Phonetic Enhanced Language Modeling for Text-to-Speech Synthesis
2406.02009
0
0
Abstract
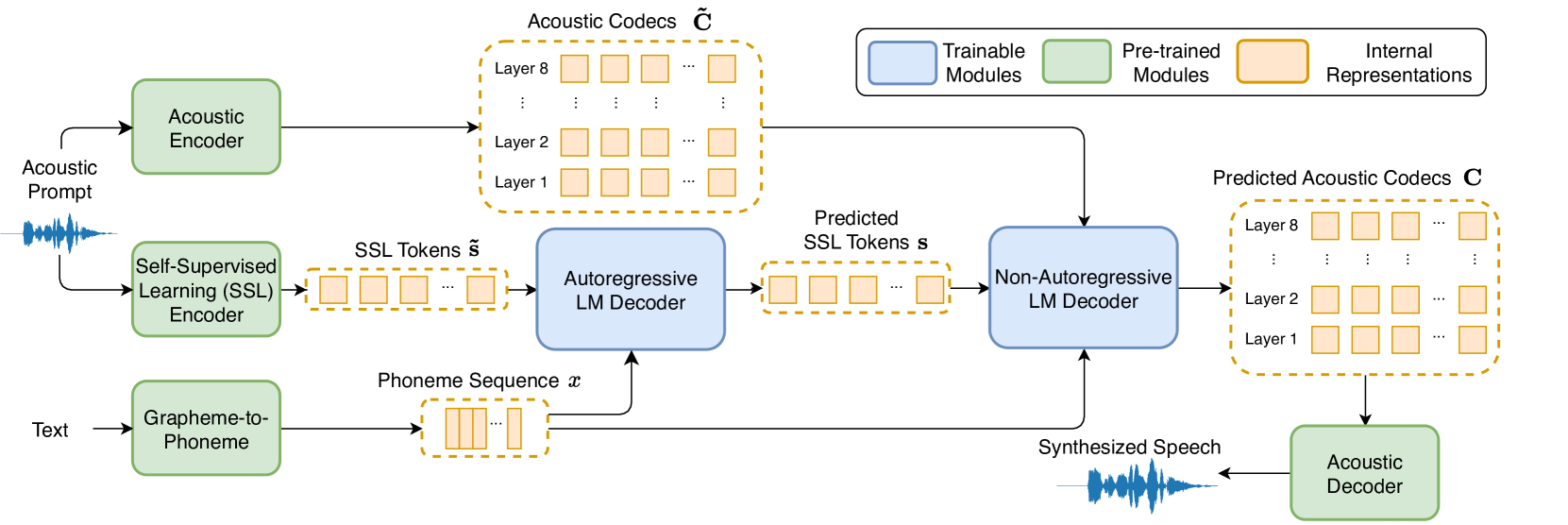
Recent language model-based text-to-speech (TTS) frameworks demonstrate scalability and in-context learning capabilities. However, they suffer from robustness issues due to the accumulation of errors in speech unit predictions during autoregressive language modeling. In this paper, we propose a phonetic enhanced language modeling method to improve the performance of TTS models. We leverage self-supervised representations that are phonetically rich as the training target for the autoregressive language model. Subsequently, a non-autoregressive model is employed to predict discrete acoustic codecs that contain fine-grained acoustic details. The TTS model focuses solely on linguistic modeling during autoregressive training, thereby reducing the error propagation that occurs in non-autoregressive training. Both objective and subjective evaluations validate the effectiveness of our proposed method.
Create account to get full access
Overview
- This research paper explores a novel approach to text-to-speech (TTS) synthesis that incorporates phonetic information into language modeling.
- The goal is to improve the naturalness and intelligibility of TTS systems by leveraging phonetic cues, which can be particularly helpful for synthesizing accented or non-standard speech.
- The authors propose a "Phonetic Enhanced Language Model" (PELM) that integrates phonetic knowledge into the language model, allowing it to better capture the relationship between text and speech.
Plain English Explanation
The paper describes a way to make text-to-speech systems sound more natural and easy to understand, especially for accented or non-standard speech. Accented text-to-speech synthesis and improving language model-based zero-shot text-to-speech are two related areas of research.
The key idea is to incorporate information about how words are pronounced (their "phonetics") into the language model used by the text-to-speech system. This helps the system better understand the connection between written text and the way it should be spoken aloud. For example, the language model can learn that certain letter combinations are pronounced differently in different accents.
By combining language modeling and phonetic knowledge, the researchers aim to create text-to-speech that sounds more natural and authentic, even for speakers with diverse linguistic backgrounds. This could be particularly helpful for improving language model-based zero-shot text-to-speech or CLAM-TTS: Improving neural codec language model, where the system needs to generate speech for languages or accents it hasn't been explicitly trained on.
Technical Explanation
The paper proposes a "Phonetic Enhanced Language Model" (PELM) that integrates phonetic information into a neural language model for text-to-speech synthesis. The PELM is trained on both text and corresponding phonetic transcriptions, allowing it to learn the relationship between written words and their pronunciations.
During text-to-speech generation, the PELM is used to predict not only the next word, but also the associated phonetic sequence. This phonetic information is then fed into a speech synthesis model to produce the final audio output.
The authors evaluate their approach on several text-to-speech benchmarks, including a dataset with non-native English speakers. They find that the PELM-based system outperforms traditional language model-based TTS in terms of naturalness and intelligibility, particularly for accented or non-standard speech. The Evaluating Text-to-Speech Synthesis from Large Language Models paper provides a relevant context for understanding the importance of this research.
Critical Analysis
The paper presents a compelling approach to improving text-to-speech synthesis by incorporating phonetic knowledge into the language model. However, there are a few potential limitations and areas for further research:
- The PELM is trained on phonetic transcriptions, which may not be readily available for all languages and accents. Exploring ways to learn phonetic representations without relying on manual transcriptions could expand the approach's applicability.
- The evaluation focuses on English text-to-speech, and it's unclear how well the PELM would generalize to other languages with different phonological structures. TIPAA: SSL for text-independent phone-to-audio suggests that cross-lingual phonetic modeling could be a valuable direction.
- The paper does not discuss the computational overhead or inference latency of the PELM-based TTS system compared to traditional approaches. Understanding the practical tradeoffs would be important for real-world deployment.
Overall, the research presents a promising direction for enhancing text-to-speech synthesis by leveraging phonetic information, but further investigation into the approach's scalability and generalization is warranted.
Conclusion
This paper introduces a "Phonetic Enhanced Language Model" (PELM) that integrates phonetic knowledge into language modeling to improve the naturalness and intelligibility of text-to-speech synthesis, particularly for accented or non-standard speech. By capturing the relationship between written text and speech sounds, the PELM-based TTS system outperforms traditional language model-based approaches.
The proposed approach represents a significant step forward in enhancing the quality and versatility of text-to-speech systems, which have widespread applications in accessibility, user interfaces, and voice-based interactions. Further research is needed to explore the scalability and generalization of the PELM, but this work demonstrates the value of incorporating phonetic information into language modeling for advanced TTS capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Trung Dang, David Aponte, Dung Tran, Kazuhito Koishida
0
0
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
6/11/2024
🌿
Accented Text-to-Speech Synthesis with a Conditional Variational Autoencoder
Jan Melechovsky, Ambuj Mehrish, Berrak Sisman, Dorien Herremans
0
0
Accent plays a significant role in speech communication, influencing one's capability to understand as well as conveying a person's identity. This paper introduces a novel and efficient framework for accented Text-to-Speech (TTS) synthesis based on a Conditional Variational Autoencoder. It has the ability to synthesize a selected speaker's voice, which is converted to any desired target accent. Our thorough experiments validate the effectiveness of the proposed framework using both objective and subjective evaluations. The results also show remarkable performance in terms of the ability to manipulate accents in the synthesized speech and provide a promising avenue for future accented TTS research.
6/4/2024
🗣️
Enhancing CTC-based speech recognition with diverse modeling units
Shiyi Han, Zhihong Lei, Mingbin Xu, Xingyu Na, Zhen Huang
0
0
In recent years, the evolution of end-to-end (E2E) automatic speech recognition (ASR) models has been remarkable, largely due to advances in deep learning architectures like transformer. On top of E2E systems, researchers have achieved substantial accuracy improvement by rescoring E2E model's N-best hypotheses with a phoneme-based model. This raises an interesting question about where the improvements come from other than the system combination effect. We examine the underlying mechanisms driving these gains and propose an efficient joint training approach, where E2E models are trained jointly with diverse modeling units. This methodology does not only align the strengths of both phoneme and grapheme-based models but also reveals that using these diverse modeling units in a synergistic way can significantly enhance model accuracy. Our findings offer new insights into the optimal integration of heterogeneous modeling units in the development of more robust and accurate ASR systems.
6/12/2024

A Non-autoregressive Generation Framework for End-to-End Simultaneous Speech-to-Any Translation
Zhengrui Ma, Qingkai Fang, Shaolei Zhang, Shoutao Guo, Yang Feng, Min Zhang
0
0
Simultaneous translation models play a crucial role in facilitating communication. However, existing research primarily focuses on text-to-text or speech-to-text models, necessitating additional cascade components to achieve speech-to-speech translation. These pipeline methods suffer from error propagation and accumulate delays in each cascade component, resulting in reduced synchronization between the speaker and listener. To overcome these challenges, we propose a novel non-autoregressive generation framework for simultaneous speech translation (NAST-S2X), which integrates speech-to-text and speech-to-speech tasks into a unified end-to-end framework. We develop a non-autoregressive decoder capable of concurrently generating multiple text or acoustic unit tokens upon receiving fixed-length speech chunks. The decoder can generate blank or repeated tokens and employ CTC decoding to dynamically adjust its latency. Experimental results show that NAST-S2X outperforms state-of-the-art models in both speech-to-text and speech-to-speech tasks. It achieves high-quality simultaneous interpretation within a delay of less than 3 seconds and provides a 28 times decoding speedup in offline generation.
6/12/2024