3D Open-Vocabulary Panoptic Segmentation with 2D-3D Vision-Language Distillation
2401.02402
0
0
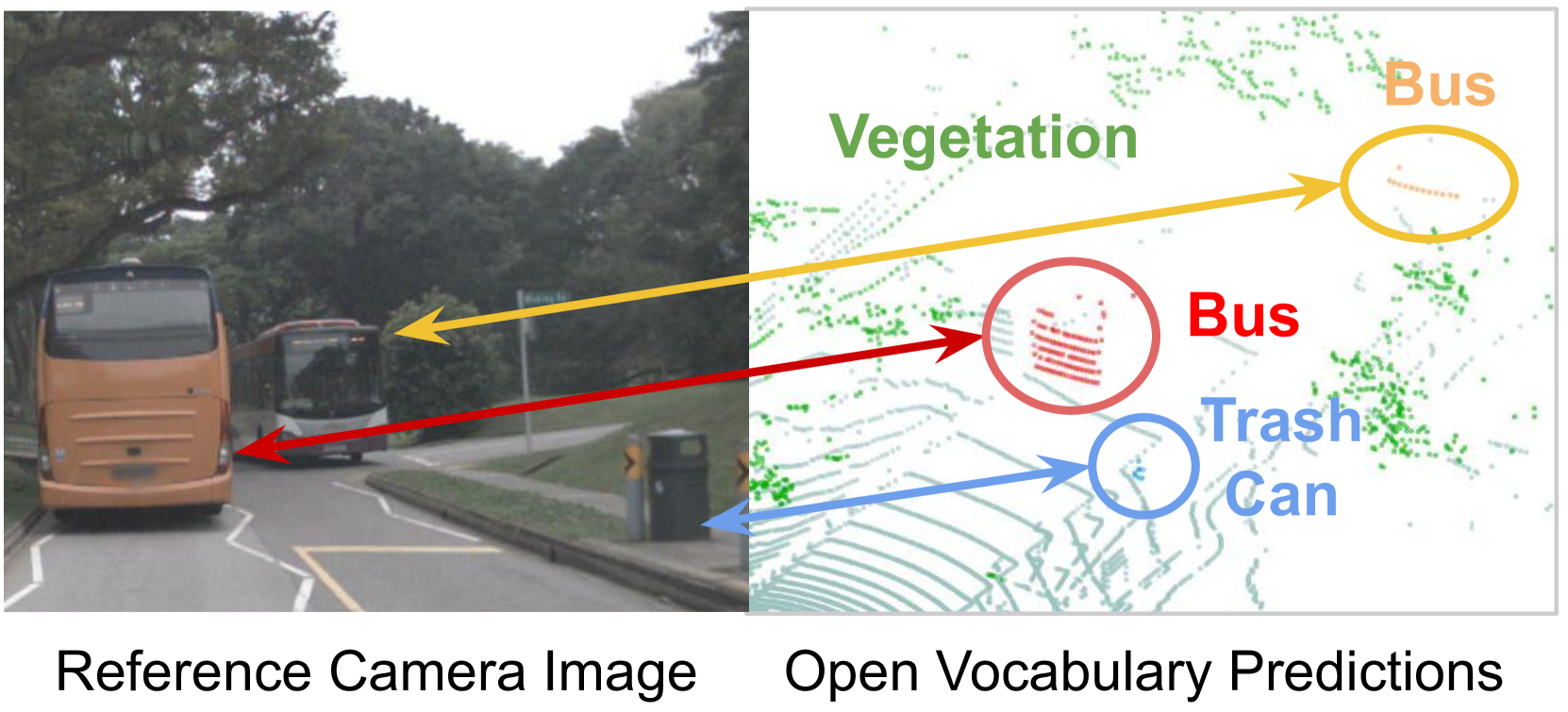
Abstract
3D panoptic segmentation is a challenging perception task, especially in autonomous driving. It aims to predict both semantic and instance annotations for 3D points in a scene. Although prior 3D panoptic segmentation approaches have achieved great performance on closed-set benchmarks, generalizing these approaches to unseen things and unseen stuff categories remains an open problem. For unseen object categories, 2D open-vocabulary segmentation has achieved promising results that solely rely on frozen CLIP backbones and ensembling multiple classification outputs. However, we find that simply extending these 2D models to 3D does not guarantee good performance due to poor per-mask classification quality, especially for novel stuff categories. In this paper, we propose the first method to tackle 3D open-vocabulary panoptic segmentation. Our model takes advantage of the fusion between learnable LiDAR features and dense frozen vision CLIP features, using a single classification head to make predictions for both base and novel classes. To further improve the classification performance on novel classes and leverage the CLIP model, we propose two novel loss functions: object-level distillation loss and voxel-level distillation loss. Our experiments on the nuScenes and SemanticKITTI datasets show that our method outperforms the strong baseline by a large margin.
Create account to get full access
Overview
- Presents a novel approach for 3D open-vocabulary panoptic segmentation, combining 2D and 3D vision-language models
- Introduces a 2D-3D vision-language distillation technique to bridge the gap between 2D and 3D segmentation
- Demonstrates state-of-the-art performance on various 3D panoptic segmentation benchmarks
Plain English Explanation
This research paper introduces a new method for 3D object segmentation that can identify and outline objects in 3D scenes based on their descriptions in natural language. The key innovation is a technique called "2D-3D vision-language distillation" that allows the system to effectively transfer knowledge from 2D image-based models to 3D point cloud-based models.
The researchers developed a model that can take a 3D scene and a text description of the objects in that scene, and then accurately segment and label each object, even if the objects are novel and not part of the model's original training data. This is a significant advance over previous 3D segmentation methods, which were limited to a fixed set of known object categories.
By bridging the gap between 2D and 3D perception using vision-language distillation, the model is able to leverage the vast amounts of existing 2D image data and language descriptions to improve its 3D understanding. This allows it to recognize and segment a much wider range of objects compared to prior 3D-only approaches.
The researchers demonstrate that their method achieves state-of-the-art performance on several 3D panoptic segmentation benchmarks, where it outperforms other leading techniques. This advance in 3D scene understanding could have important applications in areas like robotics, augmented reality, and autonomous driving, where detailed 3D perception is crucial.
Technical Explanation
The paper presents a novel approach for 3D open-vocabulary panoptic segmentation that combines 2D and 3D vision-language models. At the core of their method is a 2D-3D vision-language distillation technique that bridges the gap between 2D image-based and 3D point cloud-based segmentation.
The model takes as input a 3D point cloud scene and a set of natural language descriptions of the objects present. It then outputs a panoptic segmentation of the scene, where each 3D object instance is both segmented and classified, even for novel object categories not seen during training.
This is achieved by leveraging a 2D vision-language model to guide the 3D segmentation process. The 2D model is first trained on large-scale 2D image-text datasets, then its learned representations are distilled into the 3D model using a novel distillation objective.
The 3D model architecture builds on recent advances in 3D scene understanding, using a multi-task design that jointly predicts instance segmentation, semantic segmentation, and object classification. The 2D-3D distillation allows the 3D model to leverage the rich 2D-language knowledge to improve its 3D understanding.
Extensive experiments on several 3D panoptic segmentation benchmarks demonstrate the effectiveness of the proposed approach, achieving state-of-the-art results. This advance in 3D scene perception could enable new capabilities in areas like robotics, augmented reality, and autonomous driving.
Critical Analysis
The paper presents a compelling approach to 3D open-vocabulary panoptic segmentation, with several notable strengths. The key innovation of 2D-3D vision-language distillation is a clever way to bridge the gap between 2D and 3D perception, leveraging the vast amounts of existing 2D image-text data to improve 3D understanding.
However, the authors acknowledge several limitations and areas for future work. For example, the distillation process relies on having access to well-aligned 2D-3D training data, which may not always be available. Additionally, the current model is limited to static 3D scenes, whereas many real-world applications would require reasoning about dynamic, changing environments.
Further research could explore ways to make the distillation process more robust to noisy or incomplete 2D-3D alignment, as well as extending the approach to handle temporal information and enable 3D scene understanding in more realistic settings. Exploring the model's generalization to novel object categories and real-world deployment scenarios would also be valuable.
Overall, this paper represents an important step forward in 3D scene understanding, with the potential to enable new capabilities in various AI-powered applications. By thoughtfully combining 2D and 3D vision-language models, the researchers have developed a powerful tool for detailed 3D perception that could have far-reaching impacts.
Conclusion
This research paper presents a novel approach for 3D open-vocabulary panoptic segmentation that leverages 2D-3D vision-language distillation to achieve state-of-the-art performance. The key innovation is a technique that allows the model to effectively transfer knowledge from 2D image-based perception to 3D point cloud-based segmentation, enabling it to recognize and outline a much broader range of objects than previous 3D-only methods.
The demonstrated advancements in 3D scene understanding could have significant implications for fields like robotics, augmented reality, and autonomous driving, where detailed 3D perception is crucial. While the current approach has some limitations, the paper highlights promising directions for future research to further improve the robustness and real-world applicability of these techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
Depth-aware Panoptic Segmentation
Tuan Nguyen, Max Mehltretter, Franz Rottensteiner
0
0
Panoptic segmentation unifies semantic and instance segmentation and thus delivers a semantic class label and, for so-called thing classes, also an instance label per pixel. The differentiation of distinct objects of the same class with a similar appearance is particularly challenging and frequently causes such objects to be incorrectly assigned to a single instance. In the present work, we demonstrate that information on the 3D geometry of the observed scene can be used to mitigate this issue: We present a novel CNN-based method for panoptic segmentation which processes RGB images and depth maps given as input in separate network branches and fuses the resulting feature maps in a late fusion manner. Moreover, we propose a new depth-aware dice loss term which penalises the assignment of pixels to the same thing instance based on the difference between their associated distances to the camera. Experiments carried out on the Cityscapes dataset show that the proposed method reduces the number of objects that are erroneously merged into one thing instance and outperforms the method used as basis by 2.2% in terms of panoptic quality.
5/21/2024
Open-YOLO 3D: Towards Fast and Accurate Open-Vocabulary 3D Instance Segmentation
Mohamed El Amine Boudjoghra, Angela Dai, Jean Lahoud, Hisham Cholakkal, Rao Muhammad Anwer, Salman Khan, Fahad Shahbaz Khan
0
0
Recent works on open-vocabulary 3D instance segmentation show strong promise, but at the cost of slow inference speed and high computation requirements. This high computation cost is typically due to their heavy reliance on 3D clip features, which require computationally expensive 2D foundation models like Segment Anything (SAM) and CLIP for multi-view aggregation into 3D. As a consequence, this hampers their applicability in many real-world applications that require both fast and accurate predictions. To this end, we propose a fast yet accurate open-vocabulary 3D instance segmentation approach, named Open-YOLO 3D, that effectively leverages only 2D object detection from multi-view RGB images for open-vocabulary 3D instance segmentation. We address this task by generating class-agnostic 3D masks for objects in the scene and associating them with text prompts. We observe that the projection of class-agnostic 3D point cloud instances already holds instance information; thus, using SAM might only result in redundancy that unnecessarily increases the inference time. We empirically find that a better performance of matching text prompts to 3D masks can be achieved in a faster fashion with a 2D object detector. We validate our Open-YOLO 3D on two benchmarks, ScanNet200 and Replica, under two scenarios: (i) with ground truth masks, where labels are required for given object proposals, and (ii) with class-agnostic 3D proposals generated from a 3D proposal network. Our Open-YOLO 3D achieves state-of-the-art performance on both datasets while obtaining up to $sim$16$times$ speedup compared to the best existing method in literature. On ScanNet200 val. set, our Open-YOLO 3D achieves mean average precision (mAP) of 24.7% while operating at 22 seconds per scene. Code and model are available at github.com/aminebdj/OpenYOLO3D.
6/21/2024

3D Unsupervised Learning by Distilling 2D Open-Vocabulary Segmentation Models for Autonomous Driving
Boyi Sun, Yuhang Liu, Xingxia Wang, Bin Tian, Long Chen, Fei-Yue Wang
0
0
Point cloud data labeling is considered a time-consuming and expensive task in autonomous driving, whereas unsupervised learning can avoid it by learning point cloud representations from unannotated data. In this paper, we propose UOV, a novel 3D Unsupervised framework assisted by 2D Open-Vocabulary segmentation models. It consists of two stages: In the first stage, we innovatively integrate high-quality textual and image features of 2D open-vocabulary models and propose the Tri-Modal contrastive Pre-training (TMP). In the second stage, spatial mapping between point clouds and images is utilized to generate pseudo-labels, enabling cross-modal knowledge distillation. Besides, we introduce the Approximate Flat Interaction (AFI) to address the noise during alignment and label confusion. To validate the superiority of UOV, extensive experiments are conducted on multiple related datasets. We achieved a record-breaking 47.73% mIoU on the annotation-free point cloud segmentation task in nuScenes, surpassing the previous best model by 10.70% mIoU. Meanwhile, the performance of fine-tuning with 1% data on nuScenes and SemanticKITTI reached a remarkable 51.75% mIoU and 48.14% mIoU, outperforming all previous pre-trained models.
5/27/2024

Auto-Vocabulary Segmentation for LiDAR Points
Weijie Wei, Osman Ulger, Fatemeh Karimi Najadasl, Theo Gevers, Martin R. Oswald
0
0
Existing perception methods for autonomous driving fall short of recognizing unknown entities not covered in the training data. Open-vocabulary methods offer promising capabilities in detecting any object but are limited by user-specified queries representing target classes. We propose AutoVoc3D, a framework for automatic object class recognition and open-ended segmentation. Evaluation on nuScenes showcases AutoVoc3D's ability to generate precise semantic classes and accurate point-wise segmentation. Moreover, we introduce Text-Point Semantic Similarity, a new metric to assess the semantic similarity between text and point cloud without eliminating novel classes.
6/14/2024