4D ASR: Joint Beam Search Integrating CTC, Attention, Transducer, and Mask Predict Decoders
2406.02950
0
0
Abstract
End-to-end automatic speech recognition (E2E-ASR) can be classified into several network architectures, such as connectionist temporal classification (CTC), recurrent neural network transducer (RNN-T), attention-based encoder-decoder, and mask-predict models. Each network architecture has advantages and disadvantages, leading practitioners to switch between these different models depending on application requirements. Instead of building separate models, we propose a joint modeling scheme where four decoders (CTC, RNN-T, attention, and mask-predict) share the same encoder -- we refer to this as 4D modeling. The 4D model is trained using multitask learning, which will bring model regularization and maximize the model robustness thanks to their complementary properties. To efficiently train the 4D model, we introduce a two-stage training strategy that stabilizes multitask learning. In addition, we propose three novel one-pass beam search algorithms by combining three decoders (CTC, RNN-T, and attention) to further improve performance. These three beam search algorithms differ in which decoder is used as the primary decoder. We carefully evaluate the performance and computational tradeoffs associated with each algorithm. Experimental results demonstrate that the jointly trained 4D model outperforms the E2E-ASR models trained with only one individual decoder. Furthermore, we demonstrate that the proposed one-pass beam search algorithm outperforms the previously proposed CTC/attention decoding.
Create account to get full access
Overview
- This paper presents a sample article using the IEEEtran.cls class for IEEE journals and transactions.
- The paper covers the design, intent, and limitations of the templates provided by IEEEtran.cls.
- It also discusses the submission process for IEEE journals and transactions.
Plain English Explanation
The provided paper is a sample article that demonstrates how to use the IEEEtran.cls class, which is a set of templates and formatting rules for creating documents that meet the requirements of IEEE (Institute of Electrical and Electronics Engineers) journals and transactions. IEEE is a professional organization that publishes a wide range of technical journals and conference proceedings in the fields of engineering, computer science, and related disciplines.
The paper explains the purpose and features of the IEEEtran.cls class, which is designed to make it easier for authors to prepare their manuscripts in a format that is consistent with IEEE's style guidelines. This includes things like the layout of the title, author information, abstract, section headings, equations, figures, and references.
The paper also discusses the process of submitting an article to an IEEE journal or transaction, including any specific requirements or limitations that authors should be aware of. This can be helpful for researchers and engineers who are preparing to publish their work in an IEEE publication.
Technical Explanation
The paper provides a detailed overview of the IEEEtran.cls class, which is a LaTeX document class specifically designed for creating articles that meet the formatting and style requirements of IEEE journals and transactions. The class includes a variety of pre-defined commands and environments that handle the layout and formatting of the various elements of a journal article, such as the title, author information, abstract, section headings, equations, figures, and references.
The paper discusses the design goals and limitations of the IEEEtran.cls class, highlighting its flexibility in accommodating different types of content and the various options available for customizing the appearance of the document. It also covers the submission process for IEEE publications, including any specific requirements or constraints that authors should be aware of when preparing their manuscripts.
Critical Analysis
The paper provides a comprehensive overview of the IEEEtran.cls class and the process of submitting an article to an IEEE journal or transaction. However, it does not delve into the potential limitations or drawbacks of the class, such as its ability to handle more complex or unconventional document structures or its compatibility with other LaTeX packages and tools.
Additionally, the paper does not explore any potential challenges or issues that authors may face when using the IEEEtran.cls class, such as difficulties in maintaining consistent formatting across multiple sections or pages, or problems with the integration of external content such as images or data visualizations.
Researchers and engineers interested in publishing their work in IEEE publications may benefit from a more in-depth discussion of the practical considerations and potential pitfalls associated with using the IEEEtran.cls class, as well as any best practices or recommended workflows for ensuring a smooth and successful submission process.
Conclusion
The provided paper offers a detailed introduction to the IEEEtran.cls class, which is a valuable tool for authors preparing manuscripts for submission to IEEE journals and transactions. The paper covers the design, intent, and limitations of the class, as well as the submission process for IEEE publications.
While the paper provides a comprehensive overview, it could be enhanced with a more critical analysis of the class's capabilities and limitations, as well as a discussion of the practical considerations and potential challenges that authors may face when using the IEEEtran.cls class. This additional information could be particularly useful for researchers and engineers who are new to the IEEE publication process or are exploring alternative LaTeX-based solutions for preparing their manuscripts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Enhancing CTC-based speech recognition with diverse modeling units
Shiyi Han, Zhihong Lei, Mingbin Xu, Xingyu Na, Zhen Huang
0
0
In recent years, the evolution of end-to-end (E2E) automatic speech recognition (ASR) models has been remarkable, largely due to advances in deep learning architectures like transformer. On top of E2E systems, researchers have achieved substantial accuracy improvement by rescoring E2E model's N-best hypotheses with a phoneme-based model. This raises an interesting question about where the improvements come from other than the system combination effect. We examine the underlying mechanisms driving these gains and propose an efficient joint training approach, where E2E models are trained jointly with diverse modeling units. This methodology does not only align the strengths of both phoneme and grapheme-based models but also reveals that using these diverse modeling units in a synergistic way can significantly enhance model accuracy. Our findings offer new insights into the optimal integration of heterogeneous modeling units in the development of more robust and accurate ASR systems.
6/12/2024

Joint Optimization of Streaming and Non-Streaming Automatic Speech Recognition with Multi-Decoder and Knowledge Distillation
Muhammad Shakeel, Yui Sudo, Yifan Peng, Shinji Watanabe
0
0
End-to-end (E2E) automatic speech recognition (ASR) can operate in two modes: streaming and non-streaming, each with its pros and cons. Streaming ASR processes the speech frames in real-time as it is being received, while non-streaming ASR waits for the entire speech utterance; thus, professionals may have to operate in either mode to satisfy their application. In this work, we present joint optimization of streaming and non-streaming ASR based on multi-decoder and knowledge distillation. Primarily, we study 1) the encoder integration of these ASR modules, followed by 2) separate decoders to make the switching mode flexible, and enhancing performance by 3) incorporating similarity-preserving knowledge distillation between the two modular encoders and decoders. Evaluation results show 2.6%-5.3% relative character error rate reductions (CERR) on CSJ for streaming ASR, and 8.3%-9.7% relative CERRs for non-streaming ASR within a single model compared to multiple standalone modules.
5/24/2024

Decoder-only Architecture for Streaming End-to-end Speech Recognition
Emiru Tsunoo, Hayato Futami, Yosuke Kashiwagi, Siddhant Arora, Shinji Watanabe
0
0
Decoder-only language models (LMs) have been successfully adopted for speech-processing tasks including automatic speech recognition (ASR). The LMs have ample expressiveness and perform efficiently. This efficiency is a suitable characteristic for streaming applications of ASR. In this work, we propose to use a decoder-only architecture for blockwise streaming ASR. In our approach, speech features are compressed using CTC output and context embedding using blockwise speech subnetwork, and are sequentially provided as prompts to the decoder. The decoder estimates the output tokens promptly at each block. To this end, we also propose a novel training scheme using random-length prefix prompts to make the model robust to the truncated prompts caused by blockwise processing. An experimental comparison shows that our proposed decoder-only streaming ASR achieves 8% relative word error rate reduction in the LibriSpeech test-other set while being twice as fast as the baseline model.
6/26/2024
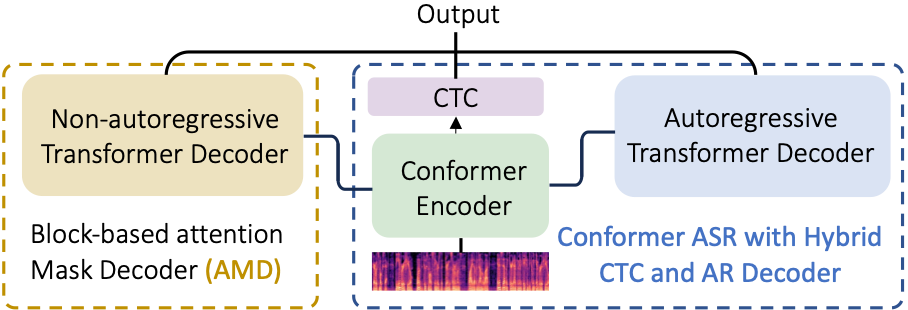
Towards Effective and Efficient Non-autoregressive Decoding Using Block-based Attention Mask
Tianzi Wang, Xurong Xie, Zhaoqing Li, Shoukang Hu, Zengrui Jing, Jiajun Deng, Mingyu Cui, Shujie Hu, Mengzhe Geng, Guinan Li, Helen Meng, Xunying Liu
0
0
This paper proposes a novel non-autoregressive (NAR) block-based Attention Mask Decoder (AMD) that flexibly balances performance-efficiency trade-offs for Conformer ASR systems. AMD performs parallel NAR inference within contiguous blocks of output labels that are concealed using attention masks, while conducting left-to-right AR prediction and history context amalgamation between blocks. A beam search algorithm is designed to leverage a dynamic fusion of CTC, AR Decoder, and AMD probabilities. Experiments on the LibriSpeech-100hr corpus suggest the tripartite Decoder incorporating the AMD module produces a maximum decoding speed-up ratio of 1.73x over the baseline CTC+AR decoding, while incurring no statistically significant word error rate (WER) increase on the test sets. When operating with the same decoding real time factors, statistically significant WER reductions of up to 0.7% and 0.3% absolute (5.3% and 6.1% relative) were obtained over the CTC+AR baseline.
6/17/2024