Enhancing CTC-based speech recognition with diverse modeling units
2406.03274
0
0
🗣️
Abstract
In recent years, the evolution of end-to-end (E2E) automatic speech recognition (ASR) models has been remarkable, largely due to advances in deep learning architectures like transformer. On top of E2E systems, researchers have achieved substantial accuracy improvement by rescoring E2E model's N-best hypotheses with a phoneme-based model. This raises an interesting question about where the improvements come from other than the system combination effect. We examine the underlying mechanisms driving these gains and propose an efficient joint training approach, where E2E models are trained jointly with diverse modeling units. This methodology does not only align the strengths of both phoneme and grapheme-based models but also reveals that using these diverse modeling units in a synergistic way can significantly enhance model accuracy. Our findings offer new insights into the optimal integration of heterogeneous modeling units in the development of more robust and accurate ASR systems.
Create account to get full access
Overview
- Researchers have made significant progress in end-to-end (E2E) automatic speech recognition (ASR) models, largely due to advances in deep learning architectures like transformer.
- Rescoring the N-best hypotheses of E2E models with a phoneme-based model can lead to substantial accuracy improvements.
- This raises questions about the underlying mechanisms driving these gains beyond just the system combination effect.
Plain English Explanation
Speech recognition is the process of converting spoken language into text. In recent years, end-to-end (E2E) automatic speech recognition (ASR) models have become increasingly accurate, thanks to improvements in deep learning techniques like the transformer architecture.
One way researchers have further improved the accuracy of these E2E models is by using a second, phoneme-based model to "rescore" the top potential outputs (or "hypotheses") from the E2E model. This essentially allows the system to double-check its work and choose the most accurate transcription.
The researchers in this paper wanted to understand why this rescoring approach leads to such significant accuracy gains, beyond just the benefit of combining multiple models. They propose an efficient way to train E2E models that incorporate both phoneme-based and grapheme-based (letter-based) modeling, allowing the models to learn from these diverse representations in a synergistic way.
This approach not only aligns the strengths of both types of models but also shows that using these diverse modeling units together can substantially improve the overall accuracy of the speech recognition system.
Technical Explanation
The researchers explore the underlying mechanisms driving the accuracy improvements achieved by rescoring the N-best hypotheses of E2E ASR models with a phoneme-based model. They propose an efficient joint training approach where E2E models are trained in conjunction with diverse modeling units, including both phonemes and graphemes (letters).
This methodology allows the E2E model to leverage the complementary strengths of phoneme-based and grapheme-based representations, leading to significant accuracy gains. The researchers hypothesize that the diverse modeling units enable the model to better capture the complex relationship between speech sounds and their written representations, resulting in more robust and accurate ASR performance.
Through their experiments, the researchers demonstrate that this joint training approach outperforms standalone E2E models as well as systems that simply combine E2E and phoneme-based models. The findings offer new insights into the optimal integration of heterogeneous modeling units for developing more accurate and reliable ASR systems.
Critical Analysis
The researchers provide a thorough investigation of the benefits of incorporating diverse modeling units, such as phonemes and graphemes, into E2E ASR models. Their proposed joint training approach is an efficient and effective way to leverage the complementary strengths of these different representations.
However, the paper does not delve deeply into the potential limitations or caveats of this approach. For instance, it would be helpful to understand how the joint training method scales with larger datasets or more complex speech recognition tasks. Additionally, the researchers could explore the computational efficiency and real-world deployment considerations of their approach, as these factors can be crucial for practical applications of ASR systems.
Further research could also investigate the generalizability of the findings to other speech recognition architectures or language domains. Exploring the interpretability of the joint modeling units and their contribution to the model's decision-making process could also yield valuable insights.
Conclusion
This research offers a novel approach to improving the accuracy of end-to-end automatic speech recognition models by jointly training them with diverse modeling units, such as phonemes and graphemes. The findings demonstrate that leveraging these complementary representations in a synergistic way can significantly enhance the overall performance of ASR systems.
The proposed methodology provides a promising direction for developing more robust and reliable speech recognition technologies, with potential applications in a wide range of domains, from voice assistants to transcription services. By continuing to explore the optimal integration of heterogeneous modeling units, researchers can further advance the state of the art in automatic speech recognition and unlock new possibilities for human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Integrating Pre-Trained Speech and Language Models for End-to-End Speech Recognition
Yukiya Hono, Koh Mitsuda, Tianyu Zhao, Kentaro Mitsui, Toshiaki Wakatsuki, Kei Sawada
0
0
Advances in machine learning have made it possible to perform various text and speech processing tasks, such as automatic speech recognition (ASR), in an end-to-end (E2E) manner. E2E approaches utilizing pre-trained models are gaining attention for conserving training data and resources. However, most of their applications in ASR involve only one of either a pre-trained speech or a language model. This paper proposes integrating a pre-trained speech representation model and a large language model (LLM) for E2E ASR. The proposed model enables the optimization of the entire ASR process, including acoustic feature extraction and acoustic and language modeling, by combining pre-trained models with a bridge network and also enables the application of remarkable developments in LLM utilization, such as parameter-efficient domain adaptation and inference optimization. Experimental results demonstrate that the proposed model achieves a performance comparable to that of modern E2E ASR models by utilizing powerful pre-training models with the proposed integrated approach.
6/7/2024
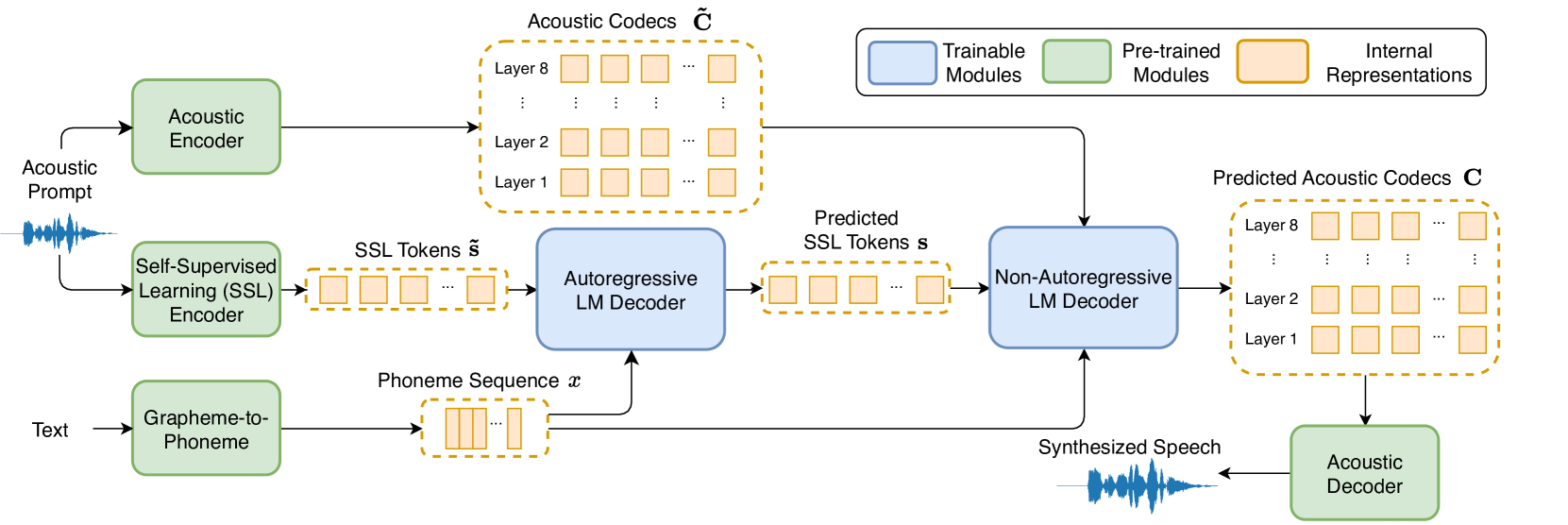
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
0
0
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
6/13/2024

Crossmodal ASR Error Correction with Discrete Speech Units
Yuanchao Li, Pinzhen Chen, Peter Bell, Catherine Lai
0
0
ASR remains unsatisfactory in scenarios where the speaking style diverges from that used to train ASR systems, resulting in erroneous transcripts. To address this, ASR Error Correction (AEC), a post-ASR processing approach, is required. In this work, we tackle an understudied issue: the Low-Resource Out-of-Domain (LROOD) problem, by investigating crossmodal AEC on very limited downstream data with 1-best hypothesis transcription. We explore pre-training and fine-tuning strategies and uncover an ASR domain discrepancy phenomenon, shedding light on appropriate training schemes for LROOD data. Moreover, we propose the incorporation of discrete speech units to align with and enhance the word embeddings for improving AEC quality. Results from multiple corpora and several evaluation metrics demonstrate the feasibility and efficacy of our proposed AEC approach on LROOD data, as well as its generalizability and superiority on large-scale data. Finally, a study on speech emotion recognition confirms that our model produces ASR error-robust transcripts suitable for downstream applications.
5/28/2024
4D ASR: Joint Beam Search Integrating CTC, Attention, Transducer, and Mask Predict Decoders
Yui Sudo, Muhammad Shakeel, Yosuke Fukumoto, Brian Yan, Jiatong Shi, Yifan Peng, Shinji Watanabe
0
0
End-to-end automatic speech recognition (E2E-ASR) can be classified into several network architectures, such as connectionist temporal classification (CTC), recurrent neural network transducer (RNN-T), attention-based encoder-decoder, and mask-predict models. Each network architecture has advantages and disadvantages, leading practitioners to switch between these different models depending on application requirements. Instead of building separate models, we propose a joint modeling scheme where four decoders (CTC, RNN-T, attention, and mask-predict) share the same encoder -- we refer to this as 4D modeling. The 4D model is trained using multitask learning, which will bring model regularization and maximize the model robustness thanks to their complementary properties. To efficiently train the 4D model, we introduce a two-stage training strategy that stabilizes multitask learning. In addition, we propose three novel one-pass beam search algorithms by combining three decoders (CTC, RNN-T, and attention) to further improve performance. These three beam search algorithms differ in which decoder is used as the primary decoder. We carefully evaluate the performance and computational tradeoffs associated with each algorithm. Experimental results demonstrate that the jointly trained 4D model outperforms the E2E-ASR models trained with only one individual decoder. Furthermore, we demonstrate that the proposed one-pass beam search algorithm outperforms the previously proposed CTC/attention decoding.
6/6/2024