Weakly-Supervised 3D Scene Graph Generation via Visual-Linguistic Assisted Pseudo-labeling
2404.02527
0
0
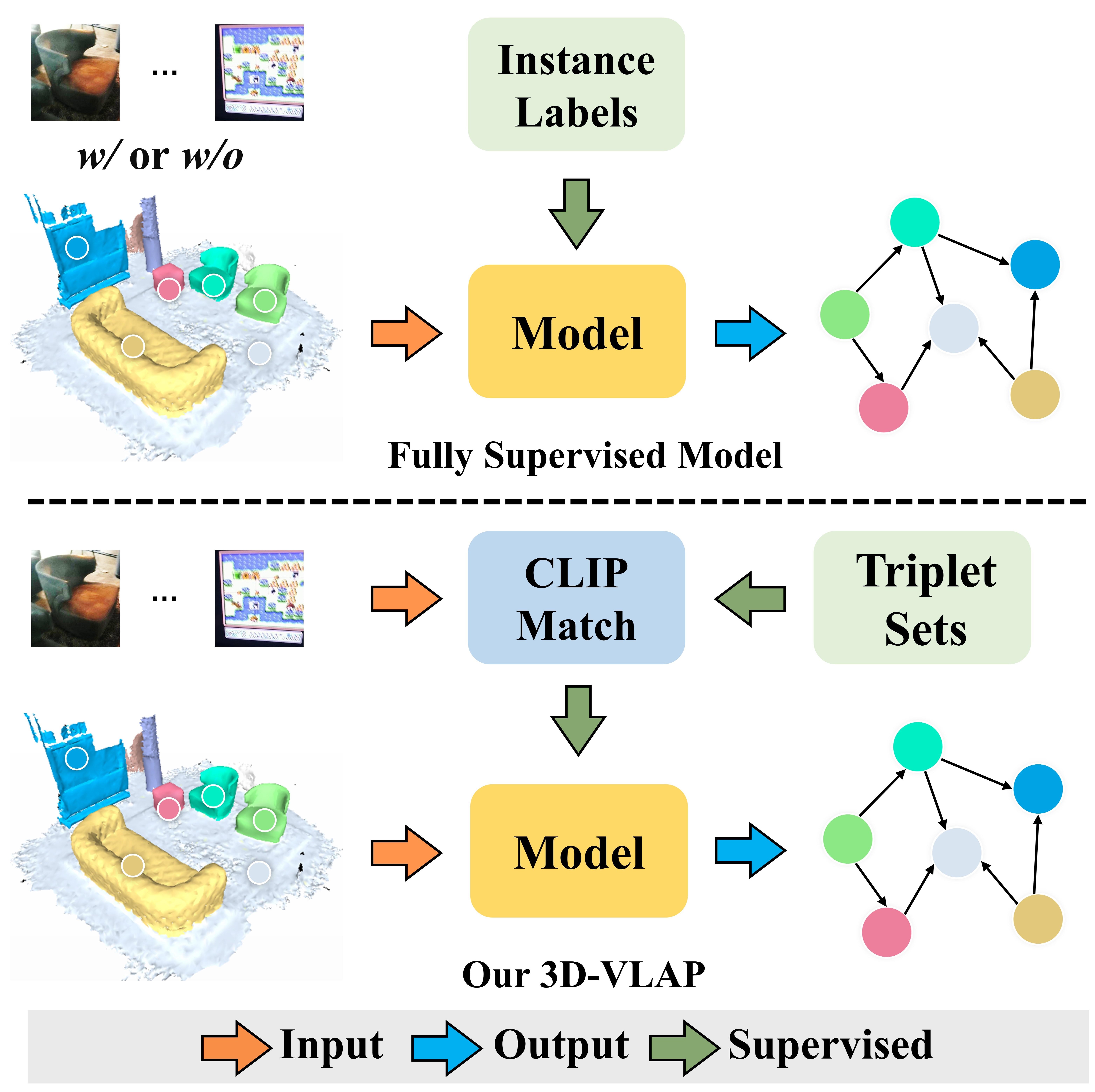
Abstract
Learning to build 3D scene graphs is essential for real-world perception in a structured and rich fashion. However, previous 3D scene graph generation methods utilize a fully supervised learning manner and require a large amount of entity-level annotation data of objects and relations, which is extremely resource-consuming and tedious to obtain. To tackle this problem, we propose 3D-VLAP, a weakly-supervised 3D scene graph generation method via Visual-Linguistic Assisted Pseudo-labeling. Specifically, our 3D-VLAP exploits the superior ability of current large-scale visual-linguistic models to align the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds. First, we establish the positional correspondence from 3D point clouds to 2D images via camera intrinsic and extrinsic parameters, thereby achieving alignment of 3D point clouds and 2D images. Subsequently, a large-scale cross-modal visual-linguistic model is employed to indirectly align 3D instances with the textual category labels of objects by matching 2D images with object category labels. The pseudo labels for objects and relations are then produced for 3D-VLAP model training by calculating the similarity between visual embeddings and textual category embeddings of objects and relations encoded by the visual-linguistic model, respectively. Ultimately, we design an edge self-attention based graph neural network to generate scene graphs of 3D point cloud scenes. Extensive experiments demonstrate that our 3D-VLAP achieves comparable results with current advanced fully supervised methods, meanwhile significantly alleviating the pressure of data annotation.
Create account to get full access
Overview
- This paper proposes a weakly-supervised approach for generating 3D scene graphs from visual and linguistic data.
- The key idea is to leverage language models to generate pseudo-labels for 3D object relationships, which are then used to train a 3D scene graph generation model.
- The authors demonstrate that this visual-linguistic assisted approach can outperform fully-supervised baselines on benchmark 3D scene graph datasets.
Plain English Explanation
The paper tackles the challenge of creating detailed 3D scene graphs from visual data alone. A 3D scene graph is a structured representation of the objects in a 3D scene and how they are related to each other. This type of information is valuable for applications like robotic navigation, virtual reality, and image understanding.
Traditionally, building these 3D scene graphs requires lots of manual labeling - annotating every object and its relationships. The authors propose a clever way to get around this need for extensive human labeling. They use language models that have been trained on vast amounts of text data to automatically generate "pseudo-labels" for the object relationships in 3D scenes.
The key insight is that language models can pick up on common sense relationships between objects, even if they haven't seen those specific 3D object configurations before. For example, a language model might know that a "cup" is likely to be "on" a "table", even if it hasn't seen that exact 3D scene. The authors leverage this linguistic knowledge to bootstrap the training of their 3D scene graph generation model, avoiding the need for full manual labeling.
In experiments, this weakly-supervised approach using pseudo-labels outperformed fully-supervised baselines that required exhaustive human labeling. This demonstrates the power of combining visual and linguistic information to tackle challenging 3D scene understanding tasks.
Technical Explanation
The proposed approach consists of two main components:
-
Pseudo-Label Generation: The authors leverage large pre-trained language models, like BERT, to generate pseudo-labels for object relationships in 3D scenes. Given a 3D scene with detected objects, the language model is used to infer the likely relationships between those objects (e.g. "cup on table", "person next to chair"). These pseudo-labels are then used as training targets.
-
Scene Graph Generation Model: The authors train a neural network model to predict the 3D scene graph directly from the input 3D scene. This model is trained using the pseudo-labels generated in the first step, rather than requiring fully-supervised human annotations.
Key architectural choices include using a graph neural network backbone to capture the relational structure, along with attention mechanisms to reason about object interactions. The model is trained end-to-end in a weakly-supervised fashion.
The authors evaluate their approach on benchmark 3D scene graph datasets, demonstrating significant performance improvements over fully-supervised baselines. This highlights the power of leveraging linguistic knowledge to reduce the need for expensive 3D annotation.
Critical Analysis
The authors acknowledge that their pseudo-labeling approach has limitations - the language model may not always accurately capture the true object relationships in a 3D scene. There could be cases where the linguistic knowledge doesn't align well with the visual reality.
Additionally, the paper does not deeply explore the biases or failures modes of the language model when generating pseudo-labels. It would be valuable to understand when and why the linguistic knowledge breaks down, so the community can work to address those shortcomings.
That said, the core idea of using language as a source of weak supervision for 3D scene understanding is quite clever and the experimental results are compelling. This work demonstrates the promise of combining visual and linguistic data to tackle challenging perception tasks.
Future research could explore ways to better align the language model's knowledge with the visual scene, perhaps through iterative refinement or deeper integration between the visual and language components.
Conclusion
This paper presents an innovative weakly-supervised approach for 3D scene graph generation that leverages linguistic knowledge to reduce the need for expensive 3D annotation. By using language models to generate pseudo-labels for object relationships, the authors are able to train an effective 3D scene graph prediction model without full human supervision.
The results show the power of combining visual and linguistic data sources to tackle complex 3D understanding problems. This work represents an important step towards more practical and scalable 3D scene understanding, with applications in robotics, AR/VR, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Weakly-Supervised 3D Visual Grounding based on Visual Linguistic Alignment
Xiaoxu Xu, Yitian Yuan, Qiudan Zhang, Wenhui Wu, Zequn Jie, Lin Ma, Xu Wang
0
0
Learning to ground natural language queries to target objects or regions in 3D point clouds is quite essential for 3D scene understanding. Nevertheless, existing 3D visual grounding approaches require a substantial number of bounding box annotations for text queries, which is time-consuming and labor-intensive to obtain. In this paper, we propose textbf{3D-VLA}, a weakly supervised approach for textbf{3D} visual grounding based on textbf{V}isual textbf{L}inguistic textbf{A}lignment. Our 3D-VLA exploits the superior ability of current large-scale vision-language models (VLMs) on aligning the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds with no need for fine-grained box annotations in the training procedure. During the inference stage, the learned text-3D correspondence will help us ground the text queries to the 3D target objects even without 2D images. To the best of our knowledge, this is the first work to investigate 3D visual grounding in a weakly supervised manner by involving large scale vision-language models, and extensive experiments on ReferIt3D and ScanRefer datasets demonstrate that our 3D-VLA achieves comparable and even superior results over the fully supervised methods.
4/16/2024

Weakly Supervised 3D Object Detection via Multi-Level Visual Guidance
Kuan-Chih Huang, Yi-Hsuan Tsai, Ming-Hsuan Yang
0
0
Weakly supervised 3D object detection aims to learn a 3D detector with lower annotation cost, e.g., 2D labels. Unlike prior work which still relies on few accurate 3D annotations, we propose a framework to study how to leverage constraints between 2D and 3D domains without requiring any 3D labels. Specifically, we employ visual data from three perspectives to establish connections between 2D and 3D domains. First, we design a feature-level constraint to align LiDAR and image features based on object-aware regions. Second, the output-level constraint is developed to enforce the overlap between 2D and projected 3D box estimations. Finally, the training-level constraint is utilized by producing accurate and consistent 3D pseudo-labels that align with the visual data. We conduct extensive experiments on the KITTI dataset to validate the effectiveness of the proposed three constraints. Without using any 3D labels, our method achieves favorable performance against state-of-the-art approaches and is competitive with the method that uses 500-frame 3D annotations. Code and models will be made publicly available at https://github.com/kuanchihhuang/VG-W3D.
4/24/2024
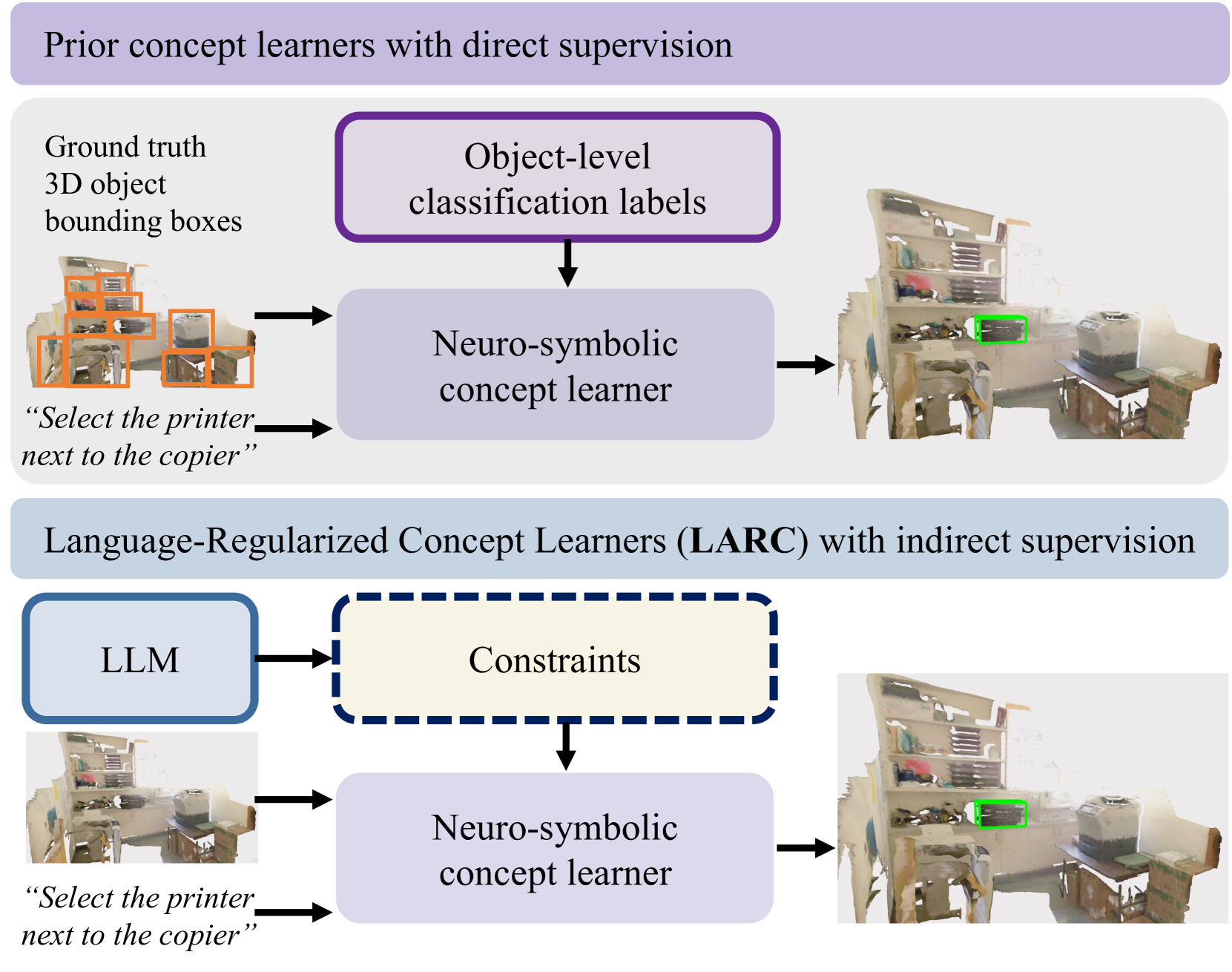
Naturally Supervised 3D Visual Grounding with Language-Regularized Concept Learners
Chun Feng, Joy Hsu, Weiyu Liu, Jiajun Wu
0
0
3D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. Our approach is based on two core insights: the first is that language constraints (e.g., a word's relation to another) can serve as effective regularization for structured representations in neuro-symbolic models; the second is that we can query large language models to distill such constraints from language properties. We show that LARC improves performance of prior works in naturally supervised 3D visual grounding, and demonstrates a wide range of 3D visual reasoning capabilities-from zero-shot composition, to data efficiency and transferability. Our method represents a promising step towards regularizing structured visual reasoning frameworks with language-based priors, for learning in settings without dense supervision.
5/1/2024
🌀
LASER: A Neuro-Symbolic Framework for Learning Spatial-Temporal Scene Graphs with Weak Supervision
Jiani Huang, Ziyang Li, Mayur Naik, Ser-Nam Lim
0
0
We propose LASER, a neuro-symbolic approach to learn semantic video representations that capture rich spatial and temporal properties in video data by leveraging high-level logic specifications. In particular, we formulate the problem in terms of alignment between raw videos and spatio-temporal logic specifications. The alignment algorithm leverages a differentiable symbolic reasoner and a combination of contrastive, temporal, and semantics losses. It effectively and efficiently trains low-level perception models to extract a fine-grained video representation in the form of a spatio-temporal scene graph that conforms to the desired high-level specification. To practically reduce the manual effort of obtaining ground truth labels, we derive logic specifications from captions by employing a large language model with a generic prompting template. In doing so, we explore a novel methodology that weakly supervises the learning of spatio-temporal scene graphs with widely accessible video-caption data. We evaluate our method on three datasets with rich spatial and temporal specifications: 20BN-Something-Something, MUGEN, and OpenPVSG. We demonstrate that our method learns better fine-grained video semantics than existing baselines.
6/13/2024