Actor-Critic Reinforcement Learning with Phased Actor
2404.11834
0
0

Abstract
Policy gradient methods in actor-critic reinforcement learning (RL) have become perhaps the most promising approaches to solving continuous optimal control problems. However, the trial-and-error nature of RL and the inherent randomness associated with solution approximations cause variations in the learned optimal values and policies. This has significantly hindered their successful deployment in real life applications where control responses need to meet dynamic performance criteria deterministically. Here we propose a novel phased actor in actor-critic (PAAC) method, aiming at improving policy gradient estimation and thus the quality of the control policy. Specifically, PAAC accounts for both $Q$ value and TD error in its actor update. We prove qualitative properties of PAAC for learning convergence of the value and policy, solution optimality, and stability of system dynamics. Additionally, we show variance reduction in policy gradient estimation. PAAC performance is systematically and quantitatively evaluated in this study using DeepMind Control Suite (DMC). Results show that PAAC leads to significant performance improvement measured by total cost, learning variance, robustness, learning speed and success rate. As PAAC can be piggybacked onto general policy gradient learning frameworks, we select well-known methods such as direct heuristic dynamic programming (dHDP), deep deterministic policy gradient (DDPG) and their variants to demonstrate the effectiveness of PAAC. Consequently we provide a unified view on these related policy gradient algorithms.
Create account to get full access
Overview
- This paper presents a novel actor-critic reinforcement learning algorithm called "Phased Actor" that aims to improve the performance and stability of continuous control tasks.
- The key idea is to separate the actor and critic updates into two phases, allowing the critic to learn a better value function before the actor updates its policy.
- The authors demonstrate the effectiveness of their approach on several benchmark continuous control tasks, showing improved sample efficiency and final performance compared to existing methods.
Plain English Explanation
In reinforcement learning, an "actor-critic" algorithm is often used to solve continuous control problems, such as controlling a robot or navigating a complex environment. The actor determines the best actions to take, while the critic evaluates how good those actions are.
The Phased Actor algorithm introduced in this paper aims to improve the performance and stability of these actor-critic methods. The key insight is to split the update process into two distinct phases: first, the critic is trained to learn a better estimate of the value function (how good each state is); then, the actor is updated to take actions that maximize this improved value function.
By separating the actor and critic updates, the Phased Actor method allows the critic to converge to a more accurate value function before the actor starts making changes to the policy. This can lead to faster learning and more stable performance, as the actor has a clearer signal to follow.
The authors test their Phased Actor approach on several standard continuous control benchmarks, such as Mujoco and Roboschool environments. They show that it outperforms existing actor-critic methods in terms of sample efficiency (how quickly it learns) and final performance on these tasks.
Technical Explanation
The Phased Actor algorithm builds upon the standard actor-critic framework, where the actor (policy network) determines the best actions to take, and the critic (value network) estimates the value of those actions.
The key innovation is to separate the actor and critic updates into two distinct phases. In the first phase, the critic is trained to convergence using temporal difference (TD) learning to estimate the value function. In the second phase, the actor is updated using policy gradient methods to maximize the improved value function.
This decoupling of the actor and critic updates allows the critic to learn a more accurate value function before the actor starts making changes to the policy. The authors argue that this can lead to faster learning and more stable performance, as the actor has a clearer signal to follow.
The Phased Actor algorithm is evaluated on several continuous control benchmarks, including Mujoco and Roboschool environments. The results show that Phased Actor outperforms existing actor-critic methods, such as DDPG and TD3, in terms of sample efficiency and final performance.
Critical Analysis
The Phased Actor algorithm seems to be a promising approach for improving the stability and performance of actor-critic reinforcement learning methods. The key insight of separating the actor and critic updates is well-motivated and the experimental results are compelling.
However, the paper does not discuss the potential limitations or caveats of the Phased Actor approach. For example, it's unclear how the method would scale to more complex, high-dimensional control problems, or how sensitive it is to hyperparameter tuning.
Additionally, the authors do not provide a detailed theoretical analysis of why the Phased Actor algorithm should outperform standard actor-critic methods. While the empirical results are promising, a more rigorous theoretical understanding of the method's properties would strengthen the overall contribution.
Overall, the Phased Actor algorithm is a interesting and potentially impactful contribution to the field of reinforcement learning for continuous control tasks. However, further research is needed to fully understand its limitations and broader applicability.
Conclusion
The Phased Actor algorithm presented in this paper introduces a novel approach to actor-critic reinforcement learning that separates the actor and critic updates into two distinct phases. This decoupling allows the critic to learn a more accurate value function before the actor updates its policy, leading to improved performance and stability on continuous control tasks.
The experimental results on standard benchmarks are promising, showing that Phased Actor outperforms existing methods in terms of sample efficiency and final performance. While the paper does not address potential limitations or provide a detailed theoretical analysis, the core idea is compelling and could have significant implications for the field of reinforcement learning for continuous control problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤷
PAC-Bayesian Soft Actor-Critic Learning
Bahareh Tasdighi, Abdullah Akgul, Manuel Haussmann, Kenny Kazimirzak Brink, Melih Kandemir
0
0
Actor-critic algorithms address the dual goals of reinforcement learning (RL), policy evaluation and improvement via two separate function approximators. The practicality of this approach comes at the expense of training instability, caused mainly by the destructive effect of the approximation errors of the critic on the actor. We tackle this bottleneck by employing an existing Probably Approximately Correct (PAC) Bayesian bound for the first time as the critic training objective of the Soft Actor-Critic (SAC) algorithm. We further demonstrate that online learning performance improves significantly when a stochastic actor explores multiple futures by critic-guided random search. We observe our resulting algorithm to compare favorably against the state-of-the-art SAC implementation on multiple classical control and locomotion tasks in terms of both sample efficiency and regret.
6/11/2024

AC4MPC: Actor-Critic Reinforcement Learning for Nonlinear Model Predictive Control
Rudolf Reiter, Andrea Ghezzi, Katrin Baumgartner, Jasper Hoffmann, Robert D. McAllister, Moritz Diehl
0
0
Ac{MPC} and ac{RL} are two powerful control strategies with, arguably, complementary advantages. In this work, we show how actor-critic ac{RL} techniques can be leveraged to improve the performance of ac{MPC}. The ac{RL} critic is used as an approximation of the optimal value function, and an actor roll-out provides an initial guess for primal variables of the ac{MPC}. A parallel control architecture is proposed where each ac{MPC} instance is solved twice for different initial guesses. Besides the actor roll-out initialization, a shifted initialization from the previous solution is used. Thereafter, the actor and the critic are again used to approximately evaluate the infinite horizon cost of these trajectories. The control actions from the lowest-cost trajectory are applied to the system at each time step. We establish that the proposed algorithm is guaranteed to outperform the original ac{RL} policy plus an error term that depends on the accuracy of the critic and decays with the horizon length of the ac{MPC} formulation. Moreover, we do not require globally optimal solutions for these guarantees to hold. The approach is demonstrated on an illustrative toy example and an ac{AD} overtaking scenario.
6/7/2024

Value Improved Actor Critic Algorithms
Yaniv Oren, Moritz A. Zanger, Pascal R. van der Vaart, Matthijs T. J. Spaan, Wendelin Bohmer
0
0
Many modern reinforcement learning algorithms build on the actor-critic (AC) framework: iterative improvement of a policy (the actor) using policy improvement operators and iterative approximation of the policy's value (the critic). In contrast, the popular value-based algorithm family employs improvement operators in the value update, to iteratively improve the value function directly. In this work, we propose a general extension to the AC framework that employs two separate improvement operators: one applied to the policy in the spirit of policy-based algorithms and one applied to the value in the spirit of value-based algorithms, which we dub Value-Improved AC (VI-AC). We design two practical VI-AC algorithms based in the popular online off-policy AC algorithms TD3 and DDPG. We evaluate VI-TD3 and VI-DDPG in the Mujoco benchmark and find that both improve upon or match the performance of their respective baselines in all environments tested.
6/4/2024
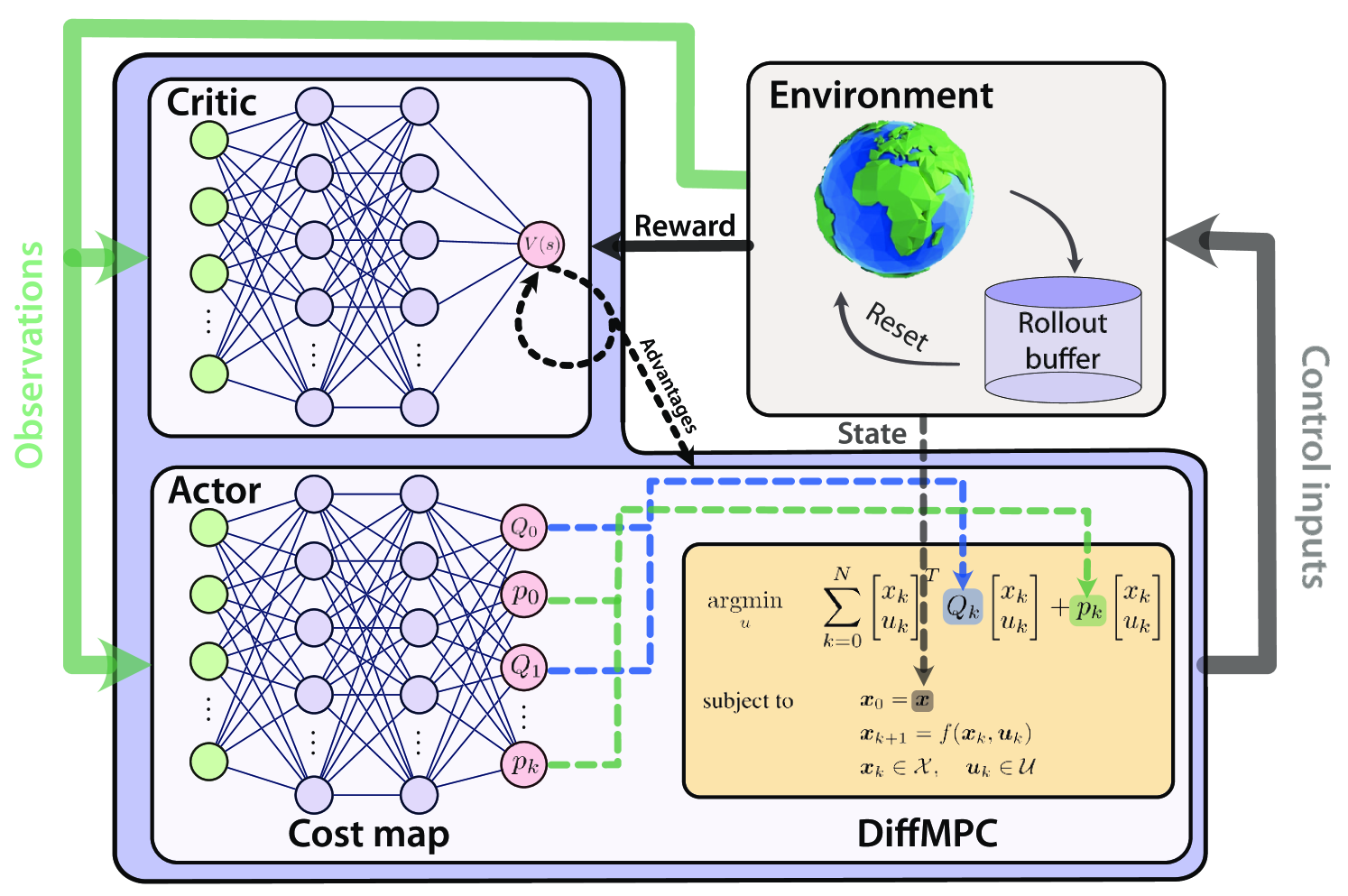
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
0
0
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
4/15/2024