ABEX: Data Augmentation for Low-Resource NLU via Expanding Abstract Descriptions

0

Sign in to get full access
Overview
- This paper introduces a novel data augmentation technique called ABEX (Abstract Expansion) for low-resource Natural Language Understanding (NLU) tasks.
- ABEX generates new training examples by expanding abstract descriptions of existing examples, helping to address the challenge of data scarcity in low-resource settings.
- The approach leverages large language models to generate diverse, semantically-relevant text based on the abstract description of an input example.
- ABEX is evaluated on several benchmark NLU tasks, demonstrating significant performance improvements over other data augmentation methods, especially in low-resource scenarios.
Plain English Explanation
ABEX: Data Augmentation for Low-Resource NLU via Expanding Abstract Descriptions is a research paper that introduces a new way to generate more training data for natural language understanding (NLU) models, particularly when the original dataset is small.
The key idea is to take the existing examples in the dataset, extract an abstract or high-level description of each one, and then use large language models to generate new examples based on those abstractions. This allows the model to learn from a much larger, more diverse set of examples while still staying true to the original data.
For example, if you had a dataset of customer service chat logs, you might extract an abstract like "customer asks about returning a product" and then use language models to generate new, realistic-sounding conversations around that theme. This gives the NLU model more exposure to the kinds of language and concepts it needs to learn, even if the original dataset was quite small.
The researchers show that this ABEX approach leads to significant performance gains on several common NLU benchmarks, especially when the original dataset is limited. It's an innovative way to get more mileage out of scarce data resources, which is a common challenge in real-world AI applications.
Technical Explanation
The paper introduces a novel data augmentation technique called ABEX: Abstract Expansion, which aims to address the challenge of data scarcity in low-resource Natural Language Understanding (NLU) tasks.
The core idea of ABEX is to leverage large language models to generate new training examples based on the abstract descriptions of existing examples in the dataset. The authors first extract high-level, semantic "abstracts" that capture the essence of each input example. They then use these abstracts as prompts to a large language model, which generates diverse, relevant text that expands upon the original example.
This approach allows the model to learn from a much richer set of training data, without straying too far from the original distribution. The authors evaluate ABEX on several NLU benchmarks, including intent classification, slot filling, and dialogue state tracking. They demonstrate that ABEX significantly outperforms other data augmentation techniques, especially in low-resource settings where the original dataset is limited.
The technical details of the ABEX procedure include:
- Abstract extraction: The authors use a pre-trained model to extract concise, semantic representations of each input example.
- Abstract expansion: These abstracts are then used as prompts to a large language model (e.g. GPT-3), which generates new, diverse examples based on the abstract.
- Iterative refinement: The process can be repeated iteratively, using the expanded examples to generate further synthetic data.
Through extensive experimentation, the authors show that this ABEX approach leads to substantial performance gains across multiple NLU tasks and dataset sizes. They also provide detailed analysis and ablation studies to understand the key factors underlying ABEX's effectiveness.
Critical Analysis
The ABEX paper presents a novel and promising approach to data augmentation for low-resource NLU tasks. The core idea of leveraging large language models to expand upon abstract representations of training examples is clever and well-executed.
One notable strength of the ABEX method is its flexibility - it can be applied to a wide range of NLU tasks, from intent classification to dialogue state tracking, without requiring task-specific modifications. This speaks to the generalizability of the approach.
However, the paper does not deeply explore some potential limitations or edge cases. For instance, the authors acknowledge that the quality of the generated examples is dependent on the capabilities of the underlying language model. In low-resource settings where the training data is particularly scarce or noisy, the language model may struggle to produce high-quality expansions, limiting the effectiveness of ABEX.
Additionally, the paper does not address potential biases or inconsistencies that could be introduced by the language model generation process. While the authors perform thorough evaluation, further analysis on the diversity, coherence, and fidelity of the synthetic examples could strengthen the work.
Targeted Augmentation for Low-Resource Event Extraction and Leveraging Data Augmentation for Process Information Extraction are two other relevant papers that explore data augmentation techniques for low-resource NLP tasks. Comparing and contrasting ABEX with these approaches could provide additional insights.
Overall, the ABEX paper presents a novel and promising direction for data augmentation that could have significant real-world impact, especially in domains with limited labeled data. Further research to address the potential limitations would strengthen the contribution.
Conclusion
The ABEX paper introduces a novel data augmentation technique that leverages large language models to generate new training examples for low-resource Natural Language Understanding (NLU) tasks.
By extracting abstract, semantic representations of existing examples and using them as prompts to generate expanded, diverse examples, ABEX allows NLU models to learn from a much richer dataset, even when the original training data is limited.
The researchers demonstrate significant performance improvements on several NLU benchmarks, especially in low-resource settings. This work highlights the potential of large language models to serve as powerful data augmentation tools, and the ABEX approach represents an important step forward in addressing the challenge of data scarcity in real-world AI applications.
Further research to address potential limitations, such as the reliance on high-quality language models and the need for more rigorous analysis of the generated examples, could strengthen the ABEX methodology and unlock even greater benefits for low-resource NLU tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ABEX: Data Augmentation for Low-Resource NLU via Expanding Abstract Descriptions
Sreyan Ghosh, Utkarsh Tyagi, Sonal Kumar, C. K. Evuru, S Ramaneswaran, S Sakshi, Dinesh Manocha
We present ABEX, a novel and effective generative data augmentation methodology for low-resource Natural Language Understanding (NLU) tasks. ABEX is based on ABstract-and-EXpand, a novel paradigm for generating diverse forms of an input document -- we first convert a document into its concise, abstract description and then generate new documents based on expanding the resultant abstraction. To learn the task of expanding abstract descriptions, we first train BART on a large-scale synthetic dataset with abstract-document pairs. Next, to generate abstract descriptions for a document, we propose a simple, controllable, and training-free method based on editing AMR graphs. ABEX brings the best of both worlds: by expanding from abstract representations, it preserves the original semantic properties of the documents, like style and meaning, thereby maintaining alignment with the original label and data distribution. At the same time, the fundamental process of elaborating on abstract descriptions facilitates diverse generations. We demonstrate the effectiveness of ABEX on 4 NLU tasks spanning 12 datasets and 4 low-resource settings. ABEX outperforms all our baselines qualitatively with improvements of 0.04% - 38.8%. Qualitatively, ABEX outperforms all prior methods from literature in terms of context and length diversity.
Read more6/7/2024
0
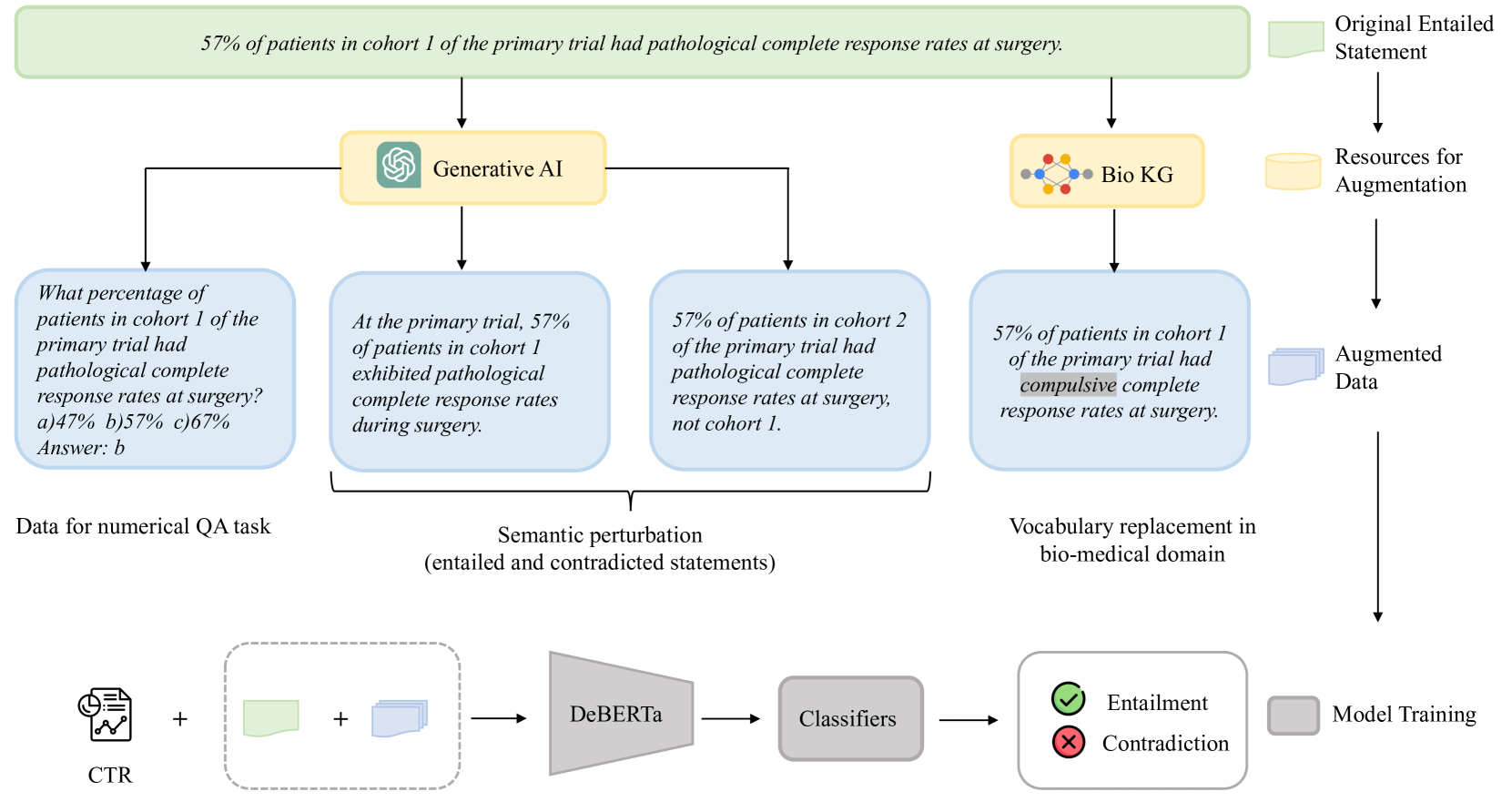
DKE-Research at SemEval-2024 Task 2: Incorporating Data Augmentation with Generative Models and Biomedical Knowledge to Enhance Inference Robustness
Yuqi Wang, Zeqiang Wang, Wei Wang, Qi Chen, Kaizhu Huang, Anh Nguyen, Suparna De
Safe and reliable natural language inference is critical for extracting insights from clinical trial reports but poses challenges due to biases in large pre-trained language models. This paper presents a novel data augmentation technique to improve model robustness for biomedical natural language inference in clinical trials. By generating synthetic examples through semantic perturbations and domain-specific vocabulary replacement and adding a new task for numerical and quantitative reasoning, we introduce greater diversity and reduce shortcut learning. Our approach, combined with multi-task learning and the DeBERTa architecture, achieved significant performance gains on the NLI4CT 2024 benchmark compared to the original language models. Ablation studies validate the contribution of each augmentation method in improving robustness. Our best-performing model ranked 12th in terms of faithfulness and 8th in terms of consistency, respectively, out of the 32 participants.
Read more4/16/2024

0
Ex3: Automatic Novel Writing by Extracting, Excelsior and Expanding
Lei Huang, Jiaming Guo, Guanhua He, Xishan Zhang, Rui Zhang, Shaohui Peng, Shaoli Liu, Tianshi Chen
Generating long-term texts such as novels using artificial intelligence has always been a challenge. A common approach is to use large language models (LLMs) to construct a hierarchical framework that first plans and then writes. Despite the fact that the generated novels reach a sufficient length, they exhibit poor logical coherence and appeal in their plots and deficiencies in character and event depiction, ultimately compromising the overall narrative quality. In this paper, we propose a method named Extracting Excelsior and Expanding. Ex3 initially extracts structure information from raw novel data. By combining this structure information with the novel data, an instruction-following dataset is meticulously crafted. This dataset is then utilized to fine-tune the LLM, aiming for excelsior generation performance. In the final stage, a tree-like expansion method is deployed to facilitate the generation of arbitrarily long novels. Evaluation against previous methods showcases Ex3's ability to produce higher-quality long-form novels.
Read more9/4/2024
⛏️
0
Targeted Augmentation for Low-Resource Event Extraction
Sijia Wang, Lifu Huang
Addressing the challenge of low-resource information extraction remains an ongoing issue due to the inherent information scarcity within limited training examples. Existing data augmentation methods, considered potential solutions, struggle to strike a balance between weak augmentation (e.g., synonym augmentation) and drastic augmentation (e.g., conditional generation without proper guidance). This paper introduces a novel paradigm that employs targeted augmentation and back validation to produce augmented examples with enhanced diversity, polarity, accuracy, and coherence. Extensive experimental results demonstrate the effectiveness of the proposed paradigm. Furthermore, identified limitations are discussed, shedding light on areas for future improvement.
Read more5/15/2024