3D Scene Generation from Scene Graphs and Self-Attention

0
🛸
Sign in to get full access
Overview
- Researchers present a method to generate realistic and diverse 3D indoor scenes from scene graphs and floor plans.
- Scene graphs, which capture the semantic relationships between objects, are used to provide control over the generated layouts.
- The proposed model leverages graph transformers and self-attention layers to estimate the size, dimensions, and orientation of objects while satisfying the constraints in the scene graph.
- The researchers publish a large-scale dataset of over XXX rooms with associated floor plans and scene graphs.
Plain English Explanation
Imagine you're designing a virtual world - a 3D environment that people can explore, like in a video game or virtual reality. Creating these virtual spaces from scratch can be a lot of work. This research proposes a way to automatically generate realistic and varied 3D indoor scenes, using high-level information about the scene as a guide.
The key idea is to use a "scene graph" - a diagram that shows the different objects in a room and how they're related to each other. For example, a scene graph might show that there's a table, with a chair next to it, and a lamp on top of the table. By providing this kind of semantic information, the researchers' model can generate a 3D scene that matches the relationships in the scene graph, while also figuring out the appropriate size, shape, and orientation of each object.
The model uses a technique called "graph transformers" and "self-attention" to capture the high-level structure of the scene and use that to guide the generation process. This allows it to create a diverse range of plausible 3D layouts, rather than just generating the same scene over and over.
In addition to the new model, the researchers also publish a large dataset of 3D indoor scenes, complete with the corresponding scene graphs and floor plans. This resource can help other researchers work on similar problems in virtual environment generation.
Technical Explanation
The core of this work is a variant of the conditional variational autoencoder (cVAE) model, which is used to synthesize 3D indoor scenes from scene graphs and floor plans. The researchers leverage the properties of self-attention layers to capture the high-level relationships between objects in a scene, using these as the building blocks of their model.
Specifically, the model uses graph transformers to estimate the size, dimensions, and orientation of objects in a room, while ensuring that the generated layout satisfies the constraints specified in the input scene graph. This allows the model to produce diverse and plausible 3D scenes, rather than just replicating the same layouts.
The researchers' experiments show that the use of self-attention layers leads to sparser (X% fewer objects) and more diverse scenes (X% increase in diversity) compared to a baseline model. This indicates that the proposed approach is effective at capturing the underlying structure of the scene and using that to guide the generation process.
Critical Analysis
The researchers acknowledge that their model is limited to generating single-room layouts, and more work would be needed to scale it up to entire buildings or multi-room environments. Additionally, the quality of the generated scenes is still somewhat variable, and there may be opportunities to further improve the realism and coherence of the outputs.
One potential area for further research could be exploring ways to incorporate additional information, such as functional relationships between objects or semantic constraints, to further enhance the controllability and plausibility of the generated scenes. It would also be interesting to see how this approach could be adapted to other types of virtual environments, such as outdoor spaces or industrial settings.
Overall, this work represents a promising step forward in the field of data-driven 3D scene generation, with the potential to enable more efficient and realistic virtual environment creation for a variety of applications.
Conclusion
This research presents a novel approach to generating realistic and diverse 3D indoor scenes from high-level scene graphs and floor plans. By leveraging graph transformers and self-attention layers, the proposed model is able to capture the semantic relationships between objects and use that knowledge to produce varied and plausible layouts.
The publication of a large-scale dataset of 3D scenes, floor plans, and scene graphs is also a valuable contribution, as it provides a resource for other researchers working on similar problems. Overall, this work represents an important advancement in the field of data-driven 3D scene synthesis, with potential applications in areas like simulated navigation, virtual reality, and architectural design.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
3D Scene Generation from Scene Graphs and Self-Attention
Pietro Bonazzi
Synthesizing realistic and diverse indoor 3D scene layouts in a controllable fashion opens up applications in simulated navigation and virtual reality. As concise and robust representations of a scene, scene graphs have proven to be well-suited as the semantic control on the generated layout. We present a variant of the conditional variational autoencoder (cVAE) model to synthesize 3D scenes from scene graphs and floor plans. We exploit the properties of self-attention layers to capture high-level relationships between objects in a scene, and use these as the building blocks of our model. Our model, leverages graph transformers to estimate the size, dimension and orientation of the objects in a room while satisfying relationships in the given scene graph. Our experiments shows self-attention layers leads to sparser (7.9x compared to Graphto3D) and more diverse scenes (16%).
Read more4/8/2024

0
Planner3D: LLM-enhanced graph prior meets 3D indoor scene explicit regularization
Yao Wei, Martin Renqiang Min, George Vosselman, Li Erran Li, Michael Ying Yang
Compositional 3D scene synthesis has diverse applications across a spectrum of industries such as robotics, films, and video games, as it closely mirrors the complexity of real-world multi-object environments. Conventional works typically employ shape retrieval based frameworks which naturally suffer from limited shape diversity. Recent progresses have been made in object shape generation with generative models such as diffusion models, which increases the shape fidelity. However, these approaches separately treat 3D shape generation and layout generation. The synthesized scenes are usually hampered by layout collision, which suggests that the scene-level fidelity is still under-explored. In this paper, we aim at generating realistic and reasonable 3D indoor scenes from scene graph. To enrich the priors of the given scene graph inputs, large language model is utilized to aggregate the global-wise features with local node-wise and edge-wise features. With a unified graph encoder, graph features are extracted to guide joint layout-shape generation. Additional regularization is introduced to explicitly constrain the produced 3D layouts. Benchmarked on the SG-FRONT dataset, our method achieves better 3D scene synthesis, especially in terms of scene-level fidelity. The source code will be released after publication.
Read more8/27/2024
✅
0
GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs
Gege Gao, Weiyang Liu, Anpei Chen, Andreas Geiger, Bernhard Scholkopf
As pretrained text-to-image diffusion models become increasingly powerful, recent efforts have been made to distill knowledge from these text-to-image pretrained models for optimizing a text-guided 3D model. Most of the existing methods generate a holistic 3D model from a plain text input. This can be problematic when the text describes a complex scene with multiple objects, because the vectorized text embeddings are inherently unable to capture a complex description with multiple entities and relationships. Holistic 3D modeling of the entire scene further prevents accurate grounding of text entities and concepts. To address this limitation, we propose GraphDreamer, a novel framework to generate compositional 3D scenes from scene graphs, where objects are represented as nodes and their interactions as edges. By exploiting node and edge information in scene graphs, our method makes better use of the pretrained text-to-image diffusion model and is able to fully disentangle different objects without image-level supervision. To facilitate modeling of object-wise relationships, we use signed distance fields as representation and impose a constraint to avoid inter-penetration of objects. To avoid manual scene graph creation, we design a text prompt for ChatGPT to generate scene graphs based on text inputs. We conduct both qualitative and quantitative experiments to validate the effectiveness of GraphDreamer in generating high-fidelity compositional 3D scenes with disentangled object entities.
Read more6/12/2024
0
Weakly-Supervised 3D Scene Graph Generation via Visual-Linguistic Assisted Pseudo-labeling
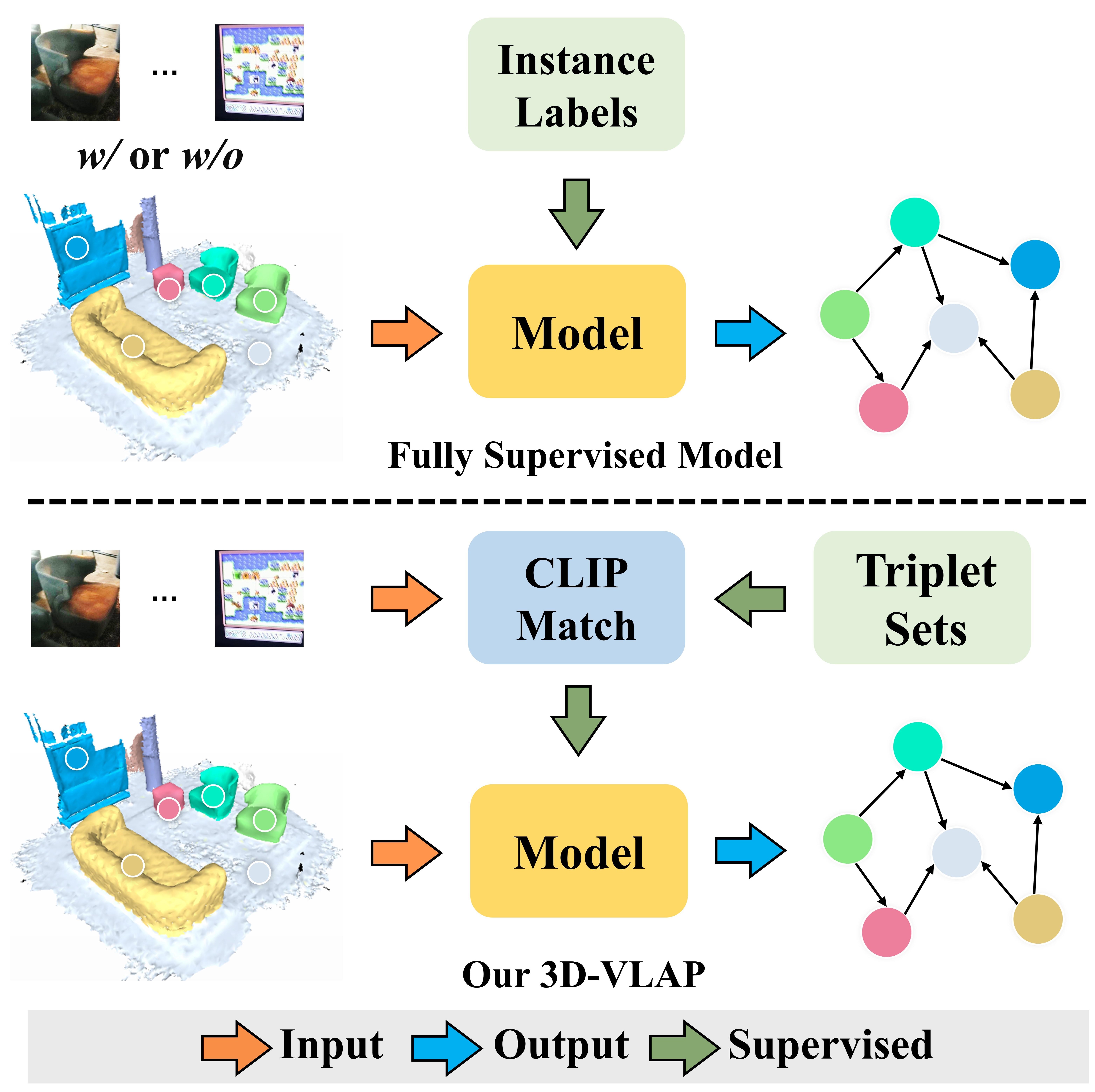
Xu Wang, Yifan Li, Qiudan Zhang, Wenhui Wu, Mark Junjie Li, Jianmin Jinag
Learning to build 3D scene graphs is essential for real-world perception in a structured and rich fashion. However, previous 3D scene graph generation methods utilize a fully supervised learning manner and require a large amount of entity-level annotation data of objects and relations, which is extremely resource-consuming and tedious to obtain. To tackle this problem, we propose 3D-VLAP, a weakly-supervised 3D scene graph generation method via Visual-Linguistic Assisted Pseudo-labeling. Specifically, our 3D-VLAP exploits the superior ability of current large-scale visual-linguistic models to align the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds. First, we establish the positional correspondence from 3D point clouds to 2D images via camera intrinsic and extrinsic parameters, thereby achieving alignment of 3D point clouds and 2D images. Subsequently, a large-scale cross-modal visual-linguistic model is employed to indirectly align 3D instances with the textual category labels of objects by matching 2D images with object category labels. The pseudo labels for objects and relations are then produced for 3D-VLAP model training by calculating the similarity between visual embeddings and textual category embeddings of objects and relations encoded by the visual-linguistic model, respectively. Ultimately, we design an edge self-attention based graph neural network to generate scene graphs of 3D point cloud scenes. Extensive experiments demonstrate that our 3D-VLAP achieves comparable results with current advanced fully supervised methods, meanwhile significantly alleviating the pressure of data annotation.
Read more4/4/2024