DKE-Research at SemEval-2024 Task 2: Incorporating Data Augmentation with Generative Models and Biomedical Knowledge to Enhance Inference Robustness
2404.09206
0
0
Abstract
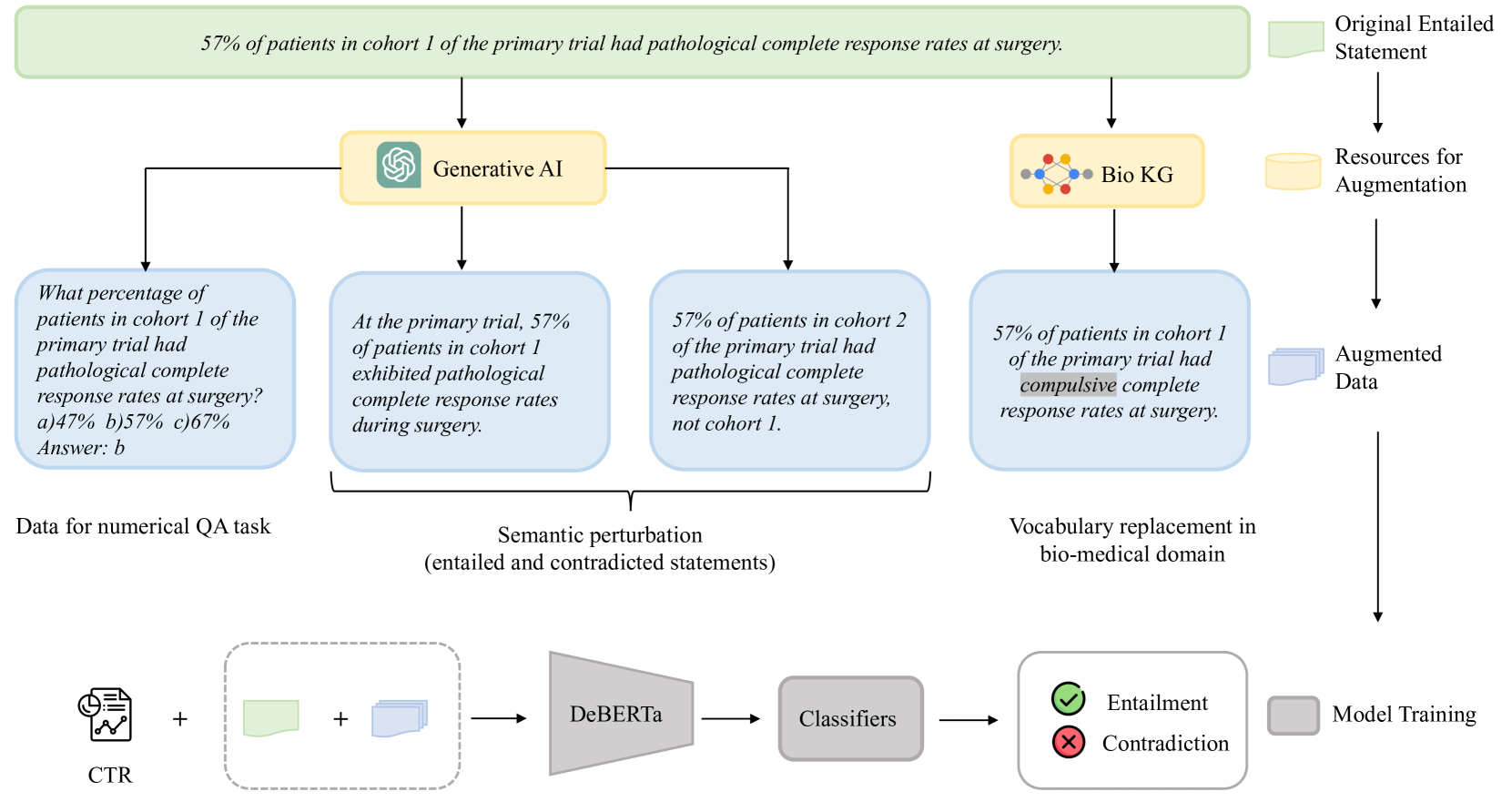
Safe and reliable natural language inference is critical for extracting insights from clinical trial reports but poses challenges due to biases in large pre-trained language models. This paper presents a novel data augmentation technique to improve model robustness for biomedical natural language inference in clinical trials. By generating synthetic examples through semantic perturbations and domain-specific vocabulary replacement and adding a new task for numerical and quantitative reasoning, we introduce greater diversity and reduce shortcut learning. Our approach, combined with multi-task learning and the DeBERTa architecture, achieved significant performance gains on the NLI4CT 2024 benchmark compared to the original language models. Ablation studies validate the contribution of each augmentation method in improving robustness. Our best-performing model ranked 12th in terms of faithfulness and 8th in terms of consistency, respectively, out of the 32 participants.
Create account to get full access
Overview
- Proposed a novel approach for SemEval-2024 Task 2 on enhancing inference robustness in biomedical natural language processing
- Leveraged data augmentation with generative models and biomedical knowledge to improve the performance and robustness of language models
- Conducted experiments on various state-of-the-art models to evaluate the effectiveness of their approach
Plain English Explanation
The research paper presents a new method for a natural language processing task focused on the biomedical domain. The goal is to improve the ability of language models to draw accurate conclusions from text, even when faced with challenging or ambiguous inputs.
The researchers used a technique called data augmentation to generate additional training data. This involved using generative models to create new text that mimics the characteristics of the original dataset. By combining this synthetic data with biomedical knowledge, the researchers were able to train language models that were more robust and accurate when processing real-world biomedical text.
The team evaluated their approach by testing it on various state-of-the-art language models, including some that were specifically designed for biomedical tasks. The results showed that their data augmentation and knowledge integration techniques led to significant improvements in the models' ability to draw accurate inferences from the input text.
Technical Explanation
The researchers proposed a novel approach for SemEval-2024 Task 2, which aimed to enhance the robustness of natural language inference in the biomedical domain. They leveraged data augmentation techniques, generative models, and biomedical knowledge to improve the performance of language models on this task.
Specifically, the team used a generative model to generate synthetic text data that shared similar characteristics to the original training corpus. This augmented dataset, combined with relevant biomedical knowledge, was used to fine-tune various state-of-the-art language models, including those designed for biomedical applications.
The researchers conducted extensive experiments to evaluate the effectiveness of their approach. They compared the performance of their models to that of baseline systems on a range of metrics, including accuracy, precision, recall, and F1 score. The results showed that their data augmentation and knowledge integration techniques led to significant improvements in the models' ability to draw accurate inferences from the input text, even when faced with challenging or ambiguous inputs.
Critical Analysis
The paper presents a well-designed and thorough approach to enhancing inference robustness in the biomedical domain. The use of data augmentation and generative models to expand the training dataset is a promising strategy, and the incorporation of domain-specific knowledge is a valuable addition.
However, the paper does not address some potential limitations of the research. For example, the generative model used for data augmentation may introduce biases or artifacts that could negatively impact the final model performance. Additionally, the reliance on external biomedical knowledge sources raises questions about the scalability and generalizability of the approach to other domains or tasks.
Further research could explore the sensitivity of the models to the quality and coverage of the biomedical knowledge base, as well as investigate alternative data augmentation techniques or model architectures that may be more effective in capturing the nuances of biomedical language and reasoning.
Conclusion
The research presented in this paper offers a compelling approach to improving the robustness and accuracy of natural language inference in the biomedical domain. By leveraging data augmentation with generative models and integrating biomedical knowledge, the researchers were able to enhance the performance of state-of-the-art language models on a challenging task.
The findings of this study have significant implications for the development of more reliable and trustworthy natural language processing systems in the biomedical field, where accurate inferences can have important real-world consequences. The techniques and insights presented in this paper could also be adapted and applied to other domains and tasks, contributing to the broader advancement of natural language understanding and inference capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for Clinical Trials
Mael Jullien, Marco Valentino, Andr'e Freitas
0
0
Large Language Models (LLMs) are at the forefront of NLP achievements but fall short in dealing with shortcut learning, factual inconsistency, and vulnerability to adversarial inputs.These shortcomings are especially critical in medical contexts, where they can misrepresent actual model capabilities. Addressing this, we present SemEval-2024 Task 2: Safe Biomedical Natural Language Inference for ClinicalTrials. Our contributions include the refined NLI4CT-P dataset (i.e., Natural Language Inference for Clinical Trials - Perturbed), designed to challenge LLMs with interventional and causal reasoning tasks, along with a comprehensive evaluation of methods and results for participant submissions. A total of 106 participants registered for the task contributing to over 1200 individual submissions and 25 system overview papers. This initiative aims to advance the robustness and applicability of NLI models in healthcare, ensuring safer and more dependable AI assistance in clinical decision-making. We anticipate that the dataset, models, and outcomes of this task can support future research in the field of biomedical NLI. The dataset, competition leaderboard, and website are publicly available.
4/9/2024
SEME at SemEval-2024 Task 2: Comparing Masked and Generative Language Models on Natural Language Inference for Clinical Trials
Mathilde Aguiar, Pierre Zweigenbaum, Nona Naderi
0
0
This paper describes our submission to Task 2 of SemEval-2024: Safe Biomedical Natural Language Inference for Clinical Trials. The Multi-evidence Natural Language Inference for Clinical Trial Data (NLI4CT) consists of a Textual Entailment (TE) task focused on the evaluation of the consistency and faithfulness of Natural Language Inference (NLI) models applied to Clinical Trial Reports (CTR). We test 2 distinct approaches, one based on finetuning and ensembling Masked Language Models and the other based on prompting Large Language Models using templates, in particular, using Chain-Of-Thought and Contrastive Chain-Of-Thought. Prompting Flan-T5-large in a 2-shot setting leads to our best system that achieves 0.57 F1 score, 0.64 Faithfulness, and 0.56 Consistency.
4/8/2024
📊
DFKI-NLP at SemEval-2024 Task 2: Towards Robust LLMs Using Data Perturbations and MinMax Training
Bhuvanesh Verma, Lisa Raithel
0
0
The NLI4CT task at SemEval-2024 emphasizes the development of robust models for Natural Language Inference on Clinical Trial Reports (CTRs) using large language models (LLMs). This edition introduces interventions specifically targeting the numerical, vocabulary, and semantic aspects of CTRs. Our proposed system harnesses the capabilities of the state-of-the-art Mistral model, complemented by an auxiliary model, to focus on the intricate input space of the NLI4CT dataset. Through the incorporation of numerical and acronym-based perturbations to the data, we train a robust system capable of handling both semantic-altering and numerical contradiction interventions. Our analysis on the dataset sheds light on the challenging sections of the CTRs for reasoning.
5/2/2024

On-the-fly Definition Augmentation of LLMs for Biomedical NER
Monica Munnangi, Sergey Feldman, Byron C Wallace, Silvio Amir, Tom Hope, Aakanksha Naik
0
0
Despite their general capabilities, LLMs still struggle on biomedical NER tasks, which are difficult due to the presence of specialized terminology and lack of training data. In this work we set out to improve LLM performance on biomedical NER in limited data settings via a new knowledge augmentation approach which incorporates definitions of relevant concepts on-the-fly. During this process, to provide a test bed for knowledge augmentation, we perform a comprehensive exploration of prompting strategies. Our experiments show that definition augmentation is useful for both open source and closed LLMs. For example, it leads to a relative improvement of 15% (on average) in GPT-4 performance (F1) across all (six) of our test datasets. We conduct extensive ablations and analyses to demonstrate that our performance improvements stem from adding relevant definitional knowledge. We find that careful prompting strategies also improve LLM performance, allowing them to outperform fine-tuned language models in few-shot settings. To facilitate future research in this direction, we release our code at https://github.com/allenai/beacon.
4/24/2024