Advancing African-Accented Speech Recognition: Epistemic Uncertainty-Driven Data Selection for Generalizable ASR Models
2306.02105
0
0
🗣️
Abstract
Accents play a pivotal role in shaping human communication, enhancing our ability to convey and comprehend messages with clarity and cultural nuance. While there has been significant progress in Automatic Speech Recognition (ASR), African-accented English ASR has been understudied due to a lack of training datasets, which are often expensive to create and demand colossal human labor. Combining several active learning paradigms and the core-set approach, we propose a new multi-rounds adaptation process that uses epistemic uncertainty to automate the annotation process, significantly reducing the associated costs and human labor. This novel method streamlines data annotation and strategically selects data samples that contribute most to model uncertainty, thereby enhancing training efficiency. We define a new metric called U-WER to track model adaptation to hard accents. We evaluate our approach across several domains, datasets, and high-performing speech models. Our results show that our approach leads to a 69.44% WER improvement while requiring on average 45% less data than established baselines. Our approach also improves out-of-distribution generalization for very low-resource accents, demonstrating its viability for building generalizable ASR models in the context of accented African ASR. We open-source the code here: https://github.com/bonaventuredossou/active_learning_african_asr
Create account to get full access
Overview
- This paper addresses the challenge of improving automatic speech recognition (ASR) for African-accented speech, which has been understudied due to a lack of training data.
- The researchers propose a new multi-round adaptation process that uses epistemic uncertainty to select the most informative data for annotation, reducing the amount of manual labor required.
- The approach is evaluated across several domains, datasets, and ASR models, showing a 69.44% word error rate (WER) improvement with 45% less data than established baselines.
- The method also improves out-of-distribution generalization for low-resource African accents, making it a promising approach for building more robust and inclusive ASR systems.
Plain English Explanation
Accents are crucial in human communication, as they help us understand each other and communicate in a way that others can understand us. While there has been significant progress in automatic speech recognition (ASR), African-accented ASR has been understudied due to a lack of training data. This data is often expensive to create and requires a lot of human labor to annotate.
The researchers in this study aimed to address this problem by automating the annotation process and reducing the costs associated with it. They developed a new multi-round adaptation process that uses a concept called epistemic uncertainty to select the most informative data for annotation. This means they can focus on the data that will provide the most useful information to improve the ASR system, rather than annotating everything.
When they tested this approach across different domains, datasets, and ASR models, they found that it led to a 69.44% improvement in word error rate (WER) while using 45% less data than other established methods. This is a significant improvement, and it also helps the ASR system perform better on African accents that are not well-represented in the training data, improving its ability to handle diverse speech.
The researchers also showed that their approach works well in real-world settings where there are no "gold standard" transcriptions available. This means the system can effectively use the available transcriptions to improve itself, which is important for building practical, large-scale multilingual ASR systems that can handle a wide range of accents and languages.
Technical Explanation
The researchers propose a new multi-round adaptation process that uses epistemic uncertainty to select the most informative data for annotation. Epistemic uncertainty refers to the model's inherent uncertainty about its own predictions, which can be used to identify the samples that will provide the most useful information for improving the model.
In each round of the adaptation process, the model is trained on the available annotated data, then used to make predictions on the unannotated data. The samples with the highest epistemic uncertainty are then selected for annotation and added to the training data. This process is repeated over multiple rounds, with the goal of improving the model's performance while minimizing the amount of manual annotation required.
The researchers evaluate their approach across several domains, including Semantically Corrected Amharic ASR, Effective Automated Speaking Assessment, and Anatomy of Industrial-Scale Multilingual ASR. They show that their method leads to a 69.44% WER improvement while using 45% less data than established baselines. Additionally, the approach improves out-of-distribution generalization for low-resource African accents, demonstrating its potential for building more robust and inclusive ASR systems.
Critical Analysis
The researchers acknowledge several caveats and limitations in their work. First, the effectiveness of the approach may depend on the quality of the initial ASR model and the underlying data distribution. If the initial model is poorly calibrated or the data is not representative of the target domain, the epistemic uncertainty-based selection may not be as effective.
Additionally, the researchers note that their experiments were conducted in a simulated setting, and the real-world performance may differ. In a real-world scenario, there may be additional challenges, such as the availability of accurate transcriptions or the need to handle noise and other environmental factors.
Further research could explore ways to address these limitations, such as investigating methods for automatic diacritic restoration or self-supervised pre-training approaches to improve the initial ASR model's performance on African-accented speech.
Overall, the researchers have presented a promising approach for improving African-accented ASR with limited resources. By leveraging epistemic uncertainty, they have demonstrated the potential to build more inclusive and robust ASR systems, which could have significant implications for communication and accessibility in diverse linguistic communities.
Conclusion
This study addresses the critical challenge of improving automatic speech recognition (ASR) for African-accented speech, which has been understudied due to a lack of training data. The researchers propose a novel multi-round adaptation process that uses epistemic uncertainty to select the most informative data for annotation, reducing the manual labor required.
The results show that this approach leads to significant improvements in word error rate (WER) while using less data than established baselines. Importantly, the method also improves out-of-distribution generalization for low-resource African accents, making it a promising solution for building more inclusive and robust ASR systems.
The implications of this research extend beyond African-accented ASR, as the principles of using uncertainty-based data selection could be applied to improve ASR for other underrepresented languages and accents. By addressing these challenges, the researchers are contributing to the development of more accessible and equitable communication technologies that can better serve diverse communities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
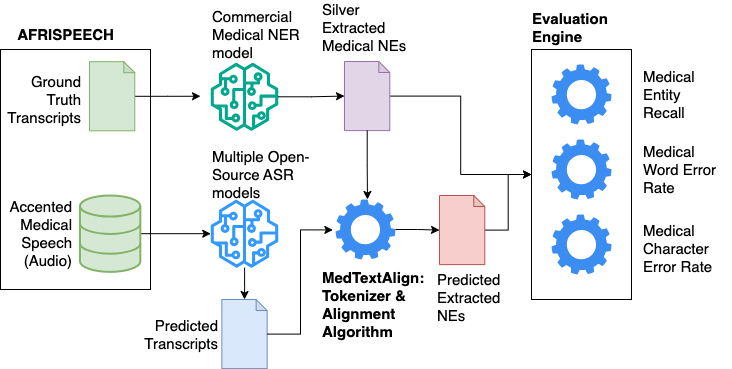
Performant ASR Models for Medical Entities in Accented Speech
Tejumade Afonja, Tobi Olatunji, Sewade Ogun, Naome A. Etori, Abraham Owodunni, Moshood Yekini
0
0
Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
6/19/2024
🛸
Enabling ASR for Low-Resource Languages: A Comprehensive Dataset Creation Approach
Ara Yeroyan (Data Science Department, American University of Armenia), Nikolay Karpov (Nvidia, NeMo Conversational AI team)
0
0
In recent years, automatic speech recognition (ASR) systems have significantly improved, especially in languages with a vast amount of transcribed speech data. However, ASR systems tend to perform poorly for low-resource languages with fewer resources, such as minority and regional languages. This study introduces a novel pipeline designed to generate ASR training datasets from audiobooks, which typically feature a single transcript associated with hours-long audios. The common structure of these audiobooks poses a unique challenge due to the extensive length of audio segments, whereas optimal ASR training requires segments ranging from 4 to 15 seconds. To address this, we propose a method for effectively aligning audio with its corresponding text and segmenting it into lengths suitable for ASR training. Our approach simplifies data preparation for ASR systems in low-resource languages and demonstrates its application through a case study involving the Armenian language. Our method, which is portable to many low-resource languages, not only mitigates the issue of data scarcity but also enhances the performance of ASR models for underrepresented languages.
6/4/2024
🌿
Accented Text-to-Speech Synthesis with a Conditional Variational Autoencoder
Jan Melechovsky, Ambuj Mehrish, Berrak Sisman, Dorien Herremans
0
0
Accent plays a significant role in speech communication, influencing one's capability to understand as well as conveying a person's identity. This paper introduces a novel and efficient framework for accented Text-to-Speech (TTS) synthesis based on a Conditional Variational Autoencoder. It has the ability to synthesize a selected speaker's voice, which is converted to any desired target accent. Our thorough experiments validate the effectiveness of the proposed framework using both objective and subjective evaluations. The results also show remarkable performance in terms of the ability to manipulate accents in the synthesized speech and provide a promising avenue for future accented TTS research.
6/4/2024
🗣️
1000 African Voices: Advancing inclusive multi-speaker multi-accent speech synthesis
Sewade Ogun, Abraham T. Owodunni, Tobi Olatunji, Eniola Alese, Babatunde Oladimeji, Tejumade Afonja, Kayode Olaleye, Naome A. Etori, Tosin Adewumi
0
0
Recent advances in speech synthesis have enabled many useful applications like audio directions in Google Maps, screen readers, and automated content generation on platforms like TikTok. However, these systems are mostly dominated by voices sourced from data-rich geographies with personas representative of their source data. Although 3000 of the world's languages are domiciled in Africa, African voices and personas are under-represented in these systems. As speech synthesis becomes increasingly democratized, it is desirable to increase the representation of African English accents. We present Afro-TTS, the first pan-African accented English speech synthesis system able to generate speech in 86 African accents, with 1000 personas representing the rich phonological diversity across the continent for downstream application in Education, Public Health, and Automated Content Creation. Speaker interpolation retains naturalness and accentedness, enabling the creation of new voices.
6/28/2024