GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh
2404.07991
0
0
Abstract
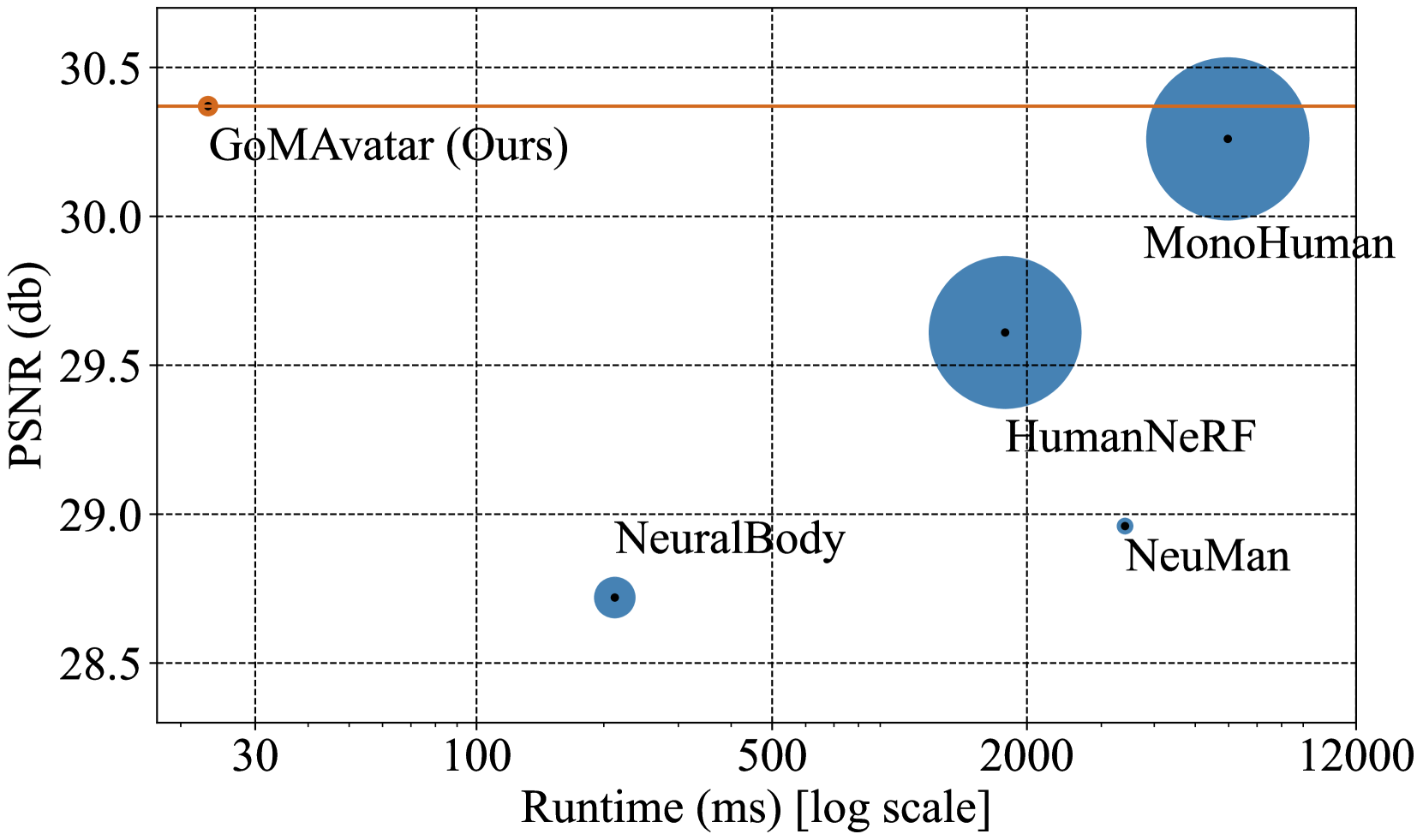
We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject).
Create account to get full access
Overview
This paper presents a novel method called GoMAvatar for efficient and animatable human modeling from monocular video. The key idea is to represent the human body as a set of Gaussians attached to a 3D mesh, which allows for realistic animation and low-dimensional control. The authors demonstrate the effectiveness of GoMAvatar on a variety of tasks, including human reconstruction, animation, and data-driven character control.
Plain English Explanation
The researchers developed a new way to create 3D digital avatars of people using just a single video camera. Typically, creating detailed, animated 3D models of people is very difficult and requires specialized equipment. However, this new method, called GoMAvatar, can do it using just a regular video.
The key insight is to represent the human body using a collection of Gaussian "blobs" attached to a 3D mesh. This allows the model to capture the detailed shape and texture of the person, while also enabling realistic animation and control. For example, you could use GoMAvatar to create an animated 3D version of yourself that can move and express emotions, all from a simple video.
The advantage of this approach is that it is much more efficient and practical than previous methods, which often required expensive camera rigs or complex data collection. With GoMAvatar, you can create high-quality, animatable 3D avatars just from a video filmed on your smartphone. This could have applications in areas like virtual reality, gaming, and digital entertainment.
Technical Explanation
The core of the GoMAvatar method is the use of Gaussians-on-Mesh (GoM), a compact representation that models the human body as a set of Gaussian distributions attached to a 3D mesh. This allows the model to capture detailed geometry and appearance, while also enabling efficient animation through the manipulation of the Gaussian parameters.
The authors train the GoMAvatar model in a self-supervised manner using monocular video data. They first extract 2D keypoints and project them onto the 3D mesh to obtain a coarse shape. They then optimize the Gaussian parameters to closely match the observed 2D projections, effectively recovering the 3D shape and texture.
Once the initial model is created, the authors demonstrate how GoMAvatar can be used for a variety of tasks, including 3D reconstruction, animation, and data-driven character control. The compact Gaussian representation allows for efficient optimization and rendering, making GoMAvatar a promising approach for real-time applications.
Critical Analysis
The GoMAvatar method represents an interesting and promising approach to human modeling and animation from monocular video. The use of Gaussians-on-Mesh provides a flexible and efficient representation that can capture detailed geometry and appearance, while also enabling realistic animation.
One potential limitation of the method is that it may struggle to model highly complex or non-rigid deformations, as the Gaussian representation may not be able to capture all the nuances of human motion. Additionally, the self-supervised training approach may introduce some artifacts or inaccuracies, especially in cases where the input video data is of lower quality or contains occlusions.
It would also be interesting to see how GoMAvatar compares to other state-of-the-art methods, such as PhysAvatar or GeneAvatar, in terms of both performance and practical applicability.
Overall, the GoMAvatar method is a promising step forward in the field of human modeling and animation, and the authors have demonstrated its potential through a range of experiments and applications.
Conclusion
The GoMAvatar method presented in this paper offers an efficient and practical approach to creating animatable 3D human models from monocular video. By representing the human body as a set of Gaussians attached to a 3D mesh, the authors have developed a flexible and compact representation that enables realistic animation and control.
The self-supervised training process and the use of Gaussians-on-Mesh make GoMAvatar a promising candidate for real-time applications in areas such as virtual reality, gaming, and digital entertainment. While the method may have some limitations in modeling highly complex deformations, the authors have demonstrated its effectiveness on a variety of tasks, highlighting its potential to advance the field of human modeling and animation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
New!FAGhead: Fully Animate Gaussian Head from Monocular Videos
Yixin Xuan, Xinyang Li, Gongxin Yao, Shiwei Zhou, Donghui Sun, Xiaoxin Chen, Yu Pan
0
0
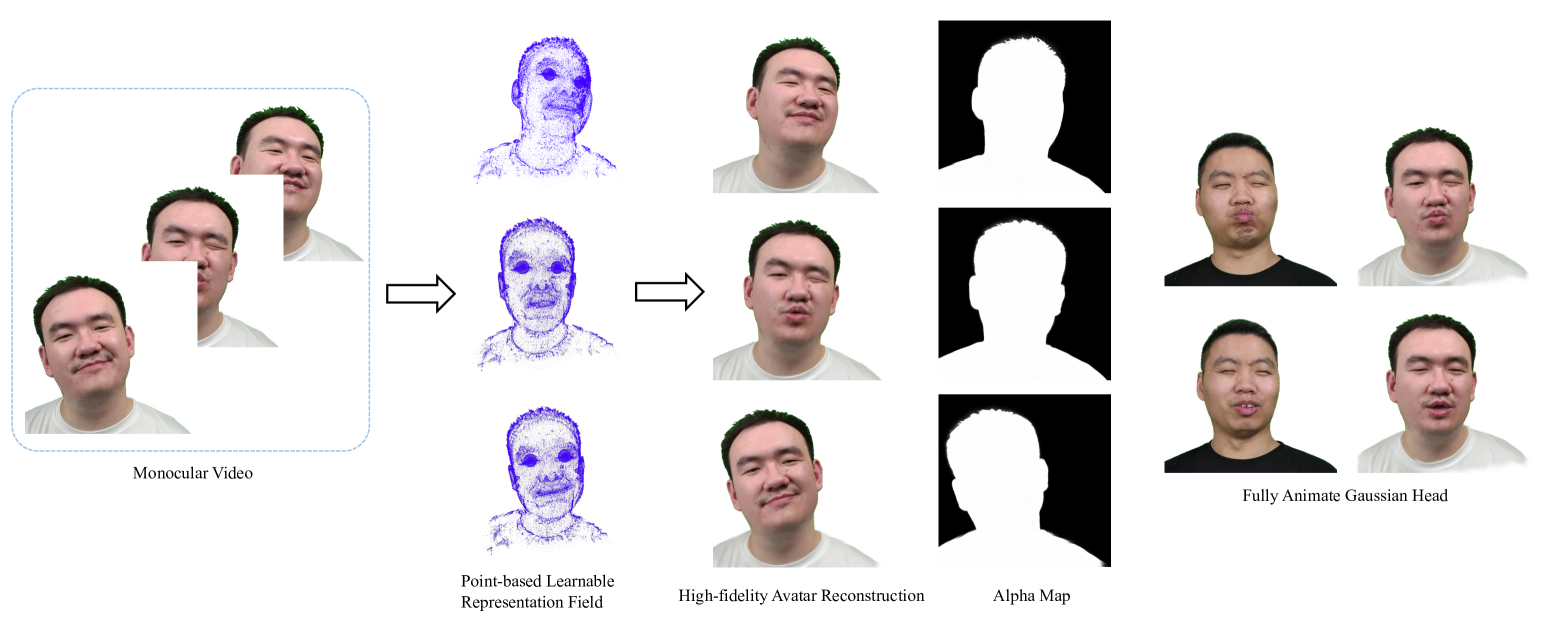
High-fidelity reconstruction of 3D human avatars has a wild application in visual reality. In this paper, we introduce FAGhead, a method that enables fully controllable human portraits from monocular videos. We explicit the traditional 3D morphable meshes (3DMM) and optimize the neutral 3D Gaussians to reconstruct with complex expressions. Furthermore, we employ a novel Point-based Learnable Representation Field (PLRF) with learnable Gaussian point positions to enhance reconstruction performance. Meanwhile, to effectively manage the edges of avatars, we introduced the alpha rendering to supervise the alpha value of each pixel. Extensive experimental results on the open-source datasets and our capturing datasets demonstrate that our approach is able to generate high-fidelity 3D head avatars and fully control the expression and pose of the virtual avatars, which is outperforming than existing works.
6/28/2024
📊
FlashAvatar: High-fidelity Head Avatar with Efficient Gaussian Embedding
Jun Xiang, Xuan Gao, Yudong Guo, Juyong Zhang
0
0
We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed. Project page: https://ustc3dv.github.io/FlashAvatar/
4/1/2024
GGAvatar: Geometric Adjustment of Gaussian Head Avatar
Xinyang Li, Jiaxin Wang, Yixin Xuan, Gongxin Yao, Yu Pan
0
0
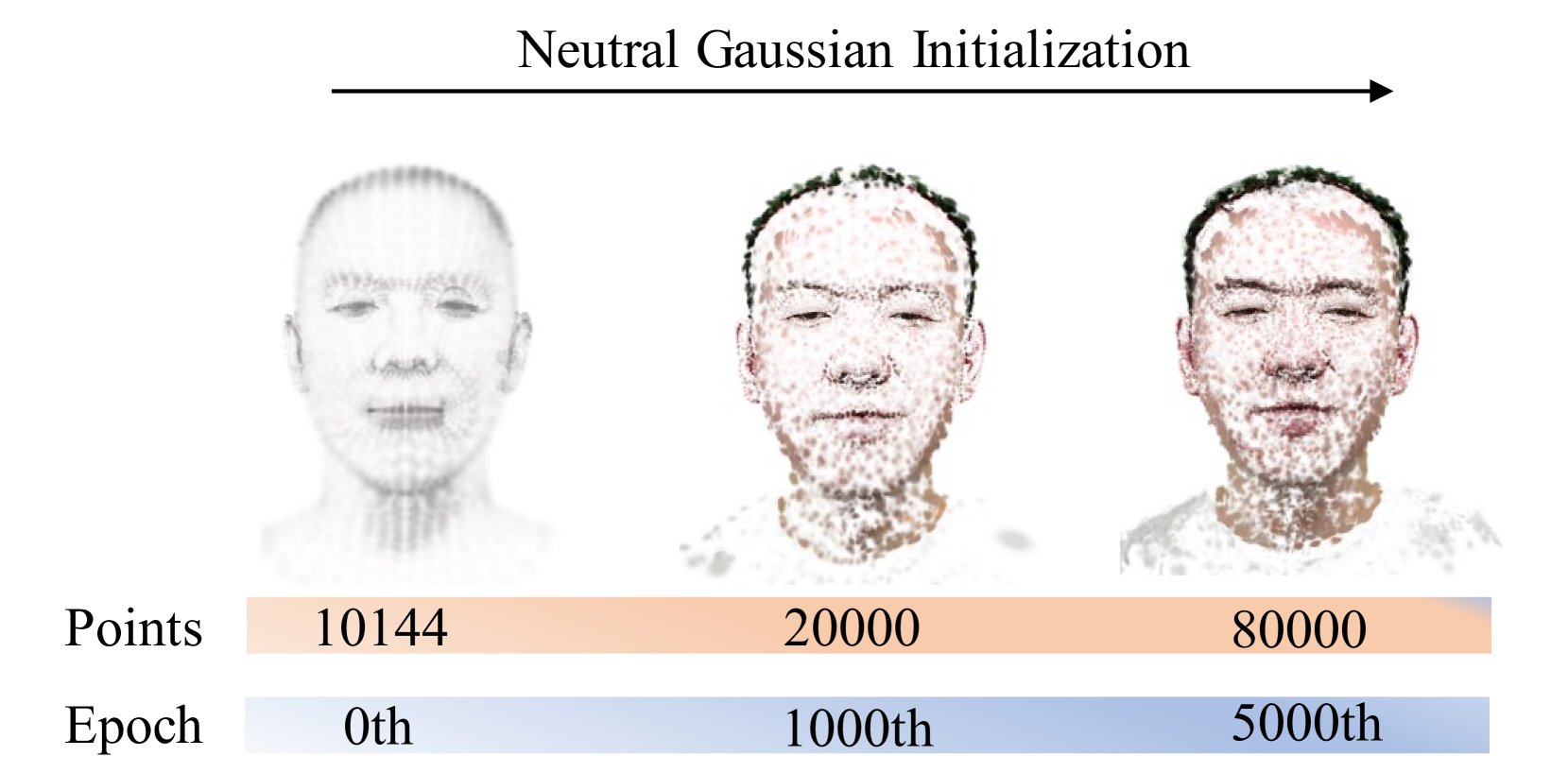
We propose GGAvatar, a novel 3D avatar representation designed to robustly model dynamic head avatars with complex identities and deformations. GGAvatar employs a coarse-to-fine structure, featuring two core modules: Neutral Gaussian Initialization Module and Geometry Morph Adjuster. Neutral Gaussian Initialization Module pairs Gaussian primitives with deformable triangular meshes, employing an adaptive density control strategy to model the geometric structure of the target subject with neutral expressions. Geometry Morph Adjuster introduces deformation bases for each Gaussian in global space, creating fine-grained low-dimensional representations of deformation behaviors to address the Linear Blend Skinning formula's limitations effectively. Extensive experiments show that GGAvatar can produce high-fidelity renderings, outperforming state-of-the-art methods in visual quality and quantitative metrics.
5/21/2024

Animatable and Relightable Gaussians for High-fidelity Human Avatar Modeling
Zhe Li, Yipengjing Sun, Zerong Zheng, Lizhen Wang, Shengping Zhang, Yebin Liu
0
0
Modeling animatable human avatars from RGB videos is a long-standing and challenging problem. Recent works usually adopt MLP-based neural radiance fields (NeRF) to represent 3D humans, but it remains difficult for pure MLPs to regress pose-dependent garment details. To this end, we introduce Animatable Gaussians, a new avatar representation that leverages powerful 2D CNNs and 3D Gaussian splatting to create high-fidelity avatars. To associate 3D Gaussians with the animatable avatar, we learn a parametric template from the input videos, and then parameterize the template on two front & back canonical Gaussian maps where each pixel represents a 3D Gaussian. The learned template is adaptive to the wearing garments for modeling looser clothes like dresses. Such template-guided 2D parameterization enables us to employ a powerful StyleGAN-based CNN to learn the pose-dependent Gaussian maps for modeling detailed dynamic appearances. Furthermore, we introduce a pose projection strategy for better generalization given novel poses. To tackle the realistic relighting of animatable avatars, we introduce physically-based rendering into the avatar representation for decomposing avatar materials and environment illumination. Overall, our method can create lifelike avatars with dynamic, realistic, generalized and relightable appearances. Experiments show that our method outperforms other state-of-the-art approaches.
5/28/2024