3D Gaussian Blendshapes for Head Avatar Animation
2404.19398
0
1
🤿
Abstract
We introduce 3D Gaussian blendshapes for modeling photorealistic head avatars. Taking a monocular video as input, we learn a base head model of neutral expression, along with a group of expression blendshapes, each of which corresponds to a basis expression in classical parametric face models. Both the neutral model and expression blendshapes are represented as 3D Gaussians, which contain a few properties to depict the avatar appearance. The avatar model of an arbitrary expression can be effectively generated by combining the neutral model and expression blendshapes through linear blending of Gaussians with the expression coefficients. High-fidelity head avatar animations can be synthesized in real time using Gaussian splatting. Compared to state-of-the-art methods, our Gaussian blendshape representation better captures high-frequency details exhibited in input video, and achieves superior rendering performance.
Create account to get full access
Overview
- This paper introduces a new method for creating photorealistic 3D head avatars using a monocular video input.
- The key innovation is the use of 3D Gaussian blendshapes to model the neutral head shape and expression variations.
- This Gaussian blendshape representation captures high-frequency details better than previous methods and allows for real-time animation synthesis.
Plain English Explanation
The researchers have developed a new way to create realistic 3D digital avatars of human heads using just a standard video. Their approach is based on representing the neutral head shape and different facial expressions as 3D Gaussian distributions, which are mathematical models that can efficiently capture the shape and appearance of the head.
By combining the neutral head model with these Gaussian "blendshapes" for various expressions, the system can generate a 3D avatar that can be animated in real-time to match the movements and expressions in the input video. This Gaussian blendshape representation is able to better capture fine details compared to previous methods, leading to more photorealistic avatars.
The key advantage of this approach is that it can create high-quality, animatable 3D head models from monocular video data, without requiring specialized 3D scanning hardware or complex multi-view setups. This makes the technology more accessible and practical for a wide range of applications, such as virtual reality, videoconferencing, and digital entertainment.
Technical Explanation
The paper introduces a novel 3D head avatar modeling technique based on Gaussian blendshapes. Taking a monocular video as input, the method first learns a base 3D Gaussian model representing the neutral expression of the head. It then learns a set of additional Gaussian "blendshapes," each capturing a specific facial expression.
The full 3D avatar for any expression can then be efficiently generated by linearly combining the neutral head model and the relevant blendshapes, weighted by expression coefficients. This Gaussian blendshape representation allows for high-fidelity rendering of the head avatar in real-time using a technique called Gaussian splatting.
Compared to state-of-the-art methods, the authors show that their Gaussian blendshape approach better captures the high-frequency details present in the input video, leading to more photorealistic and expressive head avatars. The method also outperforms previous techniques in terms of rendering efficiency, making it suitable for interactive applications like virtual avatars and mixed reality experiences.
Critical Analysis
The paper presents a compelling approach for creating high-quality 3D head avatars from monocular video data. The use of 3D Gaussian blendshapes is a novel and effective way to capture both the neutral head shape and the variations in facial expressions.
One potential limitation mentioned in the paper is that the method may struggle with extreme head poses or occlusions in the input video, as the Gaussian blendshape representation may not be able to fully account for such variations. Further research could explore ways to address these edge cases, perhaps by incorporating additional data sources or more advanced modeling techniques.
Another area for potential improvement is the ability to generate avatars that maintain personal identity and likeness. While the paper demonstrates impressive visual quality, it's unclear how well the method preserves the unique facial features and characteristics of the individual in the input video. Exploring ways to better retain identity while still achieving photorealistic rendering could be an interesting direction for future work.
Overall, this research represents an exciting advance in the field of 3D head avatar modeling, with the potential to enable more natural and immersive virtual experiences across a wide range of applications.
Conclusion
This paper presents a novel approach for creating photorealistic 3D head avatars from monocular video inputs. By representing the head shape and facial expressions as 3D Gaussian blendshapes, the method is able to capture high-frequency details and enable real-time animation synthesis.
The key strengths of this technique are its ability to generate high-quality avatars from standard video data, without requiring specialized 3D scanning hardware, as well as its efficient rendering performance. These advantages make the technology well-suited for a variety of applications, from virtual reality and videoconferencing to digital entertainment and mixed reality experiences.
While the paper identifies some potential limitations, the overall approach represents an important step forward in the field of 3D head avatar modeling. As the technology continues to evolve, we can expect to see even more realistic and expressive digital avatars that seamlessly blend the physical and virtual worlds.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
GGAvatar: Geometric Adjustment of Gaussian Head Avatar
Xinyang Li, Jiaxin Wang, Yixin Xuan, Gongxin Yao, Yu Pan
0
0
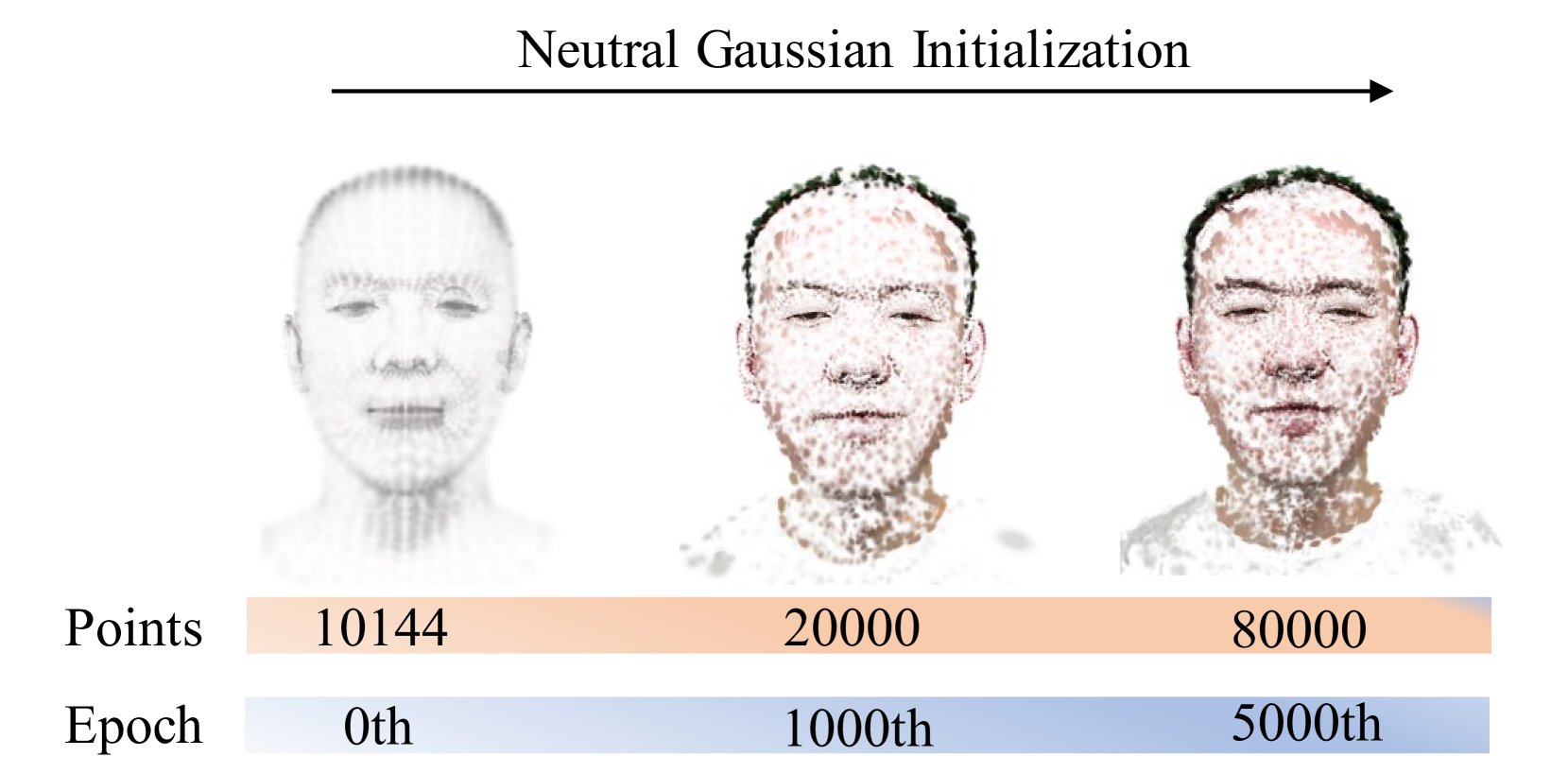
We propose GGAvatar, a novel 3D avatar representation designed to robustly model dynamic head avatars with complex identities and deformations. GGAvatar employs a coarse-to-fine structure, featuring two core modules: Neutral Gaussian Initialization Module and Geometry Morph Adjuster. Neutral Gaussian Initialization Module pairs Gaussian primitives with deformable triangular meshes, employing an adaptive density control strategy to model the geometric structure of the target subject with neutral expressions. Geometry Morph Adjuster introduces deformation bases for each Gaussian in global space, creating fine-grained low-dimensional representations of deformation behaviors to address the Linear Blend Skinning formula's limitations effectively. Extensive experiments show that GGAvatar can produce high-fidelity renderings, outperforming state-of-the-art methods in visual quality and quantitative metrics.
5/21/2024
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Ziqian Bai, Feitong Tan, Sean Fanello, Rohit Pandey, Mingsong Dou, Shichen Liu, Ping Tan, Yinda Zhang
0
0
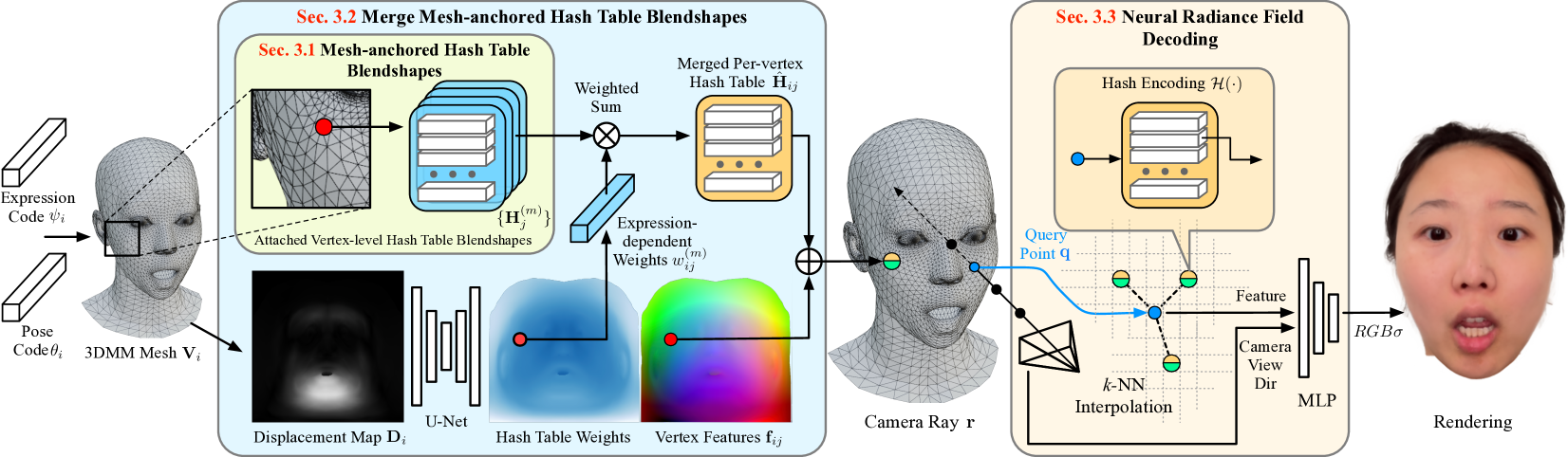
3D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
4/3/2024
New!PSAvatar: A Point-based Shape Model for Real-Time Head Avatar Animation with 3D Gaussian Splatting
Zhongyuan Zhao, Zhenyu Bao, Qing Li, Guoping Qiu, Kanglin Liu
0
0
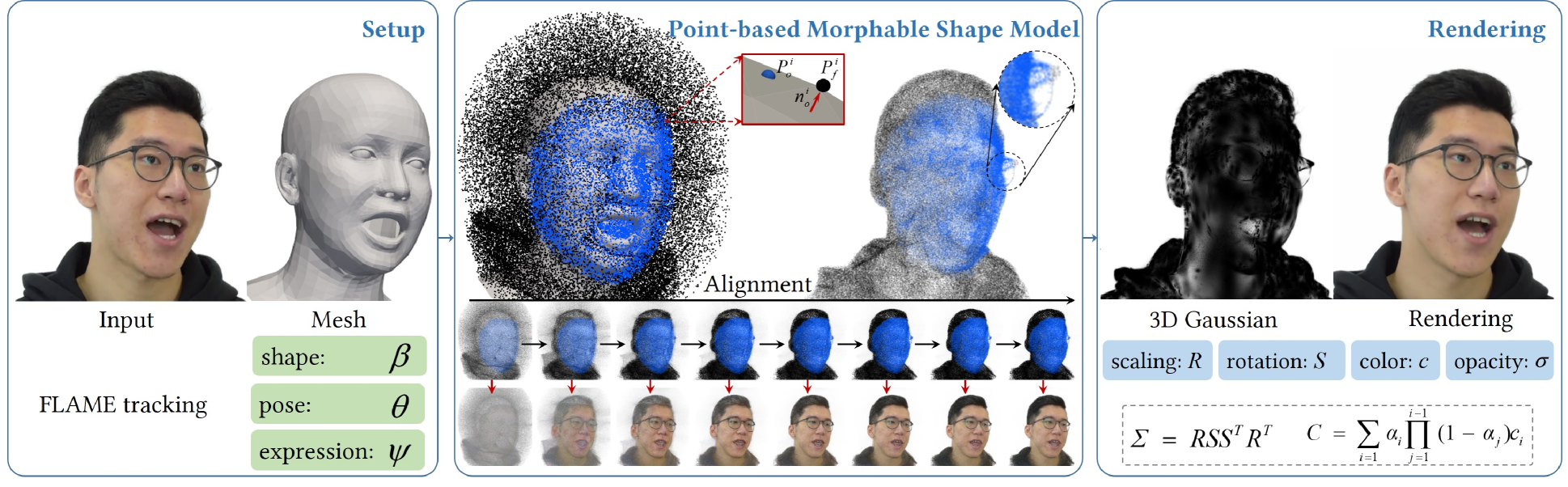
Despite much progress, achieving real-time high-fidelity head avatar animation is still difficult and existing methods have to trade-off between speed and quality. 3DMM based methods often fail to model non-facial structures such as eyeglasses and hairstyles, while neural implicit models suffer from deformation inflexibility and rendering inefficiency. Although 3D Gaussian has been demonstrated to possess promising capability for geometry representation and radiance field reconstruction, applying 3D Gaussian in head avatar creation remains a major challenge since it is difficult for 3D Gaussian to model the head shape variations caused by changing poses and expressions. In this paper, we introduce PSAvatar, a novel framework for animatable head avatar creation that utilizes discrete geometric primitive to create a parametric morphable shape model and employs 3D Gaussian for fine detail representation and high fidelity rendering. The parametric morphable shape model is a Point-based Morphable Shape Model (PMSM) which uses points instead of meshes for 3D representation to achieve enhanced representation flexibility. The PMSM first converts the FLAME mesh to points by sampling on the surfaces as well as off the meshes to enable the reconstruction of not only surface-like structures but also complex geometries such as eyeglasses and hairstyles. By aligning these points with the head shape in an analysis-by-synthesis manner, the PMSM makes it possible to utilize 3D Gaussian for fine detail representation and appearance modeling, thus enabling the creation of high-fidelity avatars. We show that PSAvatar can reconstruct high-fidelity head avatars of a variety of subjects and the avatars can be animated in real-time ($ge$ 25 fps at a resolution of 512 $times$ 512 ).
6/25/2024
GaussianHead: High-fidelity Head Avatars with Learnable Gaussian Derivation
Jie Wang, Jiu-Cheng Xie, Xianyan Li, Feng Xu, Chi-Man Pun, Hao Gao
0
0
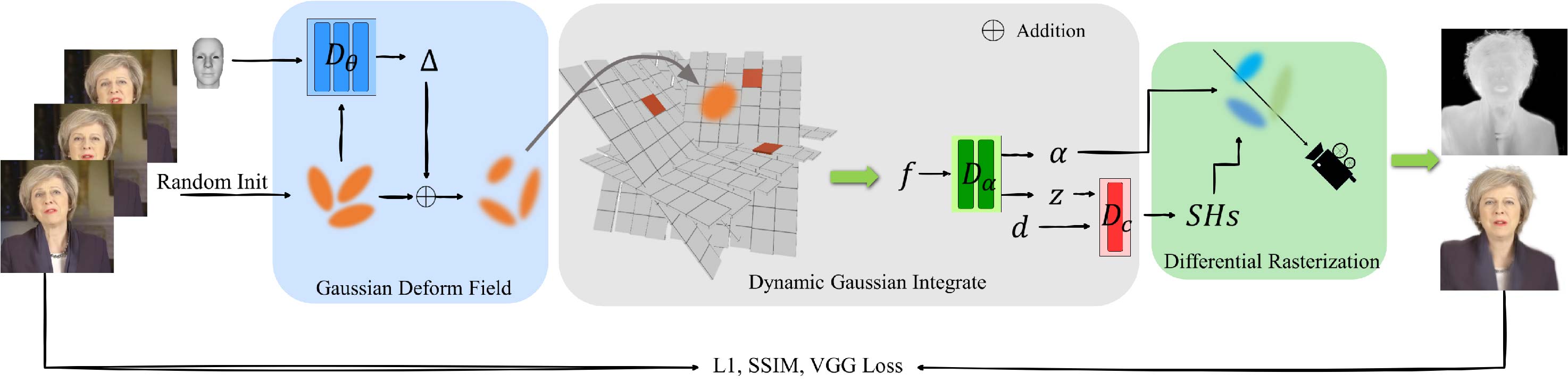
Constructing vivid 3D head avatars for given subjects and realizing a series of animations on them is valuable yet challenging. This paper presents GaussianHead, which models the actional human head with anisotropic 3D Gaussians. In our framework, a motion deformation field and multi-resolution tri-plane are constructed respectively to deal with the head's dynamic geometry and complex texture. Notably, we impose an exclusive derivation scheme on each Gaussian, which generates its multiple doppelgangers through a set of learnable parameters for position transformation. With this design, we can compactly and accurately encode the appearance information of Gaussians, even those fitting the head's particular components with sophisticated structures. In addition, an inherited derivation strategy for newly added Gaussians is adopted to facilitate training acceleration. Extensive experiments show that our method can produce high-fidelity renderings, outperforming state-of-the-art approaches in reconstruction, cross-identity reenactment, and novel view synthesis tasks. Our code is available at: https://github.com/chiehwangs/gaussian-head.
5/31/2024