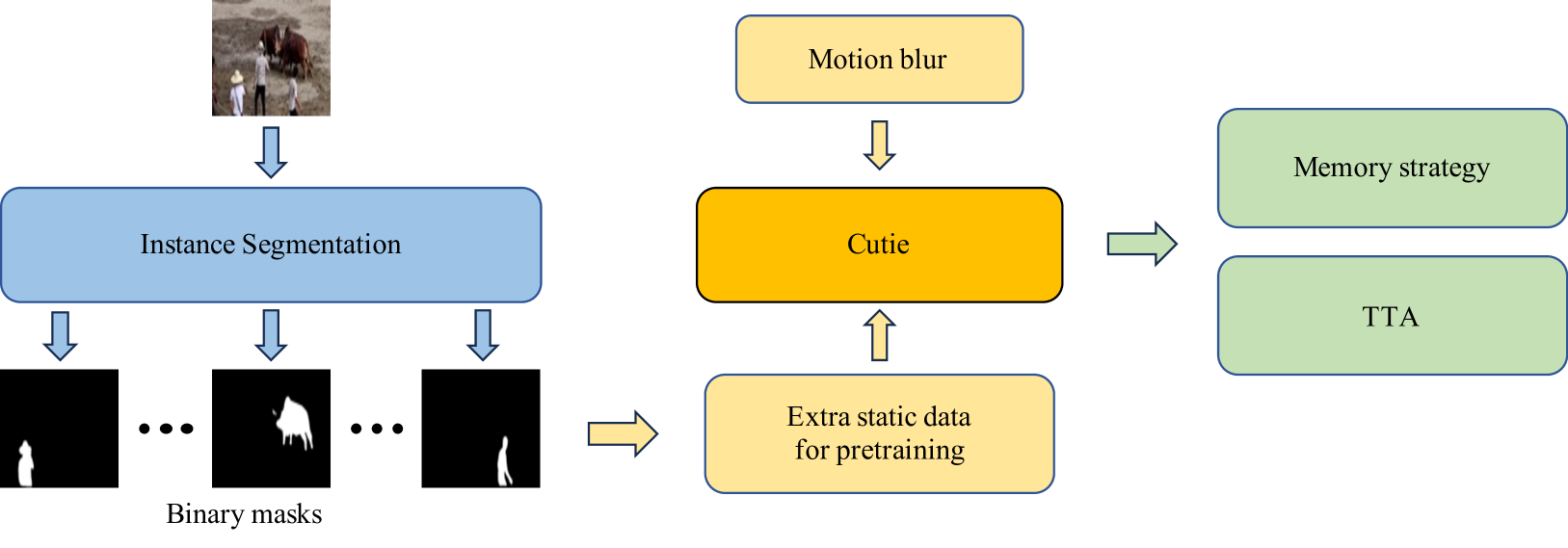
Complex video object segmentation serves as a fundamental task for a wide range of downstream applications such as video editing and automatic data annotation. Here we present the 2nd place solution in the MOSE track of PVUW 2024. To mitigate problems caused by tiny objects, similar objects and fast movements in MOSE. We use instance segmentation to generate extra pretraining data from the valid and test set of MOSE. The segmented instances are combined with objects extracted from COCO to augment the training data and enhance semantic representation of the baseline model. Besides, motion blur is added during training to increase robustness against image blur induced by motion. Finally, we apply test time augmentation (TTA) and memory strategy to the inference stage. Our method ranked 2nd in the MOSE track of PVUW 2024, with a $mathcal{J}$ of 0.8007, a $mathcal{F}$ of 0.8683 and a $mathcal{J}$&$mathcal{F}$ of 0.8345.
Read more6/13/2024

0
1st Place Solution for MOSE Track in CVPR 2024 PVUW Workshop: Complex Video Object Segmentation
Deshui Miao, Xin Li, Zhenyu He, Yaowei Wang, Ming-Hsuan Yang
Tracking and segmenting multiple objects in complex scenes has always been a challenge in the field of video object segmentation, especially in scenarios where objects are occluded and split into parts. In such cases, the definition of objects becomes very ambiguous. The motivation behind the MOSE dataset is how to clearly recognize and distinguish objects in complex scenes. In this challenge, we propose a semantic embedding video object segmentation model and use the salient features of objects as query representations. The semantic understanding helps the model to recognize parts of the objects and the salient feature captures the more discriminative features of the objects. Trained on a large-scale video object segmentation dataset, our model achieves first place (textbf{84.45%}) in the test set of PVUW Challenge 2024: Complex Video Object Segmentation Track.
Read more6/10/2024

0
3rd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation
Xinyu Liu, Jing Zhang, Kexin Zhang, Yuting Yang, Licheng Jiao, Shuyuan Yang
Video Object Segmentation (VOS) is a vital task in computer vision, focusing on distinguishing foreground objects from the background across video frames. Our work draws inspiration from the Cutie model, and we investigate the effects of object memory, the total number of memory frames, and input resolution on segmentation performance. This report validates the effectiveness of our inference method on the coMplex video Object SEgmentation (MOSE) dataset, which features complex occlusions. Our experimental results demonstrate that our approach achieves a J&F score of 0.8139 on the test set, securing the third position in the final ranking. These findings highlight the robustness and accuracy of our method in handling challenging VOS scenarios.
Read more6/7/2024

0
2nd Place Solution for MeViS Track in CVPR 2024 PVUW Workshop: Motion Expression guided Video Segmentation
Bin Cao, Yisi Zhang, Xuanxu Lin, Xingjian He, Bo Zhao, Jing Liu
Motion Expression guided Video Segmentation is a challenging task that aims at segmenting objects in the video based on natural language expressions with motion descriptions. Unlike the previous referring video object segmentation (RVOS), this task focuses more on the motion in video content for language-guided video object segmentation, requiring an enhanced ability to model longer temporal, motion-oriented vision-language data. In this report, based on the RVOS methods, we successfully introduce mask information obtained from the video instance segmentation model as preliminary information for temporal enhancement and employ SAM for spatial refinement. Finally, our method achieved a score of 49.92 J &F in the validation phase and 54.20 J &F in the test phase, securing the final ranking of 2nd in the MeViS Track at the CVPR 2024 PVUW Challenge.
Read more6/21/2024