FlashAvatar: High-fidelity Head Avatar with Efficient Gaussian Embedding
2312.02214
0
0
📊
Abstract
We propose FlashAvatar, a novel and lightweight 3D animatable avatar representation that could reconstruct a digital avatar from a short monocular video sequence in minutes and render high-fidelity photo-realistic images at 300FPS on a consumer-grade GPU. To achieve this, we maintain a uniform 3D Gaussian field embedded in the surface of a parametric face model and learn extra spatial offset to model non-surface regions and subtle facial details. While full use of geometric priors can capture high-frequency facial details and preserve exaggerated expressions, proper initialization can help reduce the number of Gaussians, thus enabling super-fast rendering speed. Extensive experimental results demonstrate that FlashAvatar outperforms existing works regarding visual quality and personalized details and is almost an order of magnitude faster in rendering speed. Project page: https://ustc3dv.github.io/FlashAvatar/
Get summaries of the top AI research delivered straight to your inbox:
Overview
- FlashAvatar is a new technology that can create 3D animated avatars from a short video
- It can generate high-quality, photo-realistic images of the avatars at very fast speeds
- This is achieved through a novel 3D representation and fast rendering approach
Plain English Explanation
FlashAvatar is a system that can take a short video of a person and quickly create a 3D digital avatar that looks just like them. This avatar can then be animated and used to generate realistic-looking images at very high speeds, even on common consumer computers.
The key innovation is how FlashAvatar represents the 3D shape of the face and other facial features. Instead of a detailed 3D mesh, it uses a more lightweight "Gaussian field" approach. This allows the system to capture intricate details like wrinkles and expressions, while still being able to render the avatar images extremely quickly.
By using this efficient 3D representation and some other clever techniques, FlashAvatar can create personalized avatars from just a short video in a matter of minutes. It then generates the avatar images at 300 frames per second, which is fast enough for real-time applications like virtual meetings or games.
Technical Explanation
FlashAvatar works by maintaining a 3D "Gaussian field" - a mathematical representation of the face's surface and underlying structure. This allows it to model not just the surface details, but also the subtle sub-surface features that give a face its unique character.
The system learns these Gaussian fields from the input video, using a parametric face model as a starting point. It also learns additional spatial offsets to capture non-surface regions and fine facial details that the basic model might miss.
Careful initialization of the Gaussian fields helps reduce the number required, which in turn enables the extremely fast 300FPS rendering speed on consumer GPUs. The researchers show that this approach outperforms prior work in terms of visual quality and level of personalized detail, while being an order of magnitude faster.
Critical Analysis
The FlashAvatar system demonstrates impressive results, but there are a few potential limitations worth considering. The paper does not provide much information on the robustness of the approach - how well does it handle occluded faces, dramatic lighting changes, or significant pose variation in the input video?
Additionally, the system was only evaluated on a limited dataset of young, western adults. It's unclear how well it would generalize to more diverse populations or age groups. Further research would be needed to assess the system's broader applicability.
That said, the core technical innovations around the Gaussian field representation and fast rendering are compelling. If the approach can be further refined and validated, it could enable many new applications for personalized, real-time 3D avatars.
Conclusion
FlashAvatar presents a novel and efficient 3D avatar representation that can generate high-fidelity, personalized digital avatars from short video inputs. The system's ability to create these avatars quickly and render them at extremely high frame rates opens up new possibilities for real-time, interactive virtual experiences.
While there are some open questions about the approach's robustness and generalizability, the technical innovations demonstrated in this work are an important step forward for avatar technology. With further refinement and validation, FlashAvatar could enable a wide range of new applications in gaming, virtual communication, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
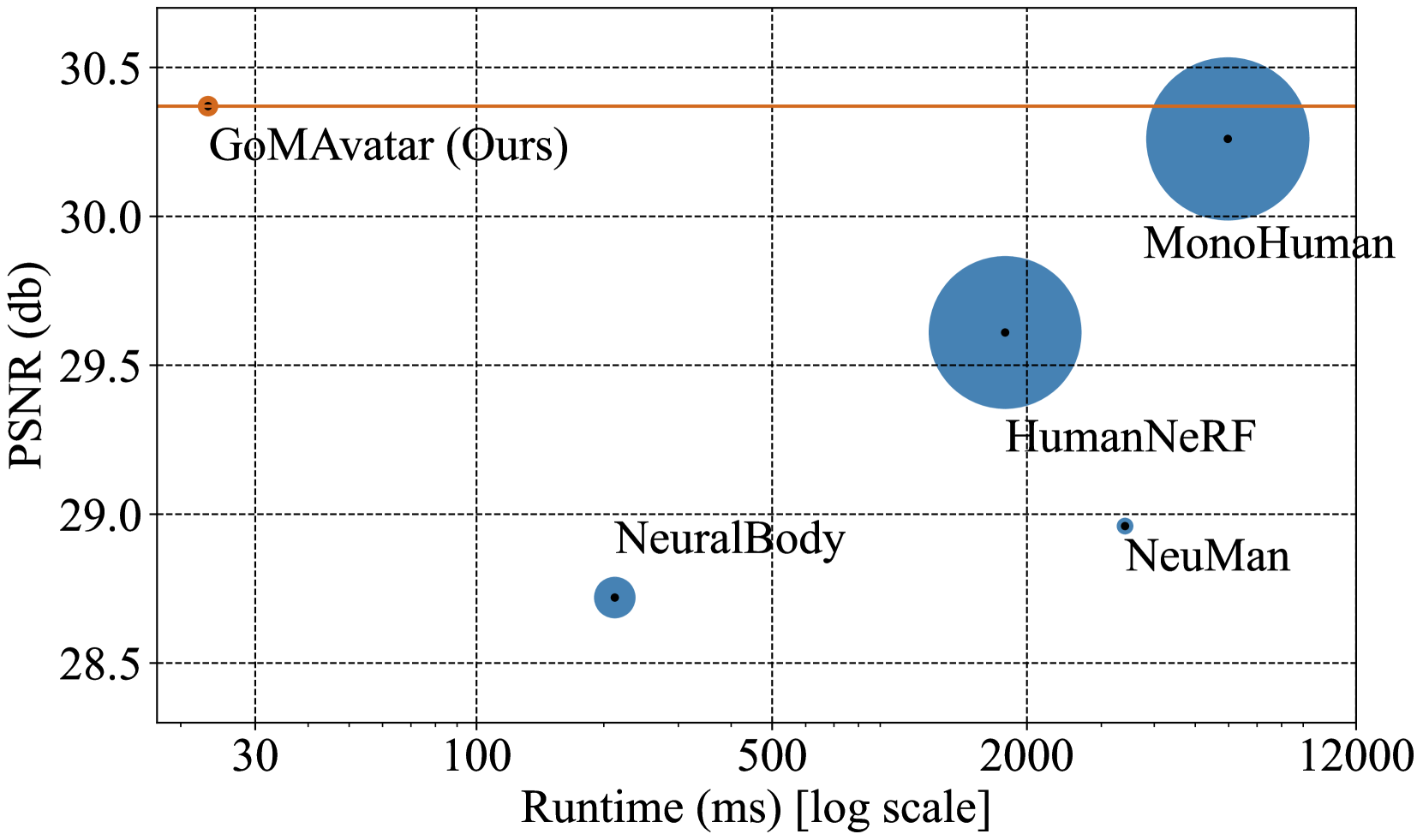
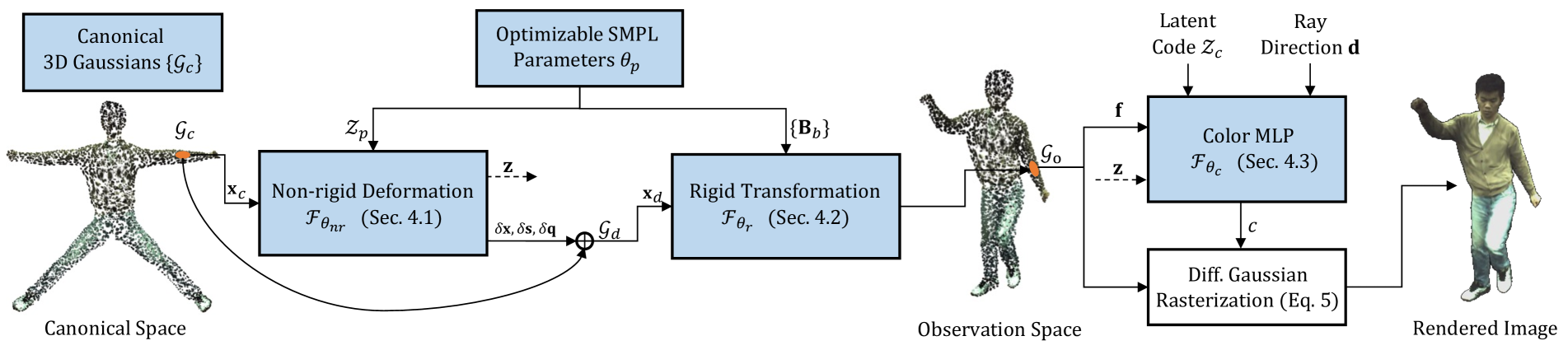
GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh
Jing Wen, Xiaoming Zhao, Zhongzheng Ren, Alexander G. Schwing, Shenlong Wang
0
0
We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject).
4/12/2024
✨
GAvatar: Animatable 3D Gaussian Avatars with Implicit Mesh Learning
Ye Yuan, Xueting Li, Yangyi Huang, Shalini De Mello, Koki Nagano, Jan Kautz, Umar Iqbal
0
0
Gaussian splatting has emerged as a powerful 3D representation that harnesses the advantages of both explicit (mesh) and implicit (NeRF) 3D representations. In this paper, we seek to leverage Gaussian splatting to generate realistic animatable avatars from textual descriptions, addressing the limitations (e.g., flexibility and efficiency) imposed by mesh or NeRF-based representations. However, a naive application of Gaussian splatting cannot generate high-quality animatable avatars and suffers from learning instability; it also cannot capture fine avatar geometries and often leads to degenerate body parts. To tackle these problems, we first propose a primitive-based 3D Gaussian representation where Gaussians are defined inside pose-driven primitives to facilitate animation. Second, to stabilize and amortize the learning of millions of Gaussians, we propose to use neural implicit fields to predict the Gaussian attributes (e.g., colors). Finally, to capture fine avatar geometries and extract detailed meshes, we propose a novel SDF-based implicit mesh learning approach for 3D Gaussians that regularizes the underlying geometries and extracts highly detailed textured meshes. Our proposed method, GAvatar, enables the large-scale generation of diverse animatable avatars using only text prompts. GAvatar significantly surpasses existing methods in terms of both appearance and geometry quality, and achieves extremely fast rendering (100 fps) at 1K resolution.
4/1/2024
3DGS-Avatar: Animatable Avatars via Deformable 3D Gaussian Splatting
Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, Siyu Tang
0
0
We introduce an approach that creates animatable human avatars from monocular videos using 3D Gaussian Splatting (3DGS). Existing methods based on neural radiance fields (NeRFs) achieve high-quality novel-view/novel-pose image synthesis but often require days of training, and are extremely slow at inference time. Recently, the community has explored fast grid structures for efficient training of clothed avatars. Albeit being extremely fast at training, these methods can barely achieve an interactive rendering frame rate with around 15 FPS. In this paper, we use 3D Gaussian Splatting and learn a non-rigid deformation network to reconstruct animatable clothed human avatars that can be trained within 30 minutes and rendered at real-time frame rates (50+ FPS). Given the explicit nature of our representation, we further introduce as-isometric-as-possible regularizations on both the Gaussian mean vectors and the covariance matrices, enhancing the generalization of our model on highly articulated unseen poses. Experimental results show that our method achieves comparable and even better performance compared to state-of-the-art approaches on animatable avatar creation from a monocular input, while being 400x and 250x faster in training and inference, respectively.
4/5/2024
🤿
3D Gaussian Blendshapes for Head Avatar Animation
Shengjie Ma, Yanlin Weng, Tianjia Shao, Kun Zhou
0
0
We introduce 3D Gaussian blendshapes for modeling photorealistic head avatars. Taking a monocular video as input, we learn a base head model of neutral expression, along with a group of expression blendshapes, each of which corresponds to a basis expression in classical parametric face models. Both the neutral model and expression blendshapes are represented as 3D Gaussians, which contain a few properties to depict the avatar appearance. The avatar model of an arbitrary expression can be effectively generated by combining the neutral model and expression blendshapes through linear blending of Gaussians with the expression coefficients. High-fidelity head avatar animations can be synthesized in real time using Gaussian splatting. Compared to state-of-the-art methods, our Gaussian blendshape representation better captures high-frequency details exhibited in input video, and achieves superior rendering performance.
5/3/2024