Accented Text-to-Speech Synthesis with a Conditional Variational Autoencoder
2211.03316
0
0
🌿
Abstract
Accent plays a significant role in speech communication, influencing one's capability to understand as well as conveying a person's identity. This paper introduces a novel and efficient framework for accented Text-to-Speech (TTS) synthesis based on a Conditional Variational Autoencoder. It has the ability to synthesize a selected speaker's voice, which is converted to any desired target accent. Our thorough experiments validate the effectiveness of the proposed framework using both objective and subjective evaluations. The results also show remarkable performance in terms of the ability to manipulate accents in the synthesized speech and provide a promising avenue for future accented TTS research.
Create account to get full access
Overview
- This paper introduces a new framework for synthesizing accented speech using a Conditional Variational Autoencoder.
- The framework can convert a speaker's voice to any desired target accent, enabling more flexible and customizable text-to-speech (TTS) synthesis.
- The researchers conducted thorough experiments to validate the effectiveness of the proposed framework using both objective and subjective evaluations.
- The results demonstrate the ability to manipulate accents in the synthesized speech, providing a promising avenue for future accented TTS research.
Plain English Explanation
The way a person speaks, including their accent, plays an important role in how we understand them and perceive their identity. This paper introduces a new approach to text-to-speech (TTS) synthesis that can convert a speaker's voice to any desired accent.
The researchers developed a Conditional Variational Autoencoder model that can take a speaker's voice and transform it to have a different accent. This allows for more flexibility in TTS systems, as the same speaker's voice can be used to produce speech in multiple accents.
The team extensively tested their framework, using both objective measures and subjective evaluations from human listeners. The results showed that the model was able to successfully manipulate the accent of the synthesized speech. This is an important advancement, as it opens up new possibilities for customizable and adaptable TTS systems that can better meet the needs of diverse users and applications.
Technical Explanation
The paper proposes a novel framework for accent conversion in text-to-speech (TTS) synthesis based on a Conditional Variational Autoencoder (CVAE). The CVAE model is trained to learn a latent representation of the speaker's voice, which can then be conditioned on a target accent to generate speech with the desired accent.
The researchers conducted thorough experiments to evaluate the effectiveness of their proposed framework. They used both objective measures, such as acoustic similarity and accent strength, as well as subjective evaluations from human listeners. The results demonstrated the model's ability to successfully manipulate the accent of the synthesized speech, achieving high performance on both objective and subjective metrics.
The paper's findings suggest that the proposed CVAE-based framework provides a promising approach for accented TTS synthesis, allowing for more flexible and customizable voice conversion capabilities. This could have important implications for various applications, such as assistive technologies, language learning, and personalized voice interfaces.
Critical Analysis
The paper presents a well-designed and thoroughly evaluated framework for accented TTS synthesis. The use of a CVAE model is a novel and effective approach, allowing for the disentanglement of speaker identity and accent characteristics. The extensive objective and subjective evaluations lend strong support to the effectiveness of the proposed method.
However, the paper does not address potential limitations or challenges of the approach. For example, it is unclear how the model would perform with a wider range of accents or how it would handle regional variations within a single accent. Additionally, the paper does not discuss the computational requirements or deployment considerations for the framework, which could be important for real-world applications.
It would also be valuable to see the researchers explore the potential for transfer learning or meta-learning techniques to further improve the model's ability to adapt to new speakers and accents. Investigating the interpretability of the learned latent representations could also provide valuable insights into the underlying mechanisms of accent conversion.
Overall, the paper presents a promising approach to accented TTS synthesis, but further research is needed to fully understand the capabilities and limitations of the proposed framework.
Conclusion
This paper introduces a novel and efficient framework for accented text-to-speech synthesis based on a Conditional Variational Autoencoder. The framework demonstrates the ability to convert a speaker's voice to any desired target accent, enabling more flexible and customizable TTS systems.
The extensive experiments conducted by the researchers validate the effectiveness of the proposed approach, showcasing its potential to manipulate accents in synthesized speech. This work represents an important advancement in the field of accented TTS, opening up new possibilities for personalized and adaptable voice interfaces that can better serve diverse user needs.
While the paper presents a promising solution, further research is needed to address potential limitations and explore additional capabilities, such as transfer learning and model interpretability. Nonetheless, this work provides a valuable foundation for future accented TTS research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Accent Conversion in Text-To-Speech Using Multi-Level VAE and Adversarial Training
Jan Melechovsky, Ambuj Mehrish, Berrak Sisman, Dorien Herremans
0
0
With rapid globalization, the need to build inclusive and representative speech technology cannot be overstated. Accent is an important aspect of speech that needs to be taken into consideration while building inclusive speech synthesizers. Inclusive speech technology aims to erase any biases towards specific groups, such as people of certain accent. We note that state-of-the-art Text-to-Speech (TTS) systems may currently not be suitable for all people, regardless of their background, as they are designed to generate high-quality voices without focusing on accent. In this paper, we propose a TTS model that utilizes a Multi-Level Variational Autoencoder with adversarial learning to address accented speech synthesis and conversion in TTS, with a vision for more inclusive systems in the future. We evaluate the performance through both objective metrics and subjective listening tests. The results show an improvement in accent conversion ability compared to the baseline.
6/4/2024
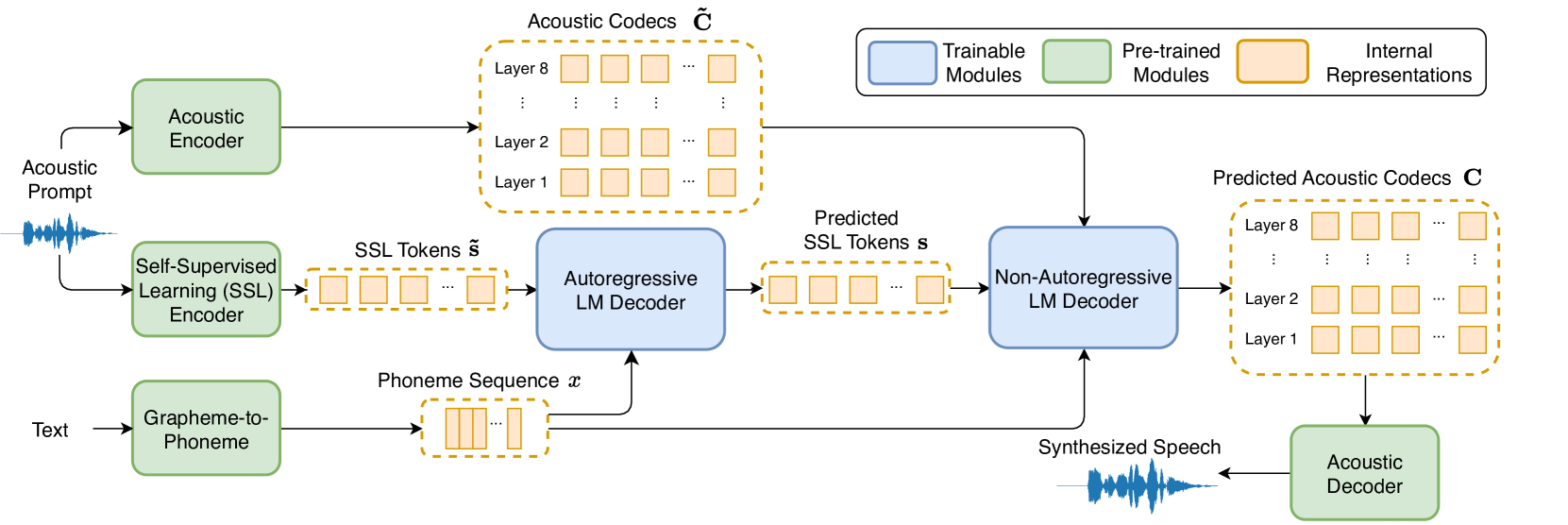
Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
Kun Zhou, Shengkui Zhao, Yukun Ma, Chong Zhang, Hao Wang, Dianwen Ng, Chongjia Ni, Nguyen Trung Hieu, Jia Qi Yip, Bin Ma
0
0
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
6/13/2024
🖼️
Expressive paragraph text-to-speech synthesis with multi-step variational autoencoder
Xuyuan Li, Zengqiang Shang, Peiyang Shi, Hua Hua, Ta Li, Pengyuan Zhang
0
0
Neural networks have been able to generate high-quality single-sentence speech. However, it remains a challenge concerning audio-book speech synthesis due to the intra-paragraph correlation of semantic and acoustic features as well as variable styles. In this paper, we propose a highly expressive paragraph speech synthesis system with a multi-step variational autoencoder, called EP-MSTTS. EP-MSTTS is the first VITS-based paragraph speech synthesis model and models the variable style of paragraph speech at five levels: frame, phoneme, word, sentence, and paragraph. We also propose a series of improvements to enhance the performance of this hierarchical model. In addition, we directly train EP-MSTTS on speech sliced by paragraph rather than sentence. Experiment results on the single-speaker French audiobook corpus released at Blizzard Challenge 2023 show EP-MSTTS obtains better performance than baseline models.
6/12/2024
📈
Non-autoregressive real-time Accent Conversion model with voice cloning
Vladimir Nechaev, Sergey Kosyakov
0
0
Currently, the development of Foreign Accent Conversion (FAC) models utilizes deep neural network architectures, as well as ensembles of neural networks for speech recognition and speech generation. The use of these models is limited by architectural features, which does not allow flexible changes in the timbre of the generated speech and requires the accumulation of context, leading to increased delays in generation and makes these systems unsuitable for use in real-time multi-user communication scenarios. We have developed the non-autoregressive model for real-time accent conversion with voice cloning. The model generates native-sounding L1 speech with minimal latency based on input L2 accented speech. The model consists of interconnected modules for extracting accent, gender, and speaker embeddings, converting speech, generating spectrograms, and decoding the resulting spectrogram into an audio signal. The model has the ability to save, clone and change the timbre, gender and accent of the speaker's voice in real time. The results of the objective assessment show that the model improves speech quality, leading to enhanced recognition performance in existing ASR systems. The results of subjective tests show that the proposed accent and gender encoder improves the generation quality. The developed model demonstrates high-quality low-latency accent conversion, voice cloning, and speech enhancement capabilities, making it suitable for real-time multi-user communication scenarios.
5/24/2024