A Multi-Level Framework for Accelerating Training Transformer Models
2404.07999
0
0
Abstract
The fast growing capabilities of large-scale deep learning models, such as Bert, GPT and ViT, are revolutionizing the landscape of NLP, CV and many other domains. Training such models, however, poses an unprecedented demand for computing power, which incurs exponentially increasing energy cost and carbon dioxide emissions. It is thus critical to develop efficient training solutions to reduce the training costs. Motivated by a set of key observations of inter- and intra-layer similarities among feature maps and attentions that can be identified from typical training processes, we propose a multi-level framework for training acceleration. Specifically, the framework is based on three basic operators, Coalescing, De-coalescing and Interpolation, which can be orchestrated to build a multi-level training framework. The framework consists of a V-cycle training process, which progressively down- and up-scales the model size and projects the parameters between adjacent levels of models via coalescing and de-coalescing. The key idea is that a smaller model that can be trained for fast convergence and the trained parameters provides high-qualities intermediate solutions for the next level larger network. The interpolation operator is designed to break the symmetry of neurons incurred by de-coalescing for better convergence performance. Our experiments on transformer-based language models (e.g. Bert, GPT) as well as a vision model (e.g. DeiT) prove that the proposed framework reduces the computational cost by about 20% on training BERT/GPT-Base models and up to 51.6% on training the BERT-Large model while preserving the performance.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper proposes a multi-level framework to accelerate the training of Transformer models, which are widely used in natural language processing tasks.
- The framework leverages various techniques, including sparse attention, gradient checkpoint, and layer-wise adaptive gradient clipping, to improve the efficiency of training large Transformer models.
- The authors demonstrate the effectiveness of their approach through extensive experiments on several popular Transformer-based models, such as BERT and T5.
Plain English Explanation
The paper describes a new way to train large Transformer models more efficiently. Transformer models are a type of neural network that have become very popular for natural language processing tasks, such as language translation and text generation. However, training these models can be very computationally expensive and time-consuming, especially as the models get larger and more complex.
The researchers developed a multi-level framework for accelerating Transformer model training. This framework combines several different techniques to make the training process more efficient. For example, it uses sparse attention to reduce the amount of computation required, and gradient checkpointing to save memory during training.
The authors tested their framework on several popular Transformer-based models, such as BERT and T5, and showed that it could significantly speed up the training process without affecting the models' performance. This is an important advance because it could make it easier and cheaper to train large, powerful Transformer models for a wide range of natural language processing applications.
Technical Explanation
The paper proposes a multi-level framework for accelerating the training of Transformer models. The framework consists of several key components:
-
Sparse Attention: The authors use a sparse attention mechanism to reduce the computational complexity of the attention layer in Transformer models. This involves selectively updating only a subset of the attention weights during each forward and backward pass, which can significantly reduce the amount of computation required.
-
Gradient Checkpoint: The researchers employ gradient checkpointing to save memory during training. This technique involves recomputing the activations during the backward pass rather than storing them during the forward pass, which can reduce the memory footprint of the model.
-
Layer-wise Adaptive Gradient Clipping: The authors introduce a layer-wise adaptive gradient clipping mechanism to stabilize the training process. This helps to prevent exploding gradients, which can occur in large Transformer models and lead to training instability.
The authors evaluate their framework on several popular Transformer-based models, including BERT and T5, across a variety of natural language processing tasks. The results demonstrate that their approach can achieve significant training speedups, in some cases reducing the training time by more than 50%, without compromising the models' performance.
Critical Analysis
The paper presents a compelling approach for accelerating the training of Transformer models, which are increasingly important in various natural language processing applications. The authors' multi-level framework leverages several well-established techniques, such as sparse attention and gradient checkpointing, to improve the efficiency of the training process.
One potential limitation of the proposed approach is that it may not be equally effective across all types of Transformer models and tasks. The authors focus on a few popular models, such as BERT and T5, but it's unclear how the framework would perform on other Transformer architectures or on more specialized tasks.
Additionally, the paper does not provide a detailed analysis of the trade-offs between the various techniques employed in the framework. For example, while sparse attention can significantly reduce computational complexity, it may also impact the model's performance in certain cases. A more in-depth discussion of these trade-offs would help readers better understand the strengths and limitations of the proposed approach.
Despite these minor limitations, the paper represents an important contribution to the field of Transformer model optimization. The authors' multi-level framework has the potential to make the training of large, powerful Transformer models more accessible and cost-effective, which could ultimately benefit a wide range of natural language processing applications.
Conclusion
The paper presents a multi-level framework for accelerating the training of Transformer models, which are widely used in natural language processing tasks. The framework leverages techniques such as sparse attention, gradient checkpoint, and layer-wise adaptive gradient clipping to improve the efficiency of the training process.
The authors demonstrate the effectiveness of their approach through extensive experiments on popular Transformer-based models, such as BERT and T5. The results show that the proposed framework can significantly reduce the training time without compromising the models' performance.
This work represents an important step forward in the optimization of Transformer models, which are becoming increasingly crucial in a wide range of natural language processing applications. By making the training of these powerful models more efficient and accessible, the authors' framework has the potential to drive further advancements in the field and enable new and innovative applications.
Related Papers
🤯
Enhancing Inference Efficiency of Large Language Models: Investigating Optimization Strategies and Architectural Innovations
Georgy Tyukin
0
0
Large Language Models are growing in size, and we expect them to continue to do so, as larger models train quicker. However, this increase in size will severely impact inference costs. Therefore model compression is important, to retain the performance of larger models, but with a reduced cost of running them. In this thesis we explore the methods of model compression, and we empirically demonstrate that the simple method of skipping latter attention sublayers in Transformer LLMs is an effective method of model compression, as these layers prove to be redundant, whilst also being incredibly computationally expensive. We observed a 21% speed increase in one-token generation for Llama 2 7B, whilst surprisingly and unexpectedly improving performance over several common benchmarks.
4/10/2024
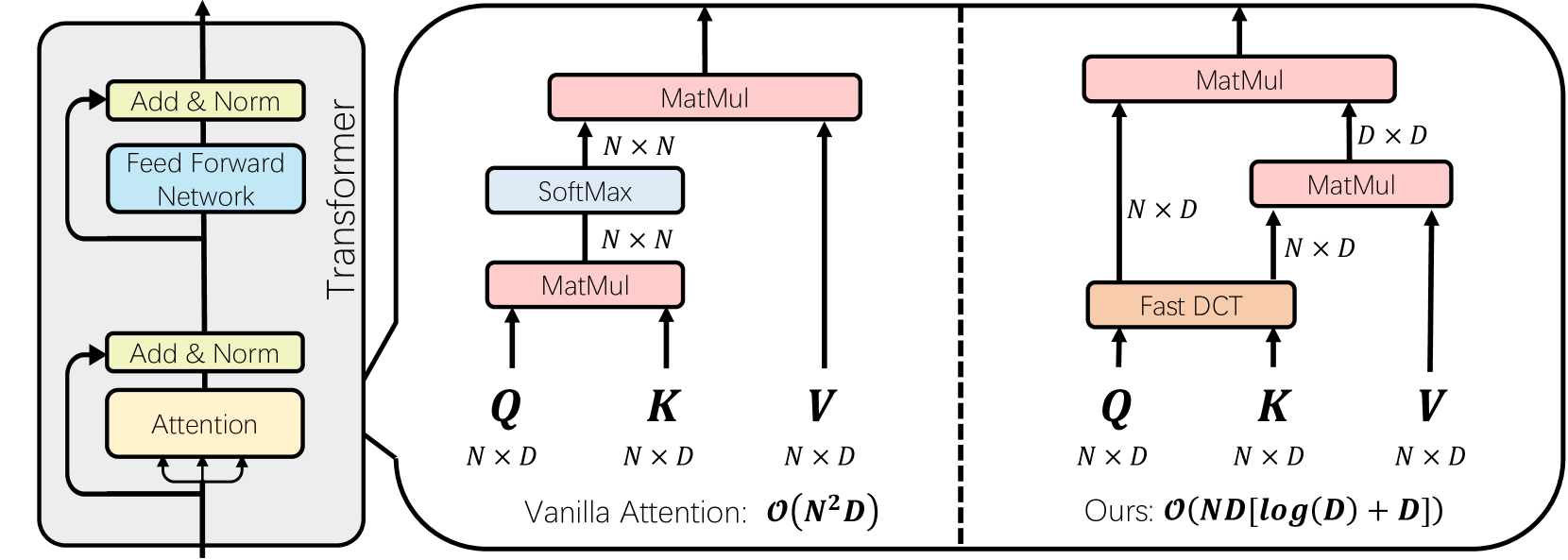
DiJiang: Efficient Large Language Models through Compact Kernelization
Hanting Chen, Zhicheng Liu, Xutao Wang, Yuchuan Tian, Yunhe Wang
0
0
In an effort to reduce the computational load of Transformers, research on linear attention has gained significant momentum. However, the improvement strategies for attention mechanisms typically necessitate extensive retraining, which is impractical for large language models with a vast array of parameters. In this paper, we present DiJiang, a novel Frequency Domain Kernelization approach that enables the transformation of a pre-trained vanilla Transformer into a linear complexity model with little training costs. By employing a weighted Quasi-Monte Carlo method for sampling, the proposed approach theoretically offers superior approximation efficiency. To further reduce the training computational complexity, our kernelization is based on Discrete Cosine Transform (DCT) operations. Extensive experiments demonstrate that the proposed method achieves comparable performance to the original Transformer, but with significantly reduced training costs and much faster inference speeds. Our DiJiang-7B achieves comparable performance with LLaMA2-7B on various benchmark while requires only about 1/50 training cost. Code is available at https://github.com/YuchuanTian/DiJiang.
4/1/2024
🏷️
Towards smallers, faster decoder-only transformers: Architectural variants and their implications
Sathya Krishnan Suresh, Shunmugapriya P
0
0
Research on Large Language Models (LLMs) has recently seen exponential growth, largely focused on transformer-based architectures, as introduced by [1] and further advanced by the decoder-only variations in [2]. Contemporary studies typically aim to improve model capabilities by increasing both the architecture's complexity and the volume of training data. However, research exploring how to reduce model sizes while maintaining performance is limited. This study introduces three modifications to the decoder-only transformer architecture: ParallelGPT (p-gpt), LinearlyCompressedGPT (lc-gpt), and ConvCompressedGPT (cc-gpt). These variants achieve comparable performance to conventional architectures in code generation tasks while benefiting from reduced model sizes and faster training times. We open-source the model weights and codebase to support future research and development in this domain.
4/24/2024
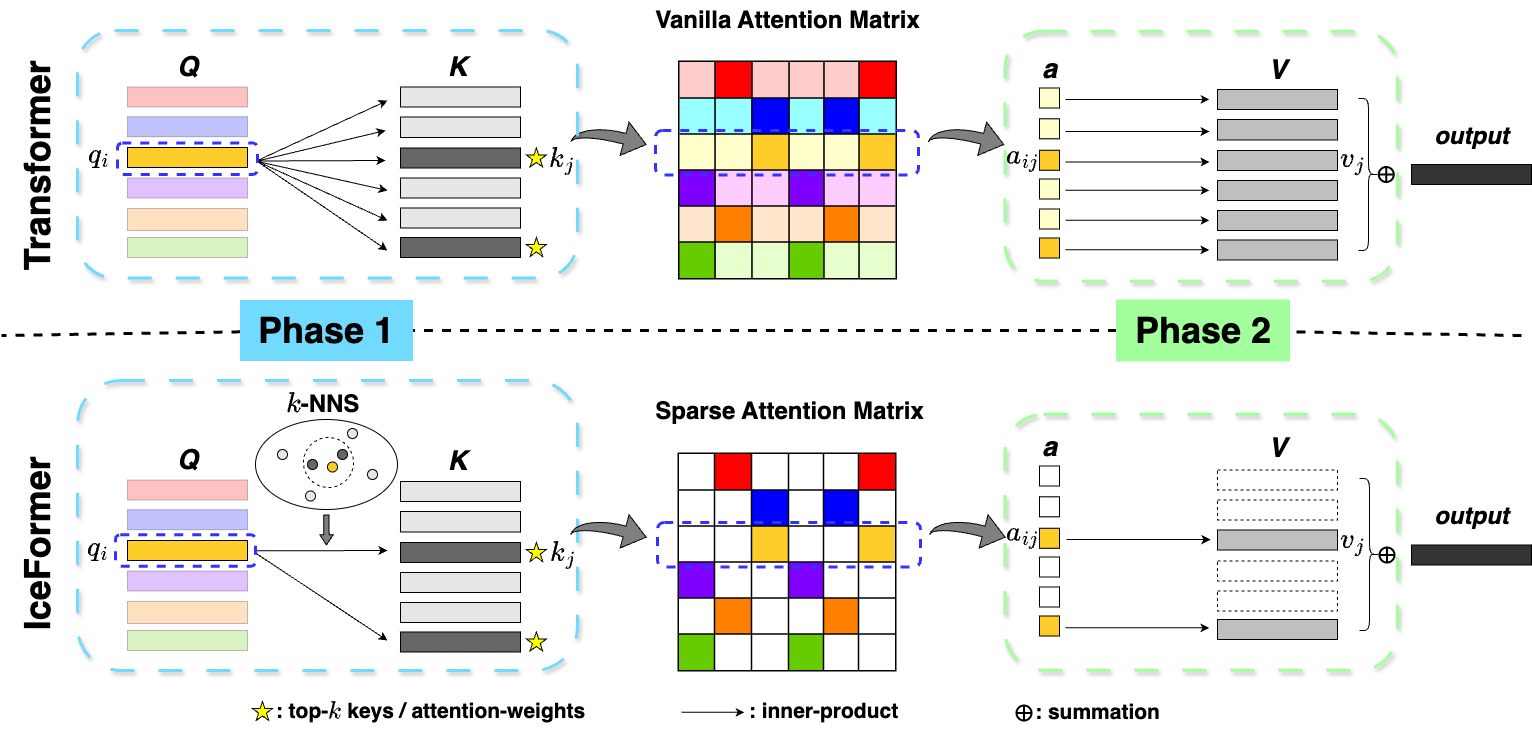
IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
Yuzhen Mao, Martin Ester, Ke Li
0
0
One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/.
5/7/2024