3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors

0

Sign in to get full access
Overview
- This paper presents a large text-to-3D generation model called 3DTopia that uses a hybrid diffusion approach.
- The model aims to generate diverse and high-quality 3D content from textual descriptions.
- It leverages different diffusion priors, including a class-conditional prior and an object-centric prior, to improve the quality and diversity of the generated 3D shapes.
Plain English Explanation
The researchers have developed a new AI model called 3DTopia that can generate 3D objects based on text descriptions. This is a challenging task, as it requires the model to understand the meaning of the text and then create a corresponding 3D shape.
To improve the quality and variety of the generated 3D shapes, the 3DTopia model uses a technique called "diffusion priors." Diffusion models start with random noise and gradually refine it to create the desired output. The 3DTopia model uses two different types of diffusion priors - one based on the object's class (e.g., chair, table, car) and one that focuses on the individual components of the object (e.g., legs, seat, back for a chair).
By combining these two diffusion priors, the 3DTopia model is able to generate more realistic and diverse 3D shapes that match the input text descriptions. This could be useful for a variety of applications, such as creating 3D assets for video games, generating 3D models from product descriptions, or making 3D visualizations from text.
Technical Explanation
The 3DTopia model is based on a diffusion-based architecture, which has been shown to be effective for 3D generation tasks. The researchers incorporate two types of diffusion priors to improve the quality and diversity of the generated 3D shapes:
- Class-Conditional Prior: This prior encodes information about the category or class of the 3D object (e.g., chair, table, car) to guide the generation process.
- Object-Centric Prior: This prior focuses on the individual components or parts of the 3D object (e.g., legs, seat, back for a chair) to ensure that the generated shapes are structurally sound and coherent.
By combining these two diffusion priors, the 3DTopia model is able to generate 3D shapes that are not only visually appealing but also semantically meaningful and faithful to the input text descriptions.
The researchers evaluate the performance of 3DTopia on several benchmark datasets, including DreamTime and Grounded-3D, and demonstrate that it outperforms state-of-the-art text-to-3D generation models in terms of both qualitative and quantitative metrics.
Critical Analysis
The researchers have made a compelling case for the effectiveness of their 3DTopia model, but there are a few areas that could be explored further:
- Scalability: The model is trained on a large dataset, but it's unclear how well it would scale to even larger and more diverse datasets. Exploring the model's performance on broader and more comprehensive text-to-3D benchmarks could provide valuable insights.
- Practical Applications: While the researchers mention potential use cases, more detailed exploration of how 3DTopia could be deployed in real-world applications, such as creating 3D assets for video games or generating 3D models from product descriptions, would be helpful.
- Interpretability: The hybrid diffusion approach is powerful, but it could be beneficial to investigate the model's internal representations and understand how the different priors contribute to the final 3D shapes. This could lead to further improvements in the model's interpretability and explainability.
Overall, the 3DTopia model represents an exciting advancement in the field of text-to-3D generation, and the researchers have demonstrated a thoughtful and rigorous approach to this challenging problem.
Conclusion
The 3DTopia model presented in this paper is a significant step forward in the field of text-to-3D generation. By leveraging a hybrid diffusion approach with class-conditional and object-centric priors, the model is able to generate diverse and high-quality 3D shapes that are semantically meaningful and faithful to the input text descriptions.
The researchers have thoroughly evaluated the performance of 3DTopia and shown that it outperforms existing state-of-the-art models. While there are some areas for further exploration, such as scalability and practical applications, the 3DTopia model represents an important advancement that could have far-reaching implications for a variety of industries, from video game development to product design and visualization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors
Fangzhou Hong, Jiaxiang Tang, Ziang Cao, Min Shi, Tong Wu, Zhaoxi Chen, Shuai Yang, Tengfei Wang, Liang Pan, Dahua Lin, Ziwei Liu
We present a two-stage text-to-3D generation system, namely 3DTopia, which generates high-quality general 3D assets within 5 minutes using hybrid diffusion priors. The first stage samples from a 3D diffusion prior directly learned from 3D data. Specifically, it is powered by a text-conditioned tri-plane latent diffusion model, which quickly generates coarse 3D samples for fast prototyping. The second stage utilizes 2D diffusion priors to further refine the texture of coarse 3D models from the first stage. The refinement consists of both latent and pixel space optimization for high-quality texture generation. To facilitate the training of the proposed system, we clean and caption the largest open-source 3D dataset, Objaverse, by combining the power of vision language models and large language models. Experiment results are reported qualitatively and quantitatively to show the performance of the proposed system. Our codes and models are available at https://github.com/3DTopia/3DTopia
Read more5/8/2024
0
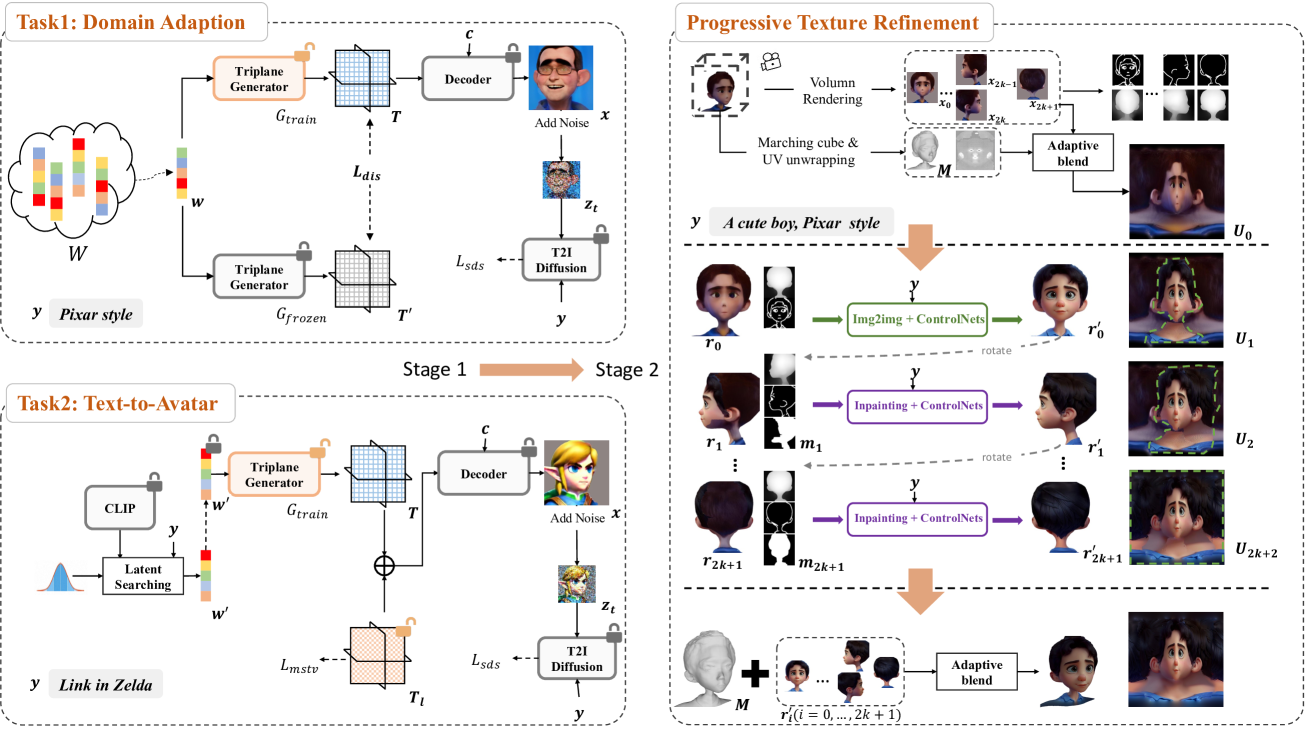
DiffusionGAN3D: Boosting Text-guided 3D Generation and Domain Adaptation by Combining 3D GANs and Diffusion Priors
Biwen Lei, Kai Yu, Mengyang Feng, Miaomiao Cui, Xuansong Xie
Text-guided domain adaptation and generation of 3D-aware portraits find many applications in various fields. However, due to the lack of training data and the challenges in handling the high variety of geometry and appearance, the existing methods for these tasks suffer from issues like inflexibility, instability, and low fidelity. In this paper, we propose a novel framework DiffusionGAN3D, which boosts text-guided 3D domain adaptation and generation by combining 3D GANs and diffusion priors. Specifically, we integrate the pre-trained 3D generative models (e.g., EG3D) and text-to-image diffusion models. The former provides a strong foundation for stable and high-quality avatar generation from text. And the diffusion models in turn offer powerful priors and guide the 3D generator finetuning with informative direction to achieve flexible and efficient text-guided domain adaptation. To enhance the diversity in domain adaptation and the generation capability in text-to-avatar, we introduce the relative distance loss and case-specific learnable triplane respectively. Besides, we design a progressive texture refinement module to improve the texture quality for both tasks above. Extensive experiments demonstrate that the proposed framework achieves excellent results in both domain adaptation and text-to-avatar tasks, outperforming existing methods in terms of generation quality and efficiency. The project homepage is at https://younglbw.github.io/DiffusionGAN3D-homepage/.
Read more4/15/2024
0
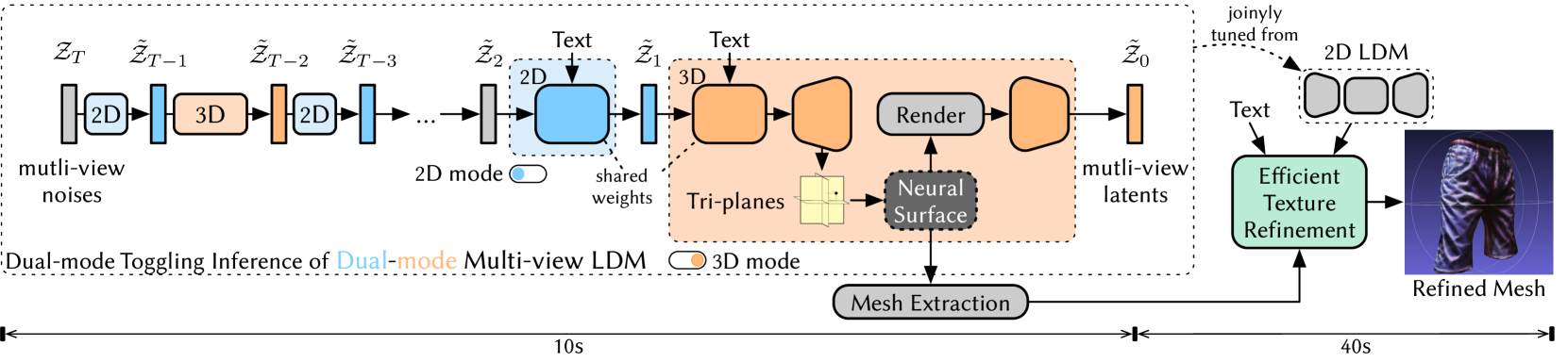
Dual3D: Efficient and Consistent Text-to-3D Generation with Dual-mode Multi-view Latent Diffusion
Xinyang Li, Zhangyu Lai, Linning Xu, Jianfei Guo, Liujuan Cao, Shengchuan Zhang, Bo Dai, Rongrong Ji
We present Dual3D, a novel text-to-3D generation framework that generates high-quality 3D assets from texts in only $1$ minute.The key component is a dual-mode multi-view latent diffusion model. Given the noisy multi-view latents, the 2D mode can efficiently denoise them with a single latent denoising network, while the 3D mode can generate a tri-plane neural surface for consistent rendering-based denoising. Most modules for both modes are tuned from a pre-trained text-to-image latent diffusion model to circumvent the expensive cost of training from scratch. To overcome the high rendering cost during inference, we propose the dual-mode toggling inference strategy to use only $1/10$ denoising steps with 3D mode, successfully generating a 3D asset in just $10$ seconds without sacrificing quality. The texture of the 3D asset can be further enhanced by our efficient texture refinement process in a short time. Extensive experiments demonstrate that our method delivers state-of-the-art performance while significantly reducing generation time. Our project page is available at https://dual3d.github.io
Read more5/17/2024

0
PI3D: Efficient Text-to-3D Generation with Pseudo-Image Diffusion
Ying-Tian Liu, Yuan-Chen Guo, Guan Luo, Heyi Sun, Wei Yin, Song-Hai Zhang
Diffusion models trained on large-scale text-image datasets have demonstrated a strong capability of controllable high-quality image generation from arbitrary text prompts. However, the generation quality and generalization ability of 3D diffusion models is hindered by the scarcity of high-quality and large-scale 3D datasets. In this paper, we present PI3D, a framework that fully leverages the pre-trained text-to-image diffusion models' ability to generate high-quality 3D shapes from text prompts in minutes. The core idea is to connect the 2D and 3D domains by representing a 3D shape as a set of Pseudo RGB Images. We fine-tune an existing text-to-image diffusion model to produce such pseudo-images using a small number of text-3D pairs. Surprisingly, we find that it can already generate meaningful and consistent 3D shapes given complex text descriptions. We further take the generated shapes as the starting point for a lightweight iterative refinement using score distillation sampling to achieve high-quality generation under a low budget. PI3D generates a single 3D shape from text in only 3 minutes and the quality is validated to outperform existing 3D generative models by a large margin.
Read more4/23/2024