Towards Effective and Efficient Non-autoregressive Decoding Using Block-based Attention Mask

0
Sign in to get full access
Overview
- This paper presents a novel approach to non-autoregressive decoding for automatic speech recognition (ASR) using a block-based attention mask.
- The proposed method aims to improve the effectiveness and efficiency of non-autoregressive ASR systems, which generate the entire output sequence in a single step, unlike autoregressive models that generate the output sequentially.
- The paper introduces a hybrid attention encoder-decoder architecture and a block-based attention mask to enable effective and efficient non-autoregressive decoding.
Plain English Explanation
In speech recognition, there are two main approaches to generating the text output from audio input: autoregressive and non-autoregressive. Autoregressive models generate the output one word at a time, while non-autoregressive models generate the entire output sequence in a single step.
Non-autoregressive models can be faster, but they can also be less accurate than autoregressive models. This paper introduces a new approach to non-autoregressive speech recognition that aims to be both effective (accurate) and efficient (fast).
The key idea is to use a "block-based attention mask" to guide the model's attention during the decoding process. This means that the model doesn't have to consider all possible combinations of words, but instead can focus on relevant blocks of the output sequence. This helps the model generate accurate output more efficiently.
The paper also describes a hybrid attention encoder-decoder architecture that combines the strengths of different attention mechanisms to further improve the model's performance.
Technical Explanation
The paper proposes a novel non-autoregressive decoding approach for automatic speech recognition (ASR) using a block-based attention mask. This approach is designed to improve the effectiveness and efficiency of non-autoregressive ASR systems, which can generate the entire output sequence in a single step, unlike autoregressive models that generate the output sequentially.
The paper introduces a hybrid attention encoder-decoder architecture that combines different attention mechanisms to enhance the model's performance. Specifically, the encoder uses a multi-head attention mechanism, while the decoder uses a block-based attention mask to focus on relevant parts of the output sequence.
The block-based attention mask divides the output sequence into smaller blocks and allows the model to attend only to the relevant blocks during decoding. This helps the model generate accurate output more efficiently, as it doesn't have to consider all possible combinations of words in the output.
The paper also explores the use of CTC-based loss to further improve the model's performance by incorporating the connectionist temporal classification (CTC) objective during training.
Critical Analysis
The paper presents a promising approach to non-autoregressive ASR, but it is important to consider some potential limitations and areas for further research.
One limitation is that the block-based attention mask may not be suitable for all types of output sequences, particularly those with complex dependencies or variable lengths. The authors acknowledge this and suggest that further research is needed to explore more adaptive attention mechanisms.
Additionally, the paper focuses on ASR, but the proposed approach could potentially be extended to other sequence-to-sequence tasks, such as machine translation or text generation. Evaluating the performance of the block-based attention mask in these other domains could provide valuable insights.
Another area for further research is the integration of the CTC-based loss. While the authors demonstrate the benefits of this approach, it would be interesting to explore other training strategies or loss functions that could further improve the model's performance and robustness.
Conclusion
This paper presents a novel non-autoregressive decoding approach for automatic speech recognition that uses a block-based attention mask to improve the effectiveness and efficiency of the decoding process. The proposed hybrid attention encoder-decoder architecture, combined with the block-based attention mask and CTC-based loss, demonstrates promising results in improving the accuracy and speed of non-autoregressive ASR systems.
The research outlined in this paper has the potential to contribute to the development of more practical and widely applicable non-autoregressive models, which could have significant implications for a variety of sequence-to-sequence tasks beyond speech recognition. By addressing the limitations of current non-autoregressive approaches, the authors have taken an important step towards realizing the full potential of this promising technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Effective and Efficient Non-autoregressive Decoding Using Block-based Attention Mask
Tianzi Wang, Xurong Xie, Zhaoqing Li, Shoukang Hu, Zengrui Jin, Jiajun Deng, Mingyu Cui, Shujie Hu, Mengzhe Geng, Guinan Li, Helen Meng, Xunying Liu
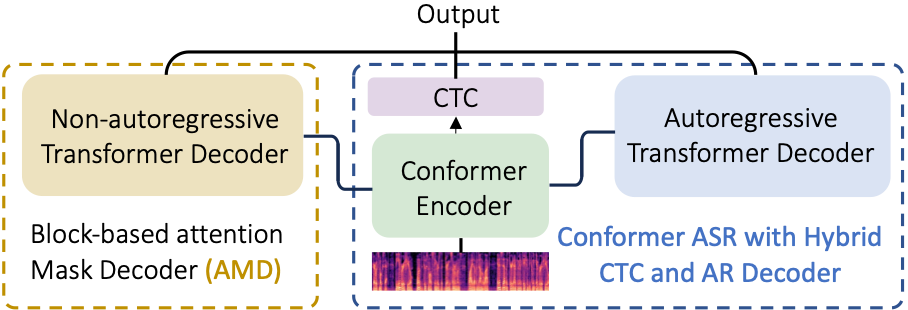
This paper proposes a novel non-autoregressive (NAR) block-based Attention Mask Decoder (AMD) that flexibly balances performance-efficiency trade-offs for Conformer ASR systems. AMD performs parallel NAR inference within contiguous blocks of output labels that are concealed using attention masks, while conducting left-to-right AR prediction and history context amalgamation between blocks. A beam search algorithm is designed to leverage a dynamic fusion of CTC, AR Decoder, and AMD probabilities. Experiments on the LibriSpeech-100hr corpus suggest the tripartite Decoder incorporating the AMD module produces a maximum decoding speed-up ratio of 1.73x over the baseline CTC+AR decoding, while incurring no statistically significant word error rate (WER) increase on the test sets. When operating with the same decoding real time factors, statistically significant WER reductions of up to 0.7% and 0.3% absolute (5.3% and 6.1% relative) were obtained over the CTC+AR baseline.
Read more9/2/2024

0
A Single-Step Non-Autoregressive Automatic Speech Recognition Architecture with High Accuracy and Inference Speed
Ziyang Zhuang, Chenfeng Miao, Kun Zou, Ming Fang, Tao Wei, Zijian Li, Ning Cheng, Wei Hu, Shaojun Wang, Jing Xiao
Non-autoregressive (NAR) automatic speech recognition (ASR) models predict tokens independently and simultaneously, bringing high inference speed. However, there is still a gap in the accuracy of the NAR models compared to the autoregressive (AR) models. In this paper, we propose a single-step NAR ASR architecture with high accuracy and inference speed, called EffectiveASR. It uses an Index Mapping Vector (IMV) based alignment generator to generate alignments during training, and an alignment predictor to learn the alignments for inference. It can be trained end-to-end (E2E) with cross-entropy loss combined with alignment loss. The proposed EffectiveASR achieves competitive results on the AISHELL-1 and AISHELL-2 Mandarin benchmarks compared to the leading models. Specifically, it achieves character error rates (CER) of 4.26%/4.62% on the AISHELL-1 dev/test dataset, which outperforms the AR Conformer with about 30x inference speedup.
Read more8/29/2024

0
Attention-Constrained Inference for Robust Decoder-Only Text-to-Speech
Hankun Wang, Chenpeng Du, Yiwei Guo, Shuai Wang, Xie Chen, Kai Yu
Recent popular decoder-only text-to-speech models are known for their ability of generating natural-sounding speech. However, such models sometimes suffer from word skipping and repeating due to the lack of explicit monotonic alignment constraints. In this paper, we notice from the attention maps that some particular attention heads of the decoder-only model indicate the alignments between speech and text. We call the attention maps of those heads Alignment-Emerged Attention Maps (AEAMs). Based on this discovery, we propose a novel inference method without altering the training process, named Attention-Constrained Inference (ACI), to facilitate monotonic synthesis. It first identifies AEAMs using the Attention Sweeping algorithm and then applies constraining masks on AEAMs. Our experimental results on decoder-only TTS model VALL-E show that the WER of synthesized speech is reduced by up to 20.5% relatively with ACI while the naturalness and speaker similarity are comparable.
Read more5/1/2024
0
4D ASR: Joint Beam Search Integrating CTC, Attention, Transducer, and Mask Predict Decoders
Yui Sudo, Muhammad Shakeel, Yosuke Fukumoto, Brian Yan, Jiatong Shi, Yifan Peng, Shinji Watanabe
End-to-end automatic speech recognition (E2E-ASR) can be classified into several network architectures, such as connectionist temporal classification (CTC), recurrent neural network transducer (RNN-T), attention-based encoder-decoder, and mask-predict models. Each network architecture has advantages and disadvantages, leading practitioners to switch between these different models depending on application requirements. Instead of building separate models, we propose a joint modeling scheme where four decoders (CTC, RNN-T, attention, and mask-predict) share the same encoder -- we refer to this as 4D modeling. The 4D model is trained using multitask learning, which will bring model regularization and maximize the model robustness thanks to their complementary properties. To efficiently train the 4D model, we introduce a two-stage training strategy that stabilizes multitask learning. In addition, we propose three novel one-pass beam search algorithms by combining three decoders (CTC, RNN-T, and attention) to further improve performance. These three beam search algorithms differ in which decoder is used as the primary decoder. We carefully evaluate the performance and computational tradeoffs associated with each algorithm. Experimental results demonstrate that the jointly trained 4D model outperforms the E2E-ASR models trained with only one individual decoder. Furthermore, we demonstrate that the proposed one-pass beam search algorithm outperforms the previously proposed CTC/attention decoding.
Read more6/6/2024