ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models

0

Sign in to get full access
Overview
- Provides a plain English summary of a research paper on "ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models"
- Covers the key ideas, experiment design, and insights from the paper
- Discusses potential limitations and areas for further research
- Encourages critical thinking about the research and its implications
Plain English Explanation
The research paper describes a new technique called "ABQ-LLM" that can make large language models run more efficiently by compressing the size of their internal parameters. Large language models are powerful AI systems that can understand and generate human-like text, but they require a lot of computing power and memory to run.
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models introduces a way to reduce the number of bits used to represent the model's parameters, which can significantly speed up the model's operation without dramatically reducing its accuracy. The key idea is to use different levels of compression (quantization) for different parts of the model, rather than applying the same level of compression everywhere.
By carefully selecting the right level of quantization for each part of the model, the researchers were able to achieve big speedups in inference time (when the model is actually being used) without sacrificing too much accuracy. This could make it practical to deploy large language models on a wider range of devices, from smartphones to edge computing devices, where computing resources are more limited.
Technical Explanation
The ABQ-LLM approach involves dividing the model parameters into different "blocks" and applying different levels of quantization to each block. This "arbitrary-bit quantization" allows the model to be compressed more aggressively in some areas while preserving higher precision in more critical areas.
The researchers experimented with several different quantization schemes and found that a combination of 4-bit and 8-bit quantization worked well, providing significant speedups with minimal accuracy degradation. They also developed a "quantization-aware training" process to fine-tune the model and compensate for some of the accuracy loss caused by quantization.
Through extensive experiments on large language models like GPT-2 and GPT-3, the ABQ-LLM technique was shown to achieve 2-4x speedups in inference time while maintaining over 95% of the original model's accuracy.
Critical Analysis
The ABQ-LLM research provides a promising approach for accelerating the inference of large language models, which could make them more practical to deploy in resource-constrained environments. However, the paper does not extensively explore the potential limitations or caveats of the technique.
For example, the impact of the arbitrary quantization on the model's robustness or the ability to handle out-of-distribution inputs is not addressed. Additionally, the paper focuses on commonly used benchmarks like GPT-2 and GPT-3, but it's unclear how well the technique would generalize to other large language models or different downstream tasks.
Further research could investigate the long-term stability of the quantized models, the potential for compounding errors due to the mixed precision, and the broader applicability of the ABQ-LLM approach beyond the specific models and tasks explored in this paper.
Conclusion
The ABQ-LLM research introduces an effective technique for accelerating the inference of large language models by selectively applying different levels of quantization to different parts of the model. This approach can achieve significant speedups while maintaining high accuracy, which could make large language models more practical to deploy on a wider range of devices and in real-world applications.
While the paper provides a solid technical foundation, further research is needed to explore the broader implications and potential limitations of the ABQ-LLM technique. Nonetheless, this work represents an important step forward in enhancing the computational efficiency of large language models, with the potential to unlock new applications and opportunities in the field of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Chao Zeng, Songwei Liu, Yusheng Xie, Hong Liu, Xiaojian Wang, Miao Wei, Shu Yang, Fangmin Chen, Xing Mei
Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their practical application is constrained by substantial memory and computational demands. Post-training quantization (PTQ) is considered an effective method to accelerate LLM inference. Despite its growing popularity in LLM model compression, PTQ deployment faces two major challenges. First, low-bit quantization leads to performance degradation. Second, restricted by the limited integer computing unit type on GPUs, quantized matrix operations with different precisions cannot be effectively accelerated. To address these issues, we introduce a novel arbitrary-bit quantization algorithm and inference framework, ABQ-LLM. It achieves superior performance across various quantization settings and enables efficient arbitrary-precision quantized inference on the GPU. ABQ-LLM introduces several key innovations: (1) a distribution correction method for transformer blocks to mitigate distribution differences caused by full quantization of weights and activations, improving performance at low bit-widths. (2) the bit balance strategy to counteract performance degradation from asymmetric distribution issues at very low bit-widths (e.g., 2-bit). (3) an innovative quantization acceleration framework that reconstructs the quantization matrix multiplication of arbitrary precision combinations based on BTC (Binary TensorCore) equivalents, gets rid of the limitations of INT4/INT8 computing units. ABQ-LLM can convert each component bit width gain into actual acceleration gain, maximizing performance under mixed precision(e.g., W6A6, W2A8). Based on W2*A8 quantization configuration on LLaMA-7B model, it achieved a WikiText2 perplexity of 7.59 (2.17$downarrow $ vs 9.76 in AffineQuant). Compared to SmoothQuant, we realized 1.6$times$ acceleration improvement and 2.7$times$ memory compression gain.
Read more8/26/2024
💬
0
QLLM: Accurate and Efficient Low-Bitwidth Quantization for Large Language Models
Jing Liu, Ruihao Gong, Xiuying Wei, Zhiwei Dong, Jianfei Cai, Bohan Zhuang
Large Language Models (LLMs) excel in NLP, but their demands hinder their widespread deployment. While Quantization-Aware Training (QAT) offers a solution, its extensive training costs make Post-Training Quantization (PTQ) a more practical approach for LLMs. In existing studies, activation outliers in particular channels are identified as the bottleneck to PTQ accuracy. They propose to transform the magnitudes from activations to weights, which however offers limited alleviation or suffers from unstable gradients, resulting in a severe performance drop at low-bitwidth. In this paper, we propose QLLM, an accurate and efficient low-bitwidth PTQ method designed for LLMs. QLLM introduces an adaptive channel reassembly technique that reallocates the magnitude of outliers to other channels, thereby mitigating their impact on the quantization range. This is achieved by channel disassembly and channel assembly, which first breaks down the outlier channels into several sub-channels to ensure a more balanced distribution of activation magnitudes. Then similar channels are merged to maintain the original channel number for efficiency. Additionally, an adaptive strategy is designed to autonomously determine the optimal number of sub-channels for channel disassembly. To further compensate for the performance loss caused by quantization, we propose an efficient tuning method that only learns a small number of low-rank weights while freezing the pre-trained quantized model. After training, these low-rank parameters can be fused into the frozen weights without affecting inference. Extensive experiments on LLaMA-1 and LLaMA-2 show that QLLM can obtain accurate quantized models efficiently. For example, QLLM quantizes the 4-bit LLaMA-2-70B within 10 hours on a single A100-80G GPU, outperforming the previous state-of-the-art method by 7.89% on the average accuracy across five zero-shot tasks.
Read more4/9/2024
0
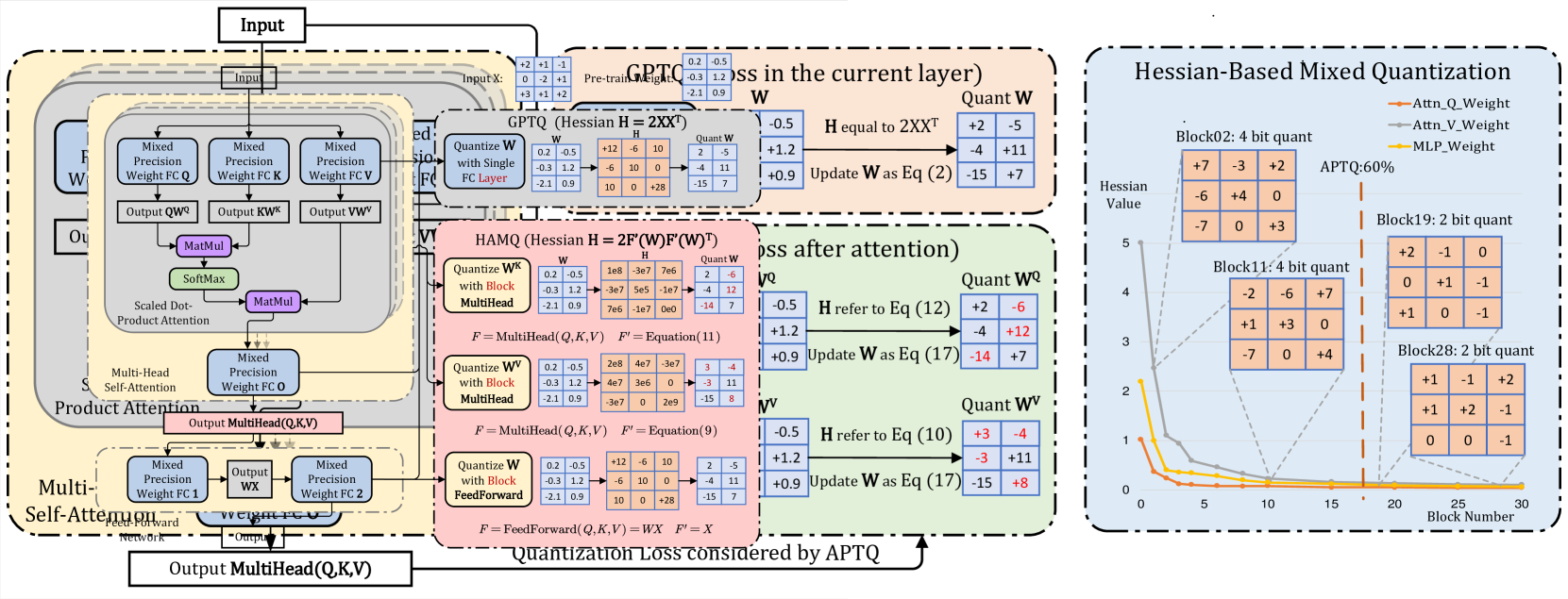
APTQ: Attention-aware Post-Training Mixed-Precision Quantization for Large Language Models
Ziyi Guan, Hantao Huang, Yupeng Su, Hong Huang, Ngai Wong, Hao Yu
Large Language Models (LLMs) have greatly advanced the natural language processing paradigm. However, the high computational load and huge model sizes pose a grand challenge for deployment on edge devices. To this end, we propose APTQ (Attention-aware Post-Training Mixed-Precision Quantization) for LLMs, which considers not only the second-order information of each layer's weights, but also, for the first time, the nonlinear effect of attention outputs on the entire model. We leverage the Hessian trace as a sensitivity metric for mixed-precision quantization, ensuring an informed precision reduction that retains model performance. Experiments show APTQ surpasses previous quantization methods, achieving an average of 4 bit width a 5.22 perplexity nearly equivalent to full precision in the C4 dataset. In addition, APTQ attains state-of-the-art zero-shot accuracy of 68.24% and 70.48% at an average bitwidth of 3.8 in LLaMa-7B and LLaMa-13B, respectively, demonstrating its effectiveness to produce high-quality quantized LLMs.
Read more4/17/2024
💬
0
Enhancing Computation Efficiency in Large Language Models through Weight and Activation Quantization
Janghwan Lee, Minsoo Kim, Seungcheol Baek, Seok Joong Hwang, Wonyong Sung, Jungwook Choi
Large Language Models (LLMs) are proficient in natural language processing tasks, but their deployment is often restricted by extensive parameter sizes and computational demands. This paper focuses on post-training quantization (PTQ) in LLMs, specifically 4-bit weight and 8-bit activation (W4A8) quantization, to enhance computational efficiency -- a topic less explored compared to weight-only quantization. We present two innovative techniques: activation-quantization-aware scaling (AQAS) and sequence-length-aware calibration (SLAC) to enhance PTQ by considering the combined effects on weights and activations and aligning calibration sequence lengths to target tasks. Moreover, we introduce dINT, a hybrid data format combining integer and denormal representations, to address the underflow issue in W4A8 quantization, where small values are rounded to zero. Through rigorous evaluations of LLMs, including OPT and LLaMA, we demonstrate that our techniques significantly boost task accuracies to levels comparable with full-precision models. By developing arithmetic units compatible with dINT, we further confirm that our methods yield a 2$times$ hardware efficiency improvement compared to 8-bit integer MAC unit.
Read more7/19/2024