AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control
2406.03995
0
0

Abstract
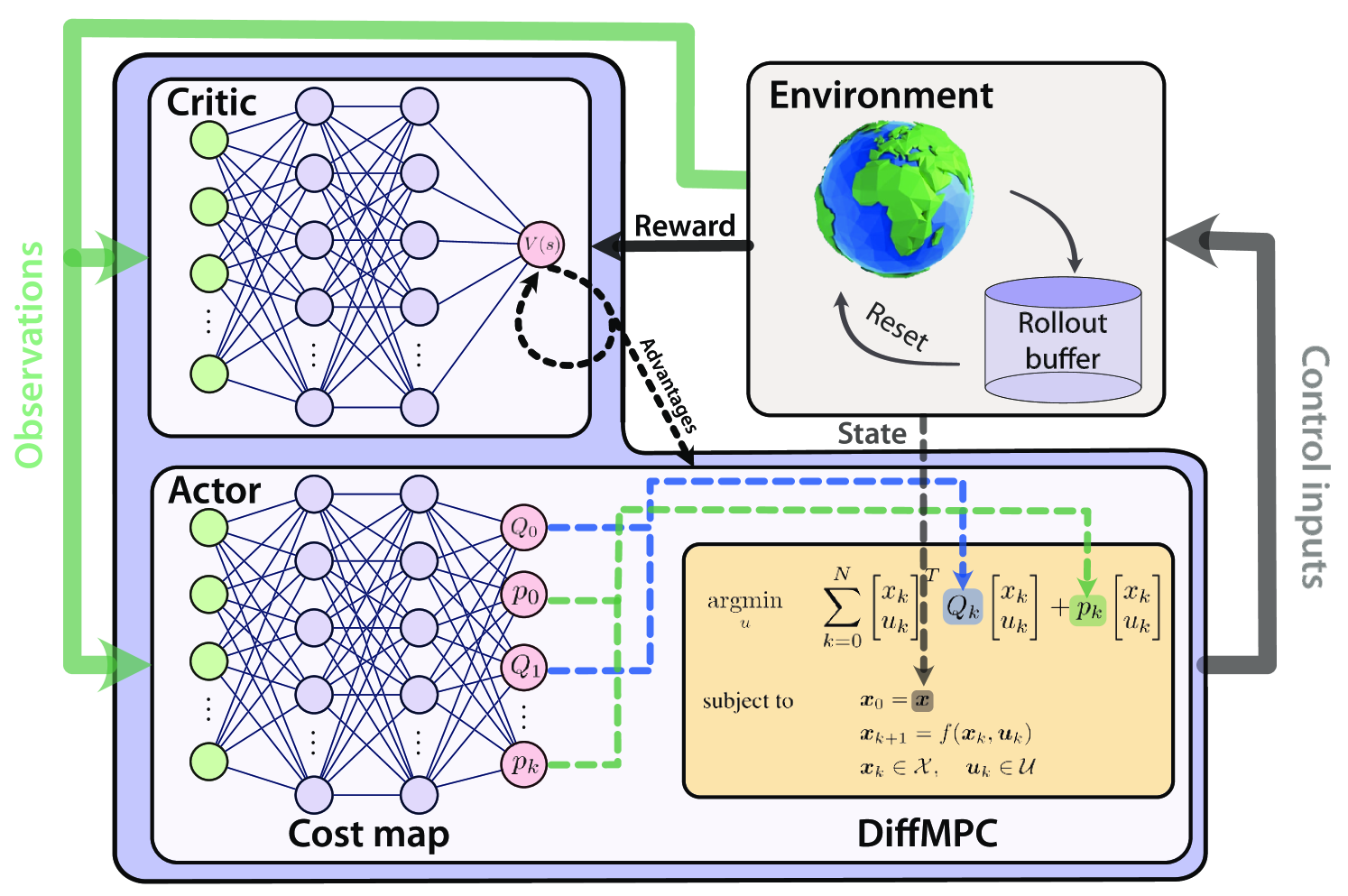
Ac{MPC} and ac{RL} are two powerful control strategies with, arguably, complementary advantages. In this work, we show how actor-critic ac{RL} techniques can be leveraged to improve the performance of ac{MPC}. The ac{RL} critic is used as an approximation of the optimal value function, and an actor roll-out provides an initial guess for primal variables of the ac{MPC}. A parallel control architecture is proposed where each ac{MPC} instance is solved twice for different initial guesses. Besides the actor roll-out initialization, a shifted initialization from the previous solution is used. Thereafter, the actor and the critic are again used to approximately evaluate the infinite horizon cost of these trajectories. The control actions from the lowest-cost trajectory are applied to the system at each time step. We establish that the proposed algorithm is guaranteed to outperform the original ac{RL} policy plus an error term that depends on the accuracy of the critic and decays with the horizon length of the ac{MPC} formulation. Moreover, we do not require globally optimal solutions for these guarantees to hold. The approach is demonstrated on an illustrative toy example and an ac{AD} overtaking scenario.
Create account to get full access
Overview
- This paper introduces a new reinforcement learning algorithm for nonlinear model predictive control (MPC) called AC4MPC (Actor-Critic for MPC).
- AC4MPC combines the strengths of actor-critic reinforcement learning and model predictive control to optimize control policies for complex, nonlinear systems.
- The researchers demonstrate the effectiveness of AC4MPC on several benchmark control problems and show that it outperforms traditional MPC approaches.
Plain English Explanation
AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control is a new algorithm that aims to improve the performance of model predictive control (MPC) for complex, nonlinear systems. MPC is a powerful technique for controlling dynamic systems, but it can be computationally intensive, especially for highly nonlinear problems.
The key idea behind AC4MPC is to combine reinforcement learning with MPC. Reinforcement learning is a type of machine learning where an agent (in this case, the control system) learns to make good decisions by trial-and-error, receiving rewards or penalties based on the outcomes of its actions. By incorporating reinforcement learning, AC4MPC can learn optimal control policies more efficiently than traditional MPC approaches.
Specifically, AC4MPC uses an "actor-critic" reinforcement learning architecture, which consists of two neural networks: an "actor" that selects actions, and a "critic" that evaluates the quality of those actions. The actor network learns to choose the best control actions, while the critic network provides feedback to the actor, helping it improve over time.
The researchers demonstrate the effectiveness of AC4MPC on several benchmark control problems, such as controlling the motion of a robot arm or the balance of an inverted pendulum. They show that AC4MPC outperforms traditional MPC methods, particularly for highly nonlinear systems where MPC can struggle.
Technical Explanation
AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control presents a new algorithm that combines the strengths of actor-critic reinforcement learning and model predictive control (MPC) to optimize control policies for complex, nonlinear systems.
The core idea of the algorithm is to use an "actor-critic" reinforcement learning architecture to learn the optimal control policy within the MPC framework. The actor network learns to select the best control actions, while the critic network evaluates the quality of those actions and provides feedback to the actor, helping it improve over time.
The researchers formulate the control problem as a Markov decision process and derive the necessary optimality conditions for the actor-critic learning process. They also propose a practical implementation of the algorithm, which includes techniques such as trust region optimization and constraint handling.
The effectiveness of AC4MPC is demonstrated on several benchmark control problems, including a robot arm, an inverted pendulum, and a quadrotor aircraft. The results show that AC4MPC outperforms traditional MPC approaches, particularly for highly nonlinear systems where MPC can struggle.
The authors also provide a finite-time analysis of the algorithm, proving its convergence and establishing performance guarantees.
Critical Analysis
The AC4MPC algorithm presented in this paper offers a promising approach to improving the performance of model predictive control for complex, nonlinear systems. By incorporating reinforcement learning, the algorithm can learn optimal control policies more efficiently than traditional MPC methods.
One potential limitation of the approach is the need for an accurate model of the system dynamics. While the authors demonstrate the algorithm's effectiveness on several benchmark problems, the performance may depend on the quality of the model used. In real-world applications, where modeling errors or uncertainties are present, the algorithm's performance may be affected.
Additionally, the authors note that the algorithm requires careful tuning of hyperparameters, such as the trust region size and the learning rates for the actor and critic networks. This fine-tuning process may be challenging, especially for inexperienced users.
Potential areas for further research include extending the algorithm to handle partial observability, incorporating adaptive horizon planning, and exploring the use of single-loop natural actor-critic methods to simplify the algorithm's implementation.
Conclusion
AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control presents a novel algorithm that combines the strengths of actor-critic reinforcement learning and model predictive control to optimize control policies for complex, nonlinear systems.
By leveraging the learning capabilities of reinforcement learning within the MPC framework, AC4MPC can outperform traditional MPC approaches, particularly on highly nonlinear control problems. The algorithm's ability to learn optimal control policies efficiently has the potential to unlock new applications and improve the performance of a wide range of dynamic systems.
While the algorithm requires careful tuning and may be sensitive to modeling errors, the authors' analysis and experimental results suggest that AC4MPC is a promising step forward in the field of nonlinear control optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
0
0
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
4/15/2024
Adaptive Actor-Critic Based Optimal Regulation for Drift-Free Uncertain Nonlinear Systems
Ashwin P. Dani, Shubhendu Bhasin
0
0
In this paper, a continuous-time adaptive actor-critic reinforcement learning (RL) controller is developed for drift-free nonlinear systems. Practical examples of such systems are image-based visual servoing (IBVS) and wheeled mobile robots (WMR), where the system dynamics includes a parametric uncertainty in the control effectiveness matrix with no drift term. The uncertainty in the input term poses a challenge for developing a continuous-time RL controller using existing methods. In this paper, an actor-critic or synchronous policy iteration (PI)-based RL controller is presented with a concurrent learning (CL)-based parameter update law for estimating the unknown parameters of the control effectiveness matrix. An infinite-horizon value function minimization objective is achieved by regulating the current states to the desired with near-optimal control efforts. The proposed controller guarantees closed-loop stability and simulation results validate the proposed theory using IBVS and WMR examples.
6/14/2024

Actor-Critic Reinforcement Learning with Phased Actor
Ruofan Wu, Junmin Zhong, Jennie Si
0
0
Policy gradient methods in actor-critic reinforcement learning (RL) have become perhaps the most promising approaches to solving continuous optimal control problems. However, the trial-and-error nature of RL and the inherent randomness associated with solution approximations cause variations in the learned optimal values and policies. This has significantly hindered their successful deployment in real life applications where control responses need to meet dynamic performance criteria deterministically. Here we propose a novel phased actor in actor-critic (PAAC) method, aiming at improving policy gradient estimation and thus the quality of the control policy. Specifically, PAAC accounts for both $Q$ value and TD error in its actor update. We prove qualitative properties of PAAC for learning convergence of the value and policy, solution optimality, and stability of system dynamics. Additionally, we show variance reduction in policy gradient estimation. PAAC performance is systematically and quantitatively evaluated in this study using DeepMind Control Suite (DMC). Results show that PAAC leads to significant performance improvement measured by total cost, learning variance, robustness, learning speed and success rate. As PAAC can be piggybacked onto general policy gradient learning frameworks, we select well-known methods such as direct heuristic dynamic programming (dHDP), deep deterministic policy gradient (DDPG) and their variants to demonstrate the effectiveness of PAAC. Consequently we provide a unified view on these related policy gradient algorithms.
4/19/2024
🗣️
Non-Asymptotic Analysis for Single-Loop (Natural) Actor-Critic with Compatible Function Approximation
Yudan Wang, Yue Wang, Yi Zhou, Shaofeng Zou
0
0
Actor-critic (AC) is a powerful method for learning an optimal policy in reinforcement learning, where the critic uses algorithms, e.g., temporal difference (TD) learning with function approximation, to evaluate the current policy and the actor updates the policy along an approximate gradient direction using information from the critic. This paper provides the textit{tightest} non-asymptotic convergence bounds for both the AC and natural AC (NAC) algorithms. Specifically, existing studies show that AC converges to an $epsilon+varepsilon_{text{critic}}$ neighborhood of stationary points with the best known sample complexity of $mathcal{O}(epsilon^{-2})$ (up to a log factor), and NAC converges to an $epsilon+varepsilon_{text{critic}}+sqrt{varepsilon_{text{actor}}}$ neighborhood of the global optimum with the best known sample complexity of $mathcal{O}(epsilon^{-3})$, where $varepsilon_{text{critic}}$ is the approximation error of the critic and $varepsilon_{text{actor}}$ is the approximation error induced by the insufficient expressive power of the parameterized policy class. This paper analyzes the convergence of both AC and NAC algorithms with compatible function approximation. Our analysis eliminates the term $varepsilon_{text{critic}}$ from the error bounds while still achieving the best known sample complexities. Moreover, we focus on the challenging single-loop setting with a single Markovian sample trajectory. Our major technical novelty lies in analyzing the stochastic bias due to policy-dependent and time-varying compatible function approximation in the critic, and handling the non-ergodicity of the MDP due to the single Markovian sample trajectory. Numerical results are also provided in the appendix.
6/5/2024