Accelerating Transformer Pre-Training with 2:4 Sparsity
2404.01847
0
0

Abstract
Training large Transformers is slow, but recent innovations on GPU architecture gives us an advantage. NVIDIA Ampere GPUs can execute a fine-grained 2:4 sparse matrix multiplication twice as fast as its dense equivalent. In the light of this property, we comprehensively investigate the feasibility of accelerating feed-forward networks (FFNs) of Transformers in pre-training. First, we define a flip rate to monitor the stability of a 2:4 training process. Utilizing this metric, we suggest two techniques to preserve accuracy: to modify the sparse-refined straight-through estimator by applying the mask decay term on gradients, and to enhance the model's quality by a simple yet effective dense fine-tuning procedure near the end of pre-training. Besides, we devise two effective techniques to practically accelerate training: to calculate transposable 2:4 mask by convolution, and to accelerate gated activation functions by reducing GPU L2 cache miss. Experiments show that a combination of our methods reaches the best performance on multiple Transformers among different 2:4 training methods, while actual acceleration can be observed on different shapes of Transformer block.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a new approach called "2:4 Sparsity" to accelerate the pre-training of Transformer models.
- The authors demonstrate that their technique can significantly speed up the pre-training process while maintaining comparable performance to dense models.
- The key innovation is a sparse attention mechanism that reduces computation and memory requirements during pre-training.
Plain English Explanation
The Transformer is a powerful artificial intelligence model that has revolutionized natural language processing. However, training these models from scratch requires a massive amount of computational power and time. This can be a bottleneck, especially for researchers and organizations with limited resources.
The authors of this paper have come up with a clever solution to this problem. They introduced a new approach called "2:4 Sparsity" that can significantly speed up the pre-training of Transformer models. The key idea is to use a sparse attention mechanism, which means that the model only needs to calculate attention between a subset of the input tokens, rather than all of them.
Imagine you're trying to understand a long and complex text. Instead of reading every single word, you might skim through and only focus on the most important ones. That's similar to what the 2:4 Sparsity approach does - it allows the Transformer model to focus on the most relevant parts of the input, rather than wasting time and resources on less important information.
By using this sparse attention mechanism, the authors were able to reduce the computational and memory requirements of the pre-training process, without significantly impacting the model's performance. This means that researchers and companies can now train powerful Transformer models much more efficiently, opening up new possibilities for applying these models in a wide range of applications.
Technical Explanation
The paper introduces a new sparse attention mechanism called "2:4 Sparsity" that can be applied to Transformer models during the pre-training stage. In a standard Transformer, the attention mechanism calculates a weighted sum of all the input tokens to determine the representation of each output token.
The 2:4 Sparsity approach modifies this by only calculating attention between a subset of the input tokens. Specifically, it selects the 2 most relevant tokens from the query and the 4 most relevant tokens from the key, reducing the overall computation and memory usage.
The authors conducted extensive experiments to evaluate the effectiveness of this approach. They pre-trained Transformer models on large-scale language modeling tasks and compared the performance of the 2:4 Sparse models to their dense counterparts. The results showed that the sparse models were able to achieve comparable or even better performance, while being significantly faster and more memory-efficient during pre-training.
Critical Analysis
The authors have done a thorough job of evaluating their 2:4 Sparsity approach and demonstrating its effectiveness. The experiments are well-designed and the results are compelling. However, there are a few potential limitations and areas for further research that could be considered:
-
The paper focuses on the pre-training stage of Transformer models, but does not explore the impact of the sparse attention mechanism on fine-tuning or downstream task performance. It would be interesting to see how the sparse models perform in real-world applications.
-
The 2:4 Sparsity ratio was chosen based on empirical findings, but the authors do not provide a principled justification for this specific ratio. Exploring different sparsity patterns or adaptive sparsity mechanisms could potentially lead to further improvements.
-
The experiments were conducted on standard language modeling benchmarks, but it's unclear how the 2:4 Sparsity approach would perform on more specialized or domain-specific tasks. Further testing in diverse application areas would help validate the generalizability of the technique.
Overall, the 2:4 Sparsity approach presented in this paper is a promising step towards more efficient Transformer pre-training, and the authors have done a commendable job in demonstrating its merits. Continued research in this direction could lead to even more significant advancements in the field of natural language processing.
Conclusion
This paper introduces a novel sparse attention mechanism called "2:4 Sparsity" that can significantly accelerate the pre-training of Transformer models. By selectively calculating attention between a subset of the input tokens, the authors were able to reduce the computational and memory requirements of the pre-training process without sacrificing model performance.
The results of their experiments are highly encouraging, showing that the 2:4 Sparse Transformer models can match or even outperform their dense counterparts while being much faster and more memory-efficient. This breakthrough has the potential to unlock new possibilities for applying Transformer models in a wide range of applications, particularly for researchers and organizations with limited computational resources.
As the field of natural language processing continues to evolve, innovative approaches like 2:4 Sparsity will play a crucial role in making powerful AI models more accessible and practical for real-world use. The insights and techniques presented in this paper represent an important step forward in the ongoing quest to develop more efficient and effective Transformer architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Multi-Level Framework for Accelerating Training Transformer Models
Longwei Zou, Han Zhang, Yangdong Deng
0
0
The fast growing capabilities of large-scale deep learning models, such as Bert, GPT and ViT, are revolutionizing the landscape of NLP, CV and many other domains. Training such models, however, poses an unprecedented demand for computing power, which incurs exponentially increasing energy cost and carbon dioxide emissions. It is thus critical to develop efficient training solutions to reduce the training costs. Motivated by a set of key observations of inter- and intra-layer similarities among feature maps and attentions that can be identified from typical training processes, we propose a multi-level framework for training acceleration. Specifically, the framework is based on three basic operators, Coalescing, De-coalescing and Interpolation, which can be orchestrated to build a multi-level training framework. The framework consists of a V-cycle training process, which progressively down- and up-scales the model size and projects the parameters between adjacent levels of models via coalescing and de-coalescing. The key idea is that a smaller model that can be trained for fast convergence and the trained parameters provides high-qualities intermediate solutions for the next level larger network. The interpolation operator is designed to break the symmetry of neurons incurred by de-coalescing for better convergence performance. Our experiments on transformer-based language models (e.g. Bert, GPT) as well as a vision model (e.g. DeiT) prove that the proposed framework reduces the computational cost by about 20% on training BERT/GPT-Base models and up to 51.6% on training the BERT-Large model while preserving the performance.
4/15/2024
💬
Masked Structural Growth for 2x Faster Language Model Pre-training
Yiqun Yao, Zheng Zhang, Jing Li, Yequan Wang
0
0
Accelerating large language model pre-training is a critical issue in present research. In this paper, we focus on speeding up pre-training by progressively growing from a small Transformer structure to a large one. There are two main research problems associated with progressive growth: determining the optimal growth schedule, and designing efficient growth operators. In terms of growth schedule, the impact of each single dimension on a schedule's efficiency is under-explored by existing work. Regarding the growth operators, existing methods rely on the initialization of new weights to inherit knowledge, and achieve only non-strict function preservation, limiting further improvements on training dynamics. To address these issues, we propose Masked Structural Growth (MSG), including (i) growth schedules involving all possible dimensions and (ii) strictly function-preserving growth operators that is independent of the initialization of new weights. Experiments show that MSG is significantly faster than related work: we achieve up to 2.2x speedup in pre-training different types of language models while maintaining comparable or better downstream performances. Code is publicly available at https://github.com/cofe-ai/MSG.
4/9/2024
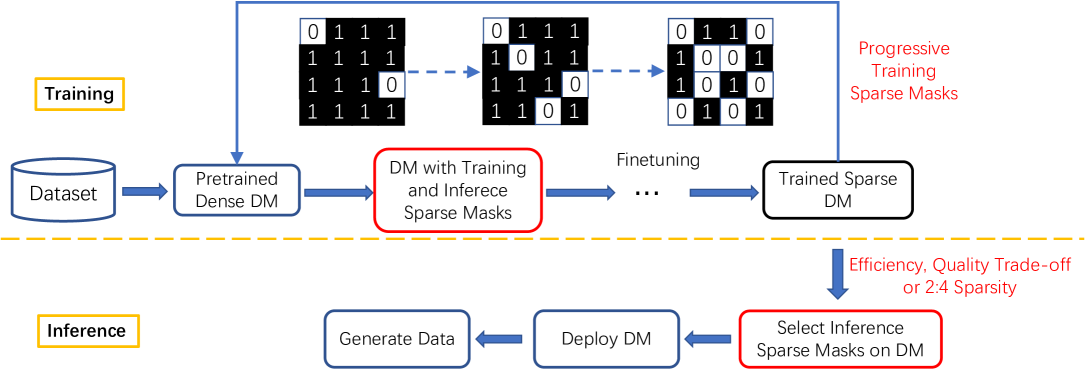
SparseDM: Toward Sparse Efficient Diffusion Models
Kafeng Wang, Jianfei Chen, He Li, Zhenpeng Mi, Jun Zhu
0
0
Diffusion models have been extensively used in data generation tasks and are recognized as one of the best generative models. However, their time-consuming deployment, long inference time, and requirements on large memory limit their application on mobile devices. In this paper, we propose a method based on the improved Straight-Through Estimator to improve the deployment efficiency of diffusion models. Specifically, we add sparse masks to the Convolution and Linear layers in a pre-trained diffusion model, then use design progressive sparsity for model training in the fine-tuning stage, and switch the inference mask on and off, which supports a flexible choice of sparsity during inference according to the FID and MACs requirements. Experiments on four datasets conducted on a state-of-the-art Transformer-based diffusion model demonstrate that our method reduces MACs by $50%$ while increasing FID by only 1.5 on average. Under other MACs conditions, the FID is also lower than 1$sim$137 compared to other methods.
4/17/2024
🔍
A 4D Hybrid Algorithm to Scale Parallel Training to Thousands of GPUs
Siddharth Singh, Prajwal Singhania, Aditya K. Ranjan, Zack Sating, Abhinav Bhatele
0
0
Heavy communication, in particular, collective operations, can become a critical performance bottleneck in scaling the training of billion-parameter neural networks to large-scale parallel systems. This paper introduces a four-dimensional (4D) approach to optimize communication in parallel training. This 4D approach is a hybrid of 3D tensor and data parallelism, and is implemented in the AxoNN framework. In addition, we employ two key strategies to further minimize communication overheads. First, we aggressively overlap expensive collective operations (reduce-scatter, all-gather, and all-reduce) with computation. Second, we develop an analytical model to identify high-performing configurations within the large search space defined by our 4D algorithm. This model empowers practitioners by simplifying the tuning process for their specific training workloads. When training an 80-billion parameter GPT on 1024 GPUs of Perlmutter, AxoNN surpasses Megatron-LM, a state-of-the-art framework, by a significant 26%. Additionally, it achieves a significantly high 57% of the theoretical peak FLOP/s or 182 PFLOP/s in total.
5/15/2024