Adaptive Actor-Critic Based Optimal Regulation for Drift-Free Uncertain Nonlinear Systems
2406.09097
0
0
Abstract
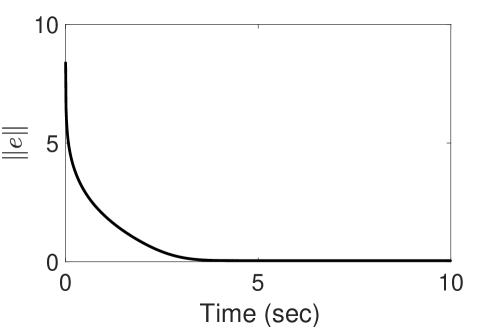
In this paper, a continuous-time adaptive actor-critic reinforcement learning (RL) controller is developed for drift-free nonlinear systems. Practical examples of such systems are image-based visual servoing (IBVS) and wheeled mobile robots (WMR), where the system dynamics includes a parametric uncertainty in the control effectiveness matrix with no drift term. The uncertainty in the input term poses a challenge for developing a continuous-time RL controller using existing methods. In this paper, an actor-critic or synchronous policy iteration (PI)-based RL controller is presented with a concurrent learning (CL)-based parameter update law for estimating the unknown parameters of the control effectiveness matrix. An infinite-horizon value function minimization objective is achieved by regulating the current states to the desired with near-optimal control efforts. The proposed controller guarantees closed-loop stability and simulation results validate the proposed theory using IBVS and WMR examples.
Create account to get full access
Overview
- This paper introduces an adaptive actor-critic based method for optimal regulation of uncertain, drift-free nonlinear systems.
- The proposed approach uses reinforcement learning to learn an optimal control policy, without requiring a precise model of the system dynamics.
- The method is designed to handle nonlinearity, uncertainty, and the lack of a known drift term in the system dynamics.
Plain English Explanation
The paper presents a new way to control complex, uncertain systems using reinforcement learning. Many real-world systems, like robots or chemical processes, have nonlinear and uncertain dynamics that are difficult to model precisely. Traditional control methods often struggle with these challenges.
The researchers developed an "actor-critic" reinforcement learning algorithm that can learn an optimal control policy for the system, without needing to know the exact details of how the system works. The "actor" part learns how to take good actions, while the "critic" evaluates how well those actions are performing. By iteratively improving the actor based on the critic's feedback, the algorithm converges to an optimal control strategy.
Importantly, the method can handle systems that lack a known "drift" term - a constant force or bias in the dynamics. This makes it applicable to a wider range of real-world scenarios. Overall, the adaptive actor-critic approach promises more robust and effective control for complex, uncertain nonlinear systems.
Technical Explanation
The paper presents an adaptive actor-critic based optimal regulation method for controlling drift-free, uncertain nonlinear systems. The key idea is to learn an optimal control policy through reinforcement learning, without requiring precise knowledge of the system dynamics.
The system model is described as a drift-free, uncertain nonlinear system with control inputs. The control objective is to regulate the system state to a desired reference state, while minimizing a quadratic cost function. The researchers develop an adaptive actor-critic algorithm to solve this optimal regulation problem.
The actor network learns the optimal control policy, while the critic network estimates the associated value function. By iteratively updating the actor based on the critic's evaluation, the algorithm converges to an optimal control strategy. Importantly, the method does not require knowledge of the drift term in the system dynamics, making it applicable to a broader class of nonlinear systems.
The paper includes theoretical analysis to establish the stability and convergence properties of the proposed approach. Numerical simulations on various nonlinear systems demonstrate the efficacy of the actor-critic based model-free reinforcement learning method for optimal regulation of drift-free uncertain nonlinear systems.
Critical Analysis
The paper presents a promising approach for adaptive optimal control of complex, uncertain nonlinear systems. The ability to learn an optimal control policy without precise knowledge of the system dynamics is a significant advantage over traditional control methods.
However, the paper does not address the sample efficiency of the reinforcement learning algorithm. In many real-world applications, the system may not be able to tolerate a large number of exploratory actions during the learning process. Actor-critic methods have been shown to be data-efficient in some settings, but the scalability and practicality of the proposed approach for large-scale systems remains an open question.
Additionally, the theoretical analysis focuses on establishing stability and convergence properties, but does not provide deeper insights into the factors that influence the performance of the algorithm. Further research could explore the sensitivity of the method to hyperparameter choices, the impact of system complexity and uncertainty levels, and potential strategies to improve sample efficiency and robustness.
Conclusion
This paper introduces an adaptive actor-critic based method for optimal regulation of drift-free, uncertain nonlinear systems. The key innovation is the ability to learn an optimal control policy through reinforcement learning, without requiring precise knowledge of the system dynamics.
The proposed approach promises more robust and effective control for a wide range of complex, real-world systems with nonlinear and uncertain characteristics. While the theoretical analysis and numerical simulations are promising, further research is needed to address practical concerns such as sample efficiency and scalability to larger-scale systems.
Overall, this work contributes to the growing body of research on data-driven, model-free reinforcement learning methods for optimal control, with the potential to unlock new applications in areas like robotics, process control, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control
Rudolf Reiter, Andrea Ghezzi, Katrin Baumgartner, Jasper Hoffmann, Robert D. McAllister, Moritz Diehl
0
0
Ac{MPC} and ac{RL} are two powerful control strategies with, arguably, complementary advantages. In this work, we show how actor-critic ac{RL} techniques can be leveraged to improve the performance of ac{MPC}. The ac{RL} critic is used as an approximation of the optimal value function, and an actor roll-out provides an initial guess for primal variables of the ac{MPC}. A parallel control architecture is proposed where each ac{MPC} instance is solved twice for different initial guesses. Besides the actor roll-out initialization, a shifted initialization from the previous solution is used. Thereafter, the actor and the critic are again used to approximately evaluate the infinite horizon cost of these trajectories. The control actions from the lowest-cost trajectory are applied to the system at each time step. We establish that the proposed algorithm is guaranteed to outperform the original ac{RL} policy plus an error term that depends on the accuracy of the critic and decays with the horizon length of the ac{MPC} formulation. Moreover, we do not require globally optimal solutions for these guarantees to hold. The approach is demonstrated on an illustrative toy example and an ac{AD} overtaking scenario.
6/7/2024
🚀
ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
Kai-Chieh Hsu, Duy Phuong Nguyen, Jaime Fern'andez Fisac
0
0
The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable deep methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial disturbance agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
6/11/2024

Adaptive Robust Controller for handling Unknown Uncertainty of Robotic Manipulators
Mohamed Abdelwahab, Giulio Giacomuzzo, Alberto Dalla Libera, Ruggero Carli
0
0
The ability to achieve precise and smooth trajectory tracking is crucial for ensuring the successful execution of various tasks involving robotic manipulators. State-of-the-art techniques require accurate mathematical models of the robot dynamics, and robustness to model uncertainties is achieved by relying on precise bounds on the model mismatch. In this paper, we propose a novel adaptive robust feedback linearization scheme able to compensate for model uncertainties without any a-priori knowledge on them, and we provide a theoretical proof of convergence under mild assumptions. We evaluate the method on a simulated RR robot. First, we consider a nominal model with known model mismatch, which allows us to compare our strategy with state-of-the-art uncertainty-aware methods. Second, we implement the proposed control law in combination with a learned model, for which uncertainty bounds are not available. Results show that our method leads to performance comparable to uncertainty-aware methods while requiring less prior knowledge.
6/21/2024
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
0
0
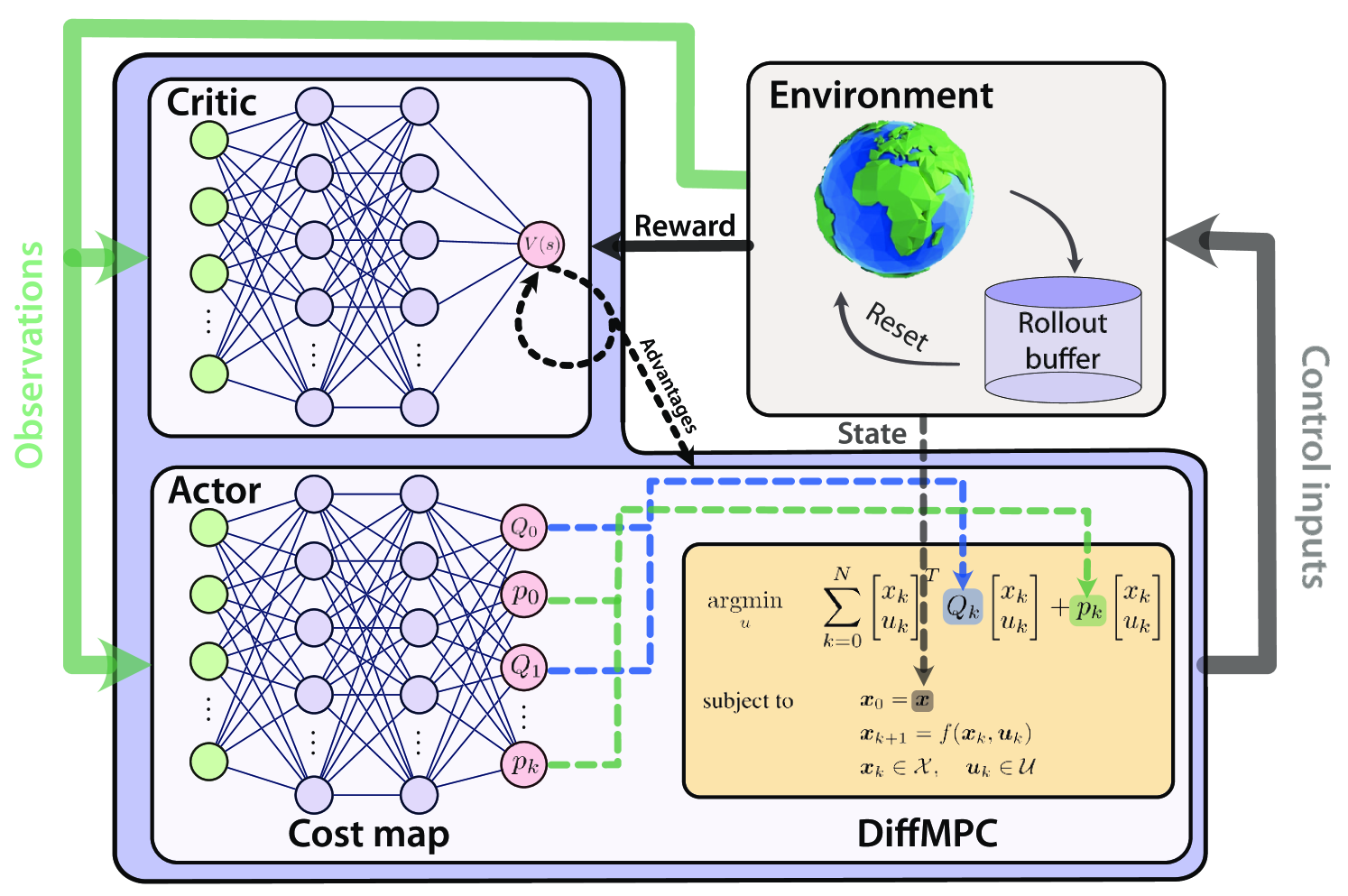
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
4/15/2024